【PaddlePaddle飞桨复现论文】——(论文阅读)U-GAT-IT:基于自适应层实例归一化的无监督生成注意力网络用于图像到图像的转换
本文为百度论文复现营论文阅读心得。
非常感谢百度提供的学习资源,论文复现课程链接为:https://aistudio.baidu.com/aistudio/education/group/info/1340
本人对U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation这篇论文比较感兴趣,因此选择这篇论文进行复现。
- 论文下载链接:https://arxiv.org/pdf/1907.10830.pdf
- 论文pytorch版代码链接:https://github.com/znxlwm/UGATIT-pytorch

1 主要工作
- 通过无监督方式实现两个图像域间纹理和像差別很大时的风格转换
- 实现了相同的网络结构和超参数同时进行需要保持 shapes的图像翻译(例 horse2zebra)和需要改变 shape的图像翻译任务(例cat2dog)
2 模型结构

3 创新点
- 提出了一种无监督的图像到图像翻译的新方法,以端到端的方式结合了新的注意力模块和新的自适应标准化功能。
- 提出了自适应层实例归一化(AdaLIN),其参数可以在训练期间通过自适应选择实例归一化(Instance normalization,IN)和层归一化(Layer Normalization,LN)之间的比率从数据集中学习得到。
- 利用 attention模块(添加辅助分类器),增强生成器的生成能力,更好的区分源域和目标域;以及判别器的判别能力,更好的区分生成图像和原始图像
3.1 AdaLIN:自适应层实例归一化
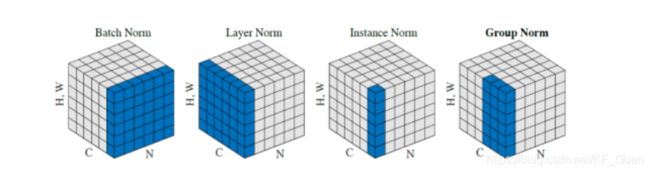
- IN进一步局限到单个channel之间,而LN则跨过所有channels。因此,IN假设不同feature的不同channels之间是无关的(uncorrelated),因此单独作用于每个channel可能会引入对原来的语义(semantic content)的干扰;
- LN尽管是对所有channels作权衡,但考虑到normalization的本质还是“平滑”,容易抹消一些语义信息。
作者把两者结合起来,互相抵消他们之间的不足,同时又结合了两者的优点:
a ^ I = a − μ I σ I 2 + ϵ , a ^ L = a − μ L σ L 2 + ϵ \hat{a}_{I}=\frac{a-\mu_{I}}{\sqrt{\sigma_{I}^{2}+\epsilon}}, \hat{a}_{L}=\frac{a-\mu_{L}}{\sqrt{\sigma_{L}^{2}+\epsilon}} a^I=σI2+ϵa−μI,a^L=σL2+ϵa−μL
上面是IN和LN的归一化公式,然后将 a ^ I \hat{a}_{I} a^I和 a ^ L \hat{a}_{L} a^L代入到进行合并( γ \gamma γ和 β \beta β通过外部传入):
a ^ I = a − μ I σ I 2 + ϵ , a ^ L = a − μ L σ L 2 + ϵ AdaLIN ( a , γ , β ) = γ ⋅ ( ρ ⋅ a ^ I + ( 1 − ρ ) ⋅ a ^ L ) + β \hat{a}_{I}=\frac{a-\mu_{I}}{\sqrt{\sigma_{I}^{2}+\epsilon}}, \hat{a}_{L}=\frac{a-\mu_{L}}{\sqrt{\sigma_{L}^{2}+\epsilon}}\operatorname{AdaLIN}(a, \gamma, \beta)=\gamma \cdot\left(\rho \cdot \hat{a}_{I}+(1-\rho) \cdot \hat{a}_{L}\right)+\beta a^I=σI2+ϵa−μI,a^L=σL2+ϵa−μLAdaLIN(a,γ,β)=γ⋅(ρ⋅a^I+(1−ρ)⋅a^L)+β
为了防止 ρ \rho ρ超出 [0,1]范围,对 ρ \rho ρ进行了区间裁剪:
ρ ← clip [ 0 , 1 ] ( ρ − τ Δ ρ ) \rho \leftarrow \operatorname{clip}[0,1](\rho-\tau \Delta \rho) ρ←clip[0,1](ρ−τΔρ)其中, τ \tau τ是学习率。
AdaIN能很好的将内容特征转移到样式特征上,但AdaIN假设特征通道之间不相关,意味着样式特征需要包括很多的内容模式,而LN则没有这个假设,但LN不能保持原始域的内容结构,因为LN考虑的是全局统计信息,所以作者将AdaIN和LN结合起来,结合两者的优势,有选择地保留或改变内容信息,有助于解决广泛的图像到图像的翻译问题。
3.2 attention模块
attention模块结合模型来理解,可以解释为什么attention模块这么强大。
(1)生成器Generator
我所理解的过程如下图:

- 首先,源域图像与目标域图像经过编码器 E s E_s Es(包含下采样和残差块)得到编码后的特征图Encoder Feature map;
- 特征图往上经过辅助分类器 η s \eta_{s} ηs分类(二分类,判断是源域: 0还是目标域: 1),利用 η s \eta_{s} ηs的权重和特征图Encoder Feature map做attention操作,得到attention focused on后的feature: a s k = w s k E s k , k = 1 , 2 , … , n a_{s}^{k}=w_{s}^{k} E_{s}^{k}, \quad k=1,2, \ldots, n ask=wskEsk,k=1,2,…,n
- 之后,图中黄色的activation map往上继续前馈,再次经过fc,预测2c个参数(c个 γ \gamma γ和c个 β \beta β)用于将特征做AdaLIN正则化。
- AdaLIN正则化过程见3.1的公式。
- 最后,将正则化后feature继续前馈,经过残差和上采样,得到输出。
由于 γ \gamma γ和 β \beta β是从activation map得到的,而 γ \gamma γ和 β \beta β由于正则化有关系,正则化IN可以考虑强化content,LN可以综合全局,即:
attn { w s i } ⇒ a ⇒ γ , β ⇒ AdaLIN ⇒ { content info global correlation \operatorname{attn}\left\{w_{s}^{i}\right\} \Rightarrow a \Rightarrow \gamma, \beta \Rightarrow \operatorname{AdaLIN} \Rightarrow\left\{\begin{array}{c} \text { content info } \\ \text { global correlation } \end{array}\right. attn{wsi}⇒a⇒γ,β⇒AdaLIN⇒{ content info global correlation
因此,所有一切都被串联在一起。通过BP学习,attn能够更好的关注在源域与目标差异所在的区域,所以U-GAT-IT模型的attention模块这么强大。
(2)判别器Discriminator
同样,生成器也包含了编码器、解码器(分类器)和辅助分类器用于生成attn,结构如下:

由于其过程与生成器类似,在这里不赘述了。
参考:
https://github.com/FangYang970206/PaperNote/blob/master/GAN/UGATIT.md
https://aistudio.baidu.com/aistudio/education/lessonvideo/521680
https://blog.csdn.net/WinerChopin/article/details/99093743