编译器----词法分析
本文通过学习王博俊、张宇的《DIY Compiler and Linker》 ,实现词法分析器,一方面作为自己的学习笔记,一方面也作与大家分享与交流
代码下载地址
词法分析的任务
源程序由字符序列构成,词法分析器扫描源程序字符串,根据语言的词法规则分析并识别具有独立意义的最小语法单位:单词(包括关键字、运算符、标识符等),并以某种编码形式输出。
词法分析流程图
这次实现的词法分析器完全按照下图所编写:
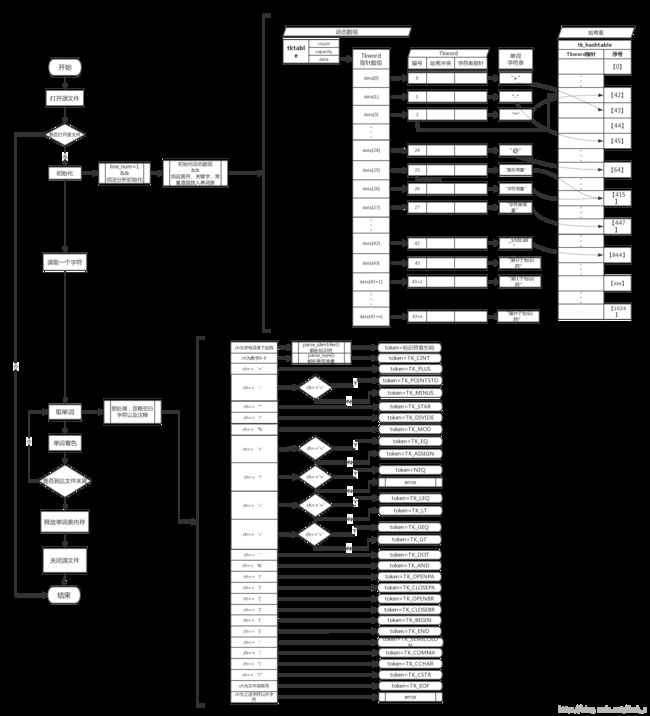
从图中可以看到
1. 先打开源文件,如果无法打开则异常退出
2. 打开源文件后进行初始化,标致行号为第一行,再初始化动态数组,并把运算符、关键字、常量直接放入单词表(单词表是由动态数组和哈希表一起组成的复合结构)
3. 开始读取一个字符,并从第一个字符开始进行“取单词”的工作,如果遇到空白字符或者注释则忽略,如果是有效字符则判断这一单词并给出编号或者标识符索引码
4. 为了能显示出来我们的词法分析,对不同类别的单词进行着色输出到我们屏幕上
5. 循环往复第3、4步直到文件末尾,关闭文件,正常结束
实现词法分析器
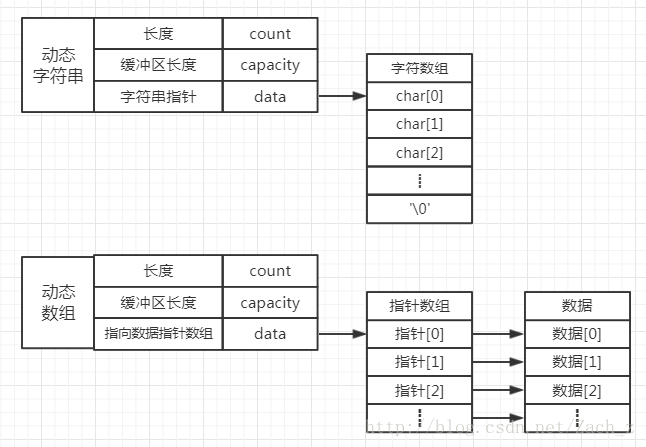
1. 自定义动态字符串和动态数组
自定义动态字符串和动态数组是词法分析需要用到的数据结构
- 首先,常量字符串的长度没办法预知,可能是空串,也可能很长,则需要动态字符串来存储
- 其次,单词的个数也无法预知,可能只有一个单词,也可能有许多,对于单词的存储,也需要一个按需分配的动态数组
词法分析器是用C语言写的,需要自定义动态字符串和动态数组
1.1 动态字符串
dynstring.h(实际上放在头文件lexical_analysis.h):
/*动态字符串定义*/
typedef struct DynString
{
int count; //字符串长度
int capacity; //包含该字符串的缓冲区长度
char *data; //指向字符串的指针
}DynString;
void dynstring_init(DynString *pstr, int initsize);//初始化动态字符串存储容量,用于dynstring_reset()
void dynstring_free(DynString *pstr);//释放动态字符串使用的内存空间,用于dynstring_reset()
void dynstring_realloc(DynString *cstr, int new_size);//重新分配字符串容量
void dynstring_chcat(DynString *cstr, int ch);//字符串中添加字符
void dynstring_reset(DynString *cstr);//重置动态字符串dynstring.c:
#include "lexical_analysis.h"
/***********************************************************
* 功能: 初始化动态字符串储存容量
* pstr: 动态字符串指针
* initsize: 字符串初始化分配空间
**********************************************************/
void dynstring_init(DynString *pstr, int initsize)
{
if (pstr != NULL)
{
pstr->data = (char *)malloc(sizeof(char) * initsize);
pstr->count = 0;
pstr->capacity = initsize;
}
}
/***********************************************************
* 功能: 释放动态字符串使用的内存空间
* pstr: 动态字符串指针
**********************************************************/
void dynstring_free(DynString *pstr)
{
if (pstr != NULL)
{
if (pstr->data) free(pstr->data);
pstr->count = 0;
pstr->capacity = 0;
}
}
/***********************************************************
* 功能: 重置动态字符串,先释放,重新初始化
* pstr: 动态字符串指针
**********************************************************/
void dynstring_reset(DynString *pstr)
{
dynstring_free(pstr);
dynstring_init(pstr, 10);//初始化字符串分配10个字节空间
}
/***********************************************************
* 功能: 重新分配字符串容量
* pstr: 动态字符串指针
* new_size: 字符串新长度
**********************************************************/
void dynstring_realloc(DynString *pstr, int new_size)
{
int capacity;
char *data;
capacity = pstr->capacity;
while (capacity < new_size)
{
capacity *= 2;//本来分配空间扩大一倍
}
data = (char *)realloc(pstr->data, capacity);
if (!data)//realloc 返回NULL 即分配失败
error("内存分配失败");
pstr->capacity = capacity;
pstr->data = data;
}
/***********************************************************
* 功能: 追加单个字符到动态字符串对象
* pstr: 动态字符串指针
* ch: 所要追加的字符
**********************************************************/
void dynstring_chcat(DynString *pstr, int ch)
{
int count;
count = pstr->count + 1;
if (count > pstr->capacity)
dynstring_realloc(pstr, count);
pstr->data[count - 1] = ch;
pstr->count = count;
}
1.2 动态数组
dynarray.h(实际上放在头文件lexical_analysis.h):
/*动态数组定义*/
typedef struct DynArray
{
int count;//动态数组元素个数
int capacity;//动态数组缓冲区长度
void **data;//指向数据指针的数组
}DynArray;
void dynarray_realloc(DynArray *parr, int new_size);//重新分配动态数组容量,用于dynarray_add()函数
void dynarray_add(DynArray *parr, void *data);//追加动态数组元素
void dynarray_init(DynArray *parr, int initsize);//初始化动态数组存储容量
void dynarray_free(DynArray *parr);//释放动态数组使用的内存空间
int dynarray_search(DynArray *parr, int key);//动态数组元素查找dynarray.c:
#include "lexical_analysis.h"
/***********************************************************
* 功能: 初始化动态数组储存容量
* parr: 动态数组指针
* initsize: 动态数组初始化分配空间
**********************************************************/
void dynarray_init(DynArray *parr, int initsize)
{
if (parr != NULL)
{
parr->data = (void **)malloc(sizeof(void*) * initsize);
parr->count = 0;
parr->capacity = initsize;
}
}
/***********************************************************
* 功能: 释放动态数组使用的内存空间
* parr: 动态数组指针
**********************************************************/
void dynarray_free(DynArray *parr)
{
void **p;
for (p = parr->data; parr->count; ++p, --parr->count)
{
if (*p)
free(*p);
}
free(parr->data);
parr->data = NULL;
}
/***********************************************************
* 功能: 重新分配动态数组容量
* parr: 动态数组指针
* new_size: 动态数组最新元素个数
**********************************************************/
void dynarray_realloc(DynArray *parr, int new_size)
{
int capacity;
void *data;
capacity = parr->capacity;
while (capacity < new_size)
capacity *= 2;
data = realloc(parr->data, capacity);
if (!data)
error("内存分配失败");
parr->capacity = capacity;
parr->data = (void **)data;
}
/***********************************************************
* 功能: 追加动态数组元素
* parr: 动态数组指针
* data: 所要追加的新元素
**********************************************************/
void dynarray_add(DynArray *parr, void *data)
{
int count;
count = parr->count + 1;
if (count * sizeof(void*) > parr->capacity)
dynarray_realloc(parr, count * sizeof(void*));
parr->data[count - 1] = data;
parr->count = count;
}
/***********************************************************
* 功能: 动态数组元素查找
* parr: 动态数组指针
* key: 要查找的元素
**********************************************************/
int dynarray_search(DynArray *parr, int key)
{
int i;
int **p;
p = (int **)parr->data;
for (i = 0; i < parr->count; ++i, p++)
{
if (key == **p)
return i;
}
return -1;
}
1.3 动态字符串与动态数组存储结构图
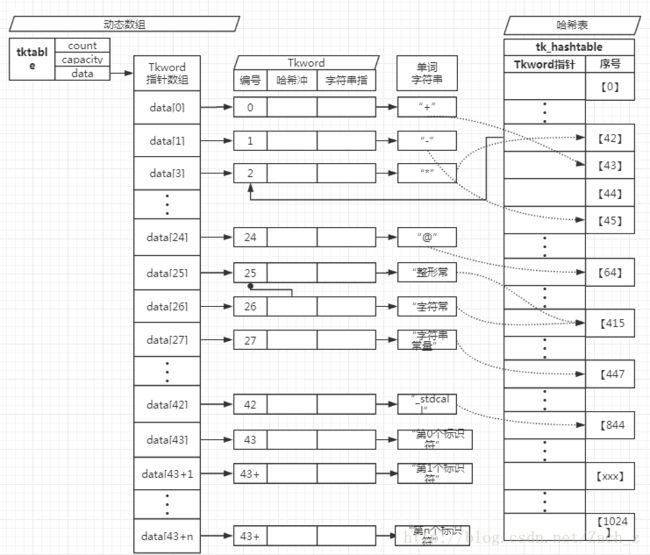
2. 单词表
单词表由动态数组和哈希表两部分构成
2.1 哈希表
单词表中步存储重复的单词,每遇到一个单词就遍历去单词表中查找效率很低,因此需要哈希表
这里使用ELF字符串哈希值计算
ELFhash—字符串哈希算法解释
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);
if ((x=hash & 0xf0000000)!=0)
hash ^= x >> 24;
hash &= ~x;
}
return (hash & 0x7fffffff);
}2.2 单词表实现
tkword.h(实际上放在头文件lexical_analysis.h):
/*单词存储结构定义*/
typedef struct TkWord
{
int tkcode;//单词编码
struct TkWord *next; //指向哈希冲突的同义词
char *spelling; //单词字符串
}TkWord;
int ELFHash(char *str);//计算哈希地址
TkWord* tkword_direct_insert(TkWord* tp);//将运算符、关键字、常量直接放入单词表
TkWord* tkword_find(char *p, int keyno);//在单词表中查找单词,用于tkword_insert()
void *mallocz(int size);//分配堆内存并将数据初始化为'0',用于tkword_insert()
TkWord* tkword_insert(char *p);//标识符插入单词表,先查找,查找不到再插入单词表tkword.c:
#include "lexical_analysis.h"
TkWord* tk_hashtable[MAXKEY]; // 单词哈希表
DynArray tktable; // 单词表
/***********************************************************
* 功能: 计算哈希地址
* key:哈希关键字
* MAXKEY:哈希表长度
**********************************************************/
int ELFHash(char *str)
{
int hash = 0;
int x = 0;
while (*str)
{
hash = (hash << 4) + *str++;
x = hash & 0xf0000000;
if (x)
hash ^= x >> 24;
hash &= ~x;
}
return hash % MAXKEY;
}
/***********************************************************
* 功能: 将运算符、关键字、常量直接放入单词表
* tp: 单词指针
**********************************************************/
TkWord* tkword_direct_insert(TkWord* tp)
{
int keyno;
dynarray_add(&tktable, tp);
keyno = ELFHash(tp->spelling);
tp->next = tk_hashtable[keyno];
tk_hashtable[keyno] = tp;
return tp;
}
/***********************************************************
* 功能: 在单词表中查找单词
* p: 单词字符串指针
* keyno: 单词的哈希值
**********************************************************/
TkWord* tkword_find(char *p, int keyno)
{
TkWord *tp = NULL, *tp1;
for (tp1 = tk_hashtable[keyno]; tp1; tp1 = tp1->next)
{
if (!strcmp(p, tp1->spelling))
{
token = tp1->tkcode;
tp = tp1;
}
}
return tp;
}
/***********************************************************
* 功能: 分配堆内存并将数据初始化为'0'
* size: 分配内存大小
**********************************************************/
void *mallocz(int size)
{
void *ptr;
ptr = malloc(size);
if (!ptr && size)
error("内存分配失败");
memset(ptr, 0, size);
return ptr;
}
/***********************************************************
* 功能: 标识符插入单词表,先查找,查找不到再插入单词表
* p: 单词字符串指针
**********************************************************/
TkWord* tkword_insert(char *p)
{
TkWord *tp;
int keyno;
char *s;
char *end;
int length;
keyno = ELFHash(p);
tp = tkword_find(p, keyno);
if (tp == NULL)
{
length = strlen(p);
tp = (TkWord*)mallocz(sizeof(TkWord) + length + 1);
tp->next = tk_hashtable[keyno];
tk_hashtable[keyno] = tp;
dynarray_add(&tktable, tp);
tp->tkcode = tktable.count - 1;
s = (char*)tp + sizeof(TkWord);
tp->spelling = (char *)s;
for (end = p + length; p < end;)
{
*s++ = *p++;
}
*s = (char)'\0';
}
return tp;
}2.3 单词表存储结构
3.错误处理
在进行词法分析之前,还需要先做一个错误处理的部分,在编译和链接的过程中,需要根据错误种类和具体错误,来直观的输出错误
error.h(实际上放在头文件lexical_analysis.h):
/* 错误级别 */
enum e_ErrorLevel
{
LEVEL_WARNING,
LEVEL_ERROR,
};
/* 工作阶段 */
enum e_WorkStage
{
STAGE_COMPILE,
STAGE_LINK,
};
void handle_exception(int stage, int level, char *fmt, va_list ap);//异常处理:作为编译警告、错误和链接错误调用的功能函数
void warning(char *fmt, ...);//编译警告处理
void error(char *fmt, ...);//错误处理
void expect(char *msg);//提示错误,此处缺少某个语法成分
void link_error(char *fmt, ...);//链接错误处理
void *get_tkstr(int v);//取得单词v所代表的源码字符串error.c:
#include "lexical_analysis.h"
/******************************************************************
* 异常处理
* stage: 编译阶段还是链接阶段
* level:错误级别
* fmt:参数输出格式
* ap:可变参数列表
*******************************************************************/
void handle_exception(int stage, int level, char *fmt, va_list ap)
{
char buf[1024];
vsprintf(buf, fmt, ap);
if (stage == STAGE_COMPILE)
{
if (level == LEVEL_WARNING)
printf("%s(第%d行): 编译警告: %s!\n", filename, line_num, buf);
else
{
printf("%s(第%d行): 编译错误: %s!\n", filename, line_num, buf);
exit(-1);
}
}
else
{
printf("链接错误: %s!\n", buf);
exit(-1);
}
}
/******************************************************************
* 编译警告处理
* fmt:参数输出格式
* ap:可变参数列表
*******************************************************************/
void warning(char *fmt, ...)
{
va_list ap = NULL;
va_start(ap, fmt);
handle_exception(STAGE_COMPILE, LEVEL_WARNING, fmt, ap);
va_end(ap);
}
/******************************************************************
* 编译错误处理
* fmt:参数输出格式
* ap:可变参数列表
*******************************************************************/
void error(char *fmt, ...)
{
va_list ap = NULL;
va_start(ap, fmt);
handle_exception(STAGE_COMPILE, LEVEL_ERROR, fmt, ap);
va_end(ap);
}
/******************************************************************
* 链接错误处理
* fmt:参数输出格式
* ap:可变参数列表
*******************************************************************/
void link_error(char *fmt, ...)
{
va_list ap = NULL;
va_start(ap, fmt);
handle_exception(STAGE_LINK, LEVEL_ERROR, fmt, ap);
va_end(ap);
}
/******************************************************************
* 提示错误,此处缺少某个语法成分
* msg:需要什么语法成分
*******************************************************************/
void expect(char *msg)
{
error("缺少%s", msg);
}
/******************************************************************
* 功能:取得单词v所代表的源码字符串
* v:单词编号
*******************************************************************/
char *get_tkstr(int v)
{
if (v > tktable.count)
return NULL;
else if (v >= TK_CINT && v <= TK_CSTR)
return sourcestr.data;
else
return ((TkWord*)tktable.data[v])->spelling;
}4. 词法分析
将源程序的字符串解析成一个个单词符号
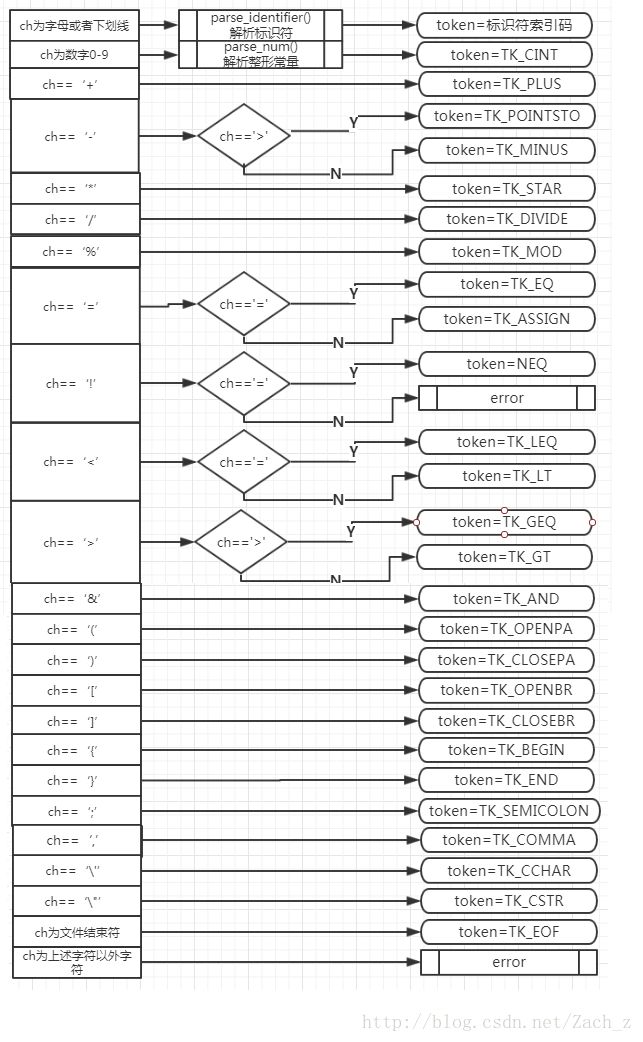
4.1 单词编码
因为要把字符串解析成一个个单词,而这些单词有可能是运算符有可能是关键字,也有可能是自定义的标识符,所以需要给他们绑定一个身份
lexical_analysis.h:
/* 单词编码 */
enum e_TokenCode
{
/* 运算符及分隔符 */
TK_PLUS, // + 加号
TK_MINUS, // - 减号
TK_STAR, // * 星号
TK_DIVIDE, // / 除号
TK_MOD, // % 求余运算符
TK_EQ, // == 等于号
TK_NEQ, // != 不等于号
TK_LT, // < 小于号
TK_LEQ, // <= 小于等于号
TK_GT, // > 大于号
TK_GEQ, // >= 大于等于号
TK_ASSIGN, // = 赋值运算符
TK_POINTSTO, // -> 指向结构体成员运算符
TK_DOT, // . 结构体成员运算符
TK_AND, // & 地址与运算符
TK_OPENPA, // ( 左圆括号
TK_CLOSEPA, // ) 右圆括号
TK_OPENBR, // [ 左中括号
TK_CLOSEBR, // ] 右圆括号
TK_BEGIN, // { 左大括号
TK_END, // } 右大括号
TK_SEMICOLON, // ; 分号
TK_COMMA, // , 逗号
TK_ELLIPSIS, // ... 省略号
TK_EOF, // 文件结束符
/* 常量 */
TK_CINT, // 整型常量
TK_CCHAR, // 字符常量
TK_CSTR, // 字符串常量
/* 关键字 */
KW_CHAR, // char关键字
KW_SHORT, // short关键字
KW_INT, // int关键字
KW_VOID, // void关键字
KW_STRUCT, // struct关键字
KW_IF, // if关键字
KW_ELSE, // else关键字
KW_FOR, // for关键字
KW_CONTINUE, // continue关键字
KW_BREAK, // break关键字
KW_RETURN, // return关键字
KW_SIZEOF, // sizeof关键字
KW_ALIGN, // __align关键字
KW_CDECL, // __cdecl关键字 standard c call
KW_STDCALL, // __stdcall关键字 pascal c call
/* 标识符 */
TK_IDENT
};4.2 词法分析实现
- 首先进行初始化,即是让关键字、运算符这些特权单词,在正式词法分析之前进入单词表
- 之后进行取单词,根据一个个字符的先后顺序,解析空白和注释、解析标识符、解析整数、判断出一个个单词
lex.h(lexical_analysis.h):
/* 词法状态 */
enum e_LexState
{
LEX_NORMAL,
LEX_SEP
};
void init_lex();//词法分析初始化
void skip_white_space();//忽略空格,TAB及回车
void parse_comment();//解析注释
void preprocess();//预处理,忽略分隔符及注释
int is_nodigit(char c);//判断c是否为字母(a-z,A-Z)或下划线(-)
int is_digit(char c);//判断c是否为数字
TkWord* parse_identifier();//解析标识符
void parse_num();//解析整型常量
void parse_string(char sep);//解析字符常量、字符串常量
void get_token();//取单词lex.c:
#include "lexical_analysis.h"
DynString tkstr; //单词字符串
DynString sourcestr; //单词源码字符串
char ch; //当前取到的源码字符
int token; //单词编码
int tkvalue; //单词值
int line_num; //行号
/***********************************************************
* 功能: 词法分析初始化
**********************************************************/
void init_lex()
{
TkWord *tp;
static TkWord keywords[] = {
{ TK_PLUS, NULL, "+" },
{ TK_MINUS, NULL, "-" },
{ TK_STAR, NULL, "*" },
{ TK_DIVIDE, NULL, "/" },
{ TK_MOD, NULL, "%" },
{ TK_EQ, NULL, "==" },
{ TK_NEQ, NULL, "!=" },
{ TK_LT, NULL, "<" },
{ TK_LEQ, NULL, "<=" },
{ TK_GT, NULL, ">" },
{ TK_GEQ, NULL, ">=" },
{ TK_ASSIGN, NULL, "=" },
{ TK_POINTSTO, NULL, "->" },
{ TK_DOT, NULL, "." },
{ TK_AND, NULL, "&" },
{ TK_OPENPA, NULL, "(" },
{ TK_CLOSEPA, NULL, ")" },
{ TK_OPENBR, NULL, "[" },
{ TK_CLOSEBR, NULL, "]" },
{ TK_BEGIN, NULL, "{" },
{ TK_END, NULL, "}" },
{ TK_SEMICOLON, NULL, ";" },
{ TK_COMMA, NULL, "," },
{ TK_ELLIPSIS, NULL, "..." },
{ TK_EOF, NULL, "End_Of_File" },
{ TK_CINT, NULL, "整型常量" },
{ TK_CCHAR, NULL, "字符常量" },
{ TK_CSTR, NULL, "字符串常量" },
{ KW_CHAR, NULL, "char" },
{ KW_SHORT, NULL, "short" },
{ KW_INT, NULL, "int" },
{ KW_VOID, NULL, "void" },
{ KW_STRUCT, NULL, "struct" },
{ KW_IF, NULL, "if" },
{ KW_ELSE, NULL, "else" },
{ KW_FOR, NULL, "for" },
{ KW_CONTINUE, NULL, "continue" },
{ KW_BREAK, NULL, "break" },
{ KW_RETURN, NULL, "return" },
{ KW_SIZEOF, NULL, "sizeof" },
{ KW_ALIGN, NULL, "__align" },
{ KW_CDECL, NULL, "__cdecl" },
{ KW_STDCALL, NULL, "__stdcall" },
{ 0, NULL, NULL }
};
dynarray_init(&tktable, 8);
for (tp = &keywords[0]; tp->spelling != NULL; tp++)
{
tkword_direct_insert(tp);
}
}
/***********************************************************
* 功能: 忽略空格,TAB及回车
**********************************************************/
void skip_white_space()
{
while (ch == ' ' || ch == '\t' || ch == '\r')
{
if (ch == '\r')
{
getch();
if (ch != '\n')
return;
line_num++;
}
printf("%c", ch);
getch();
}
}
/***********************************************************
* 功能: 解析注释
**********************************************************/
void parse_comment()
{
getch();
do
{
do
{
if (ch == '\n' || ch == '*' || ch == CH_EOF)
break;
else
getch();
} while (1);
if (ch == '\n')
{
line_num++;
getch();
}
else if (ch == '*')
{
getch();
if (ch == '/')
{
getch();
return;
}
}
else
{
error("一直到文件尾未看到配对的注释结束符");
return;
}
} while (1);
}
/***********************************************************
* 功能: 预处理,忽略分隔符及注释
**********************************************************/
void preprocess()
{
while (1)
{
if (ch == ' ' || ch == '\t' || ch == '\r')
skip_white_space();
else if (ch == '/')
{
//向前多读一个字节看是否是注释开始符,猜错了把多读的字符再放回去
getch();
if (ch == '*')
{
parse_comment();
}
else
{
ungetc(ch, fin); //把一个字符退回到输入流中
ch = '/';
break;
}
}
else
break;
}
}
/***********************************************************
* 功能: 判断c是否为字母(a-z,A-Z)或下划线(-)
* c: 字符值
**********************************************************/
int is_nodigit(char c)
{
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_';
}
/***********************************************************
* 功能: 判断c是否为数字
* c: 字符值
**********************************************************/
int is_digit(char c)
{
return c >= '0'&&c <= '9';
}
/***********************************************************
* 功能: 解析标识符
**********************************************************/
TkWord* parse_identifier()
{
dynstring_reset(&tkstr);
dynstring_chcat(&tkstr, ch);
getch();
while (is_nodigit(ch) || is_digit(ch))
{
dynstring_chcat(&tkstr, ch);
getch();
}
dynstring_chcat(&tkstr, '\0');
return tkword_insert(tkstr.data);
}
/***********************************************************
* 功能: 解析整型常量
**********************************************************/
void parse_num()
{
dynstring_reset(&tkstr);
dynstring_reset(&sourcestr);
do {
dynstring_chcat(&tkstr, ch);
dynstring_chcat(&sourcestr, ch);
getch();
} while (is_digit(ch));
if (ch == '.')
{
do {
dynstring_chcat(&tkstr, ch);
dynstring_chcat(&sourcestr, ch);
getch();
} while (is_digit(ch));
}
dynstring_chcat(&tkstr, '\0');
dynstring_chcat(&sourcestr, '\0');
tkvalue = atoi(tkstr.data);
}
/***********************************************************
* 功能: 解析字符常量、字符串常量
* sep: 字符常量界符标识为单引号(')
字符串常量界符标识为双引号(")
**********************************************************/
void parse_string(char sep)
{
char c;
dynstring_reset(&tkstr);
dynstring_reset(&sourcestr);
dynstring_chcat(&sourcestr, sep);
getch();
for (;;)
{
if (ch == sep)
break;
else if (ch == '\\')
{
dynstring_chcat(&sourcestr, ch);
getch();
switch (ch) //解析转义字符
{
case '0':
c = '\0';
break;
case 'a':
c = '\a';
break;
case 'b':
c = '\b';
break;
case 't':
c = '\t';
break;
case 'n':
c = '\n';
break;
case 'v':
c = '\v';
break;
case 'f':
c = '\f';
break;
case 'r':
c = '\r';
break;
case '\"':
c = '\"';
break;
case '\'':
c = '\'';
break;
case '\\':
c = '\\';
break;
default:
c = ch;
if (c >= '!'&&c < '~')
warning("非法转义字符:\'\\%c\'", c);
else
warning("非法转义字符:\'\\0x%x\'", c);
break;
}
dynstring_chcat(&tkstr, c);
dynstring_chcat(&sourcestr, ch);
getch();
}
else
{
dynstring_chcat(&tkstr, ch);
dynstring_chcat(&sourcestr, ch);
getch();
}
}
dynstring_chcat(&tkstr, '\0');
dynstring_chcat(&sourcestr, sep);
dynstring_chcat(&sourcestr, '\0');
getch();
}
/***********************************************************
* 功能: 取单词
**********************************************************/
void get_token()
{
preprocess();
switch (ch)
{
case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': case 'g':
case 'h': case 'i': case 'j': case 'k': case 'l': case 'm': case 'n':
case 'o': case 'p': case 'q': case 'r': case 's': case 't':
case 'u': case 'v': case 'w': case 'x': case 'y': case 'z':
case 'A': case 'B': case 'C': case 'D': case 'E': case 'F': case 'G':
case 'H': case 'I': case 'J': case 'K': case 'L': case 'M': case 'N':
case 'O': case 'P': case 'Q': case 'R': case 'S': case 'T':
case 'U': case 'V': case 'W': case 'X': case 'Y': case 'Z':
case '_':
{
TkWord* tp;
tp = parse_identifier();
token = tp->tkcode;
break;
}
case '0': case '1': case '2': case '3':
case '4': case '5': case '6': case '7':
case '8': case '9':
parse_num();
token = TK_CINT;
break;
case '+':
getch();
token = TK_PLUS;
break;
case '-':
getch();
if (ch == '>')
{
token = TK_POINTSTO;
getch();
}
else
token = TK_MINUS;
break;
case '/':
token = TK_DIVIDE;
getch();
break;
case '%':
token = TK_MOD;
getch();
break;
case '=':
getch();
if (ch == '=')
{
token = TK_EQ;
getch();
}
else
token = TK_ASSIGN;
break;
case '!':
getch();
if (ch == '=')
{
token = TK_NEQ;
getch();
}
else
error("暂不支持'!'(非操作符)");
break;
case '<':
getch();
if (ch == '=')
{
token = TK_LEQ;
getch();
}
else
token = TK_LT;
break;
case '>':
getch();
if (ch == '=')
{
token = TK_GEQ;
getch();
}
else
token = TK_GT;
break;
case '.':
getch();
if (ch == '.')
{
getch();
if (ch != '.')
error("省略号拼写错误");
else
token = TK_ELLIPSIS;
getch();
}
else
{
token = TK_DOT;
}
break;
case '&':
token = TK_AND;
getch();
break;
case ';':
token = TK_SEMICOLON;
getch();
break;
case ']':
token = TK_CLOSEBR;
getch();
break;
case '}':
token = TK_END;
getch();
break;
case ')':
token = TK_CLOSEPA;
getch();
break;
case '[':
token = TK_OPENBR;
getch();
break;
case '{':
token = TK_BEGIN;
getch();
break;
case ',':
token = TK_COMMA;
getch();
break;
case '(':
token = TK_OPENPA;
getch();
break;
case '*':
token = TK_STAR;
getch();
break;
case '\'':
parse_string(ch);
token = TK_CCHAR;
tkvalue = *(char *)tkstr.data;
break;
case '\"':
{
parse_string(ch);
token = TK_CSTR;
break;
}
case EOF:
token = TK_EOF;
break;
default:
error("不认识的字符:\\x%02x", ch); //上面字符以外的字符,只允许出现在源码字符串,不允许出现的源码的其它位置
getch();
break;
}
}5. 控制程序
包括主函数,初始化程序、着色程序和cleanup扫尾清理
lexical_analysis.h:
void getch();//从源文件中读取一个字符
extern TkWord* tk_hashtable[MAXKEY];// 单词哈希表
extern DynArray tktable; // 单词动态数组
extern DynString tkstr; //单词字符串
extern DynString sourcestr; //单词源码字符串
extern char ch; //当前取到的源码字符
extern int token; //单词编码
extern int tkvalue; //单词值
extern int line_num; //行号
extern FILE *fin;
extern char *filename;
extern char *outfile;lexical_analysis.c:
#include "lexical_analysis.h"
FILE *fin = NULL;
char *filename;
char *outfile;
/***********************************************************
* 功能: 词法着色
**********************************************************/
void color_token(int lex_state)
{
HANDLE h = GetStdHandle(STD_OUTPUT_HANDLE);
char *p;
switch (lex_state)
{
case LEX_NORMAL:
{
if (token >= TK_IDENT)
SetConsoleTextAttribute(h, FOREGROUND_INTENSITY);
else if (token >= KW_CHAR)
SetConsoleTextAttribute(h, FOREGROUND_GREEN | FOREGROUND_INTENSITY);
else if (token >= TK_CINT)
SetConsoleTextAttribute(h, FOREGROUND_RED | FOREGROUND_GREEN);
else
SetConsoleTextAttribute(h, FOREGROUND_RED | FOREGROUND_INTENSITY);
p = get_tkstr(token);
printf("%s", p);
break;
}
case LEX_SEP:
printf("%c", ch);
break;
}
}
/***********************************************************
* 功能: 词法分析测试
**********************************************************/
void test_lex()
{
do
{
get_token();
color_token(LEX_NORMAL);
} while (token != TK_EOF);
printf("\n代码行数: %d行\n", line_num);
}
/***********************************************************
* 功能: 初始化
**********************************************************/
void init()
{
line_num = 1;
init_lex();
}
/***********************************************************
* 功能: 扫尾清理工作
**********************************************************/
void cleanup()
{
int i;
for (i = TK_IDENT; i < tktable.count; i++)
{
free(tktable.data[i]);
}
free(tktable.data);
}
/***********************************************************
* 功能: 得到文件扩展名
* fname: 文件名称
**********************************************************/
char *get_file_ext(char *fname)
{
char *p;
p = strrchr(fname, '.');
return p + 1;
}
/***********************************************************
* 功能: 从源文件中读取一个字符
**********************************************************/
void getch()
{
ch = getc(fin);
}
/***********************************************************
* 功能: main主函数
**********************************************************/
int main(int argc, char ** argv)
{
fin = fopen(argv[1], "rb");
system("pause");
if (!fin)
{
printf("不能打开SC源文件!\n");
return 0;
}
init();
getch();
test_lex();
cleanup();
fclose(fin);
printf("%s 词法分析成功!", argv[1]);
system("pause");
return 1;
}测试
测试代码:
/***********************************************************
* color_token_demo.c
**********************************************************/
struct point
{
int x;
int y;
};
void main()
{
int arr[10];
int i;
struct point pt;
pt.x =1024;
pt.y=768;
for(i = 0; i < 10; i = i + 1)
{
arr[i]=i;
if (i == 6)
{
continue;
}
else
{
printf("arr[%d]=%d\n",i,arr[i]);
}
}
printf("pt.x = %d, pt.y = %d\n",pt.x,pt.y);
}
结果:
