DirectX 11 学习笔记-02【输入装配/图元拓扑/缓冲区与资源】
目录
输入装配阶段
图元拓扑
创建缓冲区
资源间的拷贝与性能问题
注
参考
输入装配阶段
程序生成的场景数据,本质上是一系列的几何图元。我们需要以一定的方式将这些图元绑定到图形管线中,并经过一系列的阶段,最终显示在屏幕内。渲染管线的第一阶段是输入装配阶段,这一阶段从内存中读取几何数据并将这些数据组合为几何图元。
顶点作为一个基本的图元,三个顶点可以组成一个三角形,两个顶点可以组成一条直线。在DirectX中,我们通过顶点缓冲区这一数据结构将顶点数据绑定到图形管线中。
顶点中除了基本的空间位置信息外,还可以包含各种附加属性,例如颜色和法线向量。因此在向管线中绑定顶点信息之前,我们必须告诉管线我们的顶点数据的形式,里面包含的各个数据的意义。
定义顶点结构体后,我们必须使用输入布局(ID3D11InputLayout)将顶点的描述信息告诉D3D。输入布局中,语义名(SemanticName)/语义索引(SemanticIndex)用于将顶点结构体中的元素映射为顶点着色器参数,格式(Format)描述了元素的格式,InputSlot指定了当前元素来自于哪个输入槽,AlignedByteOffset表示从顶点结构体的起始位置到顶点元素的起始位置之间的字节偏移量。此外还有InputSlotClass和InstanceDataStepRate两个参数。
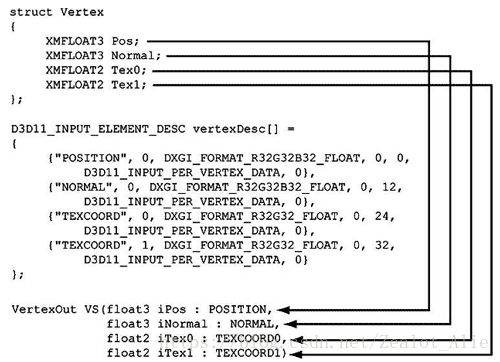
有关InputSlot,这里需要一提Interleaved Buffer和Separate Buffer。
将所有的顶点数据(position, normal, uv...)放在同一个buffer中称为Interleaved Buffer,这种情况下一般我们只需要一个InputSlot,而将顶点数据分别存放到不同的buffer中则称为Separate Buffer,此时需要使用多个Inputslot(Directx 11 最多支持16个Inputslot)。从局部性原理很容易理解两者的差别,在Interleaved Buffer中的每一个顶点,其中的数据都是连续的。对顶点着色器而言,我们只需要访问当前顶点的数据即可,所以这种情况下,GPU处理顶点的效率会更高,因为访问速度更快。而另一种情况下,GPU的访问效率会略微降低,但对CPU来说,每种类型的数据数组都是连续的,所以处理起来反而可能会更快。另外,某些情况下对不同的着色器,需要的顶点数据可能是不同的,例如某个着色器只需要position信息,如果使用的是Interleaved Buffer,那么就需要把一系列不需要的信息也一同拷贝过去,但如果是Separate Buffer,那么就只需要装载需要的信息即可。
总之两种情况下都有各自的优缺点,所以通常不用太在意使用哪种方法,当出现性能问题时做性能分析再确定是否存在问题即可。
图元拓扑
现在图形管线知道如何处理每一个顶点,但对于一系列顶点,管线仍然不知道如何解释它们,它们到底是一组三角形,还是一组直线,又或者只是几个点?为了告诉Directx该用何种方式来组成图元,我们需要指定图元拓扑。调用IASetPrimitiveTopology来指定一种图元拓扑类型,在新的图元拓扑被指定之前,它会一直生效下去。我们常用的图元拓扑是三角形列表(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST),就是说顶点中每三个顶点组成一个三角形。应该注意的是,三角形三个顶点的顺序非常重要,我们通过三个顶点的顺序来确定三角形哪个面是正面,为保证效率,通常我们只渲染三角形的一个面,所以顺序就决定了哪个面会被渲染出来。
使用三角形列表带来的一个问题是,构成3D物体的三角形会共享许多相同的顶点,如果我们传入每个三角形的顶点数据,那么会带来大量的额外内存需求并增加图形硬件的处理负担。为了消除这一问题,索引(index)被引入进来。假设现在有两个相邻的三角形,由于它们共用一条边,所以一共有4个顶点。顶点列表可以这样创 建:
Vertex v[4] = {v0, v1, v2, v3}; 而索引列表需要定义如何将顶点列表中的顶点放在一起,构成两个三角形。
UINT indexList[6] =
{ 0, 1, 2, // Triangle 0
0, 2, 3}; // Triangle 1由于索引是一个简单的整数,不需要像顶点一样占用大量的内存,而且在通常情况下,适当的对顶点缓存排序,可以让图形硬件不必重复处理顶点。
创建缓冲区
上一篇提到,资源被用于存储渲染场景的数据,Device被用于创建资源。所以我们要把顶点数据和索引数据传入到管线中,必须为它们创建资源。用于存放顶点数据和索引数据的缓冲区分别为顶点缓冲区和索引缓冲区,通过调用ID3D11Device::CreateBuffer来创建缓冲区。
创建缓冲区时,我们需要填充一个D3D11_BUFFER_DESC 结构体来描述这个缓冲区,ByteWidth用于指定缓冲区的大小。Usage用于指定缓冲区的用途,BindFlags与资源视图关联,CPUAccessFlags表示CPU是否需要访问这个资源,MiscFlags和StructureByteStride一般为0即可,只有某些情况需要使用。
重点说一下Usage。Usage和CPU/GPU对资源可能的操作有关,根据不同的Usage对资源做不同的优化。
一共有四种Usage:
D3D11_USAGE_IMMUTABLE 代表资源创建之后其中的内容不会再改变,只有GPU能读取其中的内容;
D3D11_USAGE_DEFAULT 表示GPU会对资源进行读写操作,而CPU无法对资源进行读写。
D3D11_USAGE_DYNAMIC 表示CPU可能会频繁更新资源中的内容,GPU只能读取,CPU只能写入。
D3D11_USAGE_STAGING 表示CPU需要读取其中的资源,因此CPU可以通过拷贝的方式来读取资源内容,而GPU只能写入。
实际上,这四种资源又可以分为两类mapable 和non-mapable。Dynamic和Staging的资源是mappable的,而Default和Immutable的资源是non-mapable的。
Default和Immutable资源被存放于显存之中,因此GPU对这两种类型的资源的访问效率都非常高。其中由于Immutable是只读的,所以优化的程度最高。
Dynamic资源存放于AGP memory中。AGP是Accelerated Graphics Port的缩写,实际上它是系统存储的一部分,专门用于GPU和CPU之间的共同访问。GPU可以直接访问它,但比起显存,GPU访问AGP的开销更大一些。对GPU而言Dynamic资源是只读的,相反,CPU只能写入Dynamic资源。虽然GPU访问Dynamic资源的效率较低,但对于需要CUP频繁进行更新的资源来说,由于CPU的写入AGP的速度还是比较快的。
Staging资源的主要用途是让应用能够通过拷贝的方式访问Default类型的资源。GPU通过Direct Memory Access的方式将显存中的数据拷贝到系统存储中,从而让CPU能够访问它。Staging资源无法作为管线的输出,所以只能通过这种拷贝的方式来获得GPU中的资源数据。在Compute Shader中,Staging资源一般作为输出使用。
资源间的拷贝与性能问题
Default/Immutable资源到Default的资源的拷贝是最为常见也是最为快速的,因为两者都在显存中,且CPU对它们没有直接的访问权限,所以GPU能够很好的处理它们。
当涉及到CPU和GPU之间的读写时,问题就变得复杂了。
由于CPU和GPU运行于并行构架:一个或多个的CPU处理器和一个或多个的GPU核心。对任何的并行构架而言,要最好的性能,就需要安排足够的任务防止处理器停下来,并且一个处理器不需要等待另一个处理器完成工作。 对GPU/CPU并行而言,最糟糕的情况就是强制一边去等另一边的结果。所以应当避免GPU和CPU之间对资源的争夺以及相互直接的等待。
对Default资源,可以通过使用UpdateSubresource将CPU中的数据拷贝到显存中从而更新显存中的内容,但不应该应该频繁使用这种方式,因为可能存在对资源的竞争。例如在应用使用一个顶点缓冲区执行了一次draw call后,调用UpdateSubresource更新这个顶点缓冲区,但这次draw call还没被GPU执行,那么此时就发生了对资源的竞争。
当竞争发生时,会执行两次拷贝,第一次CPU将数据拷贝到command buffer![]() 可访问的一段内存中,这一次拷贝过程在方法Return之前完成。第二次拷贝发生在command buffer提交到GPU时,GPU将数据拷贝到显存中。
可访问的一段内存中,这一次拷贝过程在方法Return之前完成。第二次拷贝发生在command buffer提交到GPU时,GPU将数据拷贝到显存中。
当不存在竞争是,UpdateSubresource 的行为取决于对CPU来说哪种方式更快,可以按照和竞争发生时一样的方法拷贝两次,也可以让CPU把数据拷贝到最终的资源位置。哪种方式更好取决于底层构架的实现。
同样地对Dynamic资源,我们可以使用Map的方式让CPU写入其中的信息。但同样存在一个资源竞争的问题,如果调用Map的时资源仍在管线中被使用,那么就可能造成性能问题。Dynamic资源本身就是为了频繁使用Map更新资源的情况设计的,所以对资源竞争的情况做了最大程度的优化。另外在Map操作时,可以使用MapFlags来指定当GPU处于busy状态时CPU的行为,特别地,可以使用D3D11_MAP_WRITE_DISCARD来防止资源竞争。当使用这个flag时,Map不会改变旧的数据buffer,而是申请一块新的数据用于存放CPU填入的数据。GPU可以继续使用旧的数据,当GPU不再使用时旧数据会被自动释放或者重用进而使用新数据。
对Staging资源,由于它无法作为管线输出,所以实际上它是一种访问Default资源的手段。我们通过CopyResource将Default的资源拷贝到Staging资源中,从而CPU可以对Staging资源进行Map进而访问GPU传过来的数据。由于CPU和GPU是并行的,它们之间存在一个command buffer,CPU的各种命令状态先存在command buffer然后再被GPU执行,也就是说CopyResource并不是一旦调用结束资源就能被CPU访问的,这实际上是一个异步的过程。只有当command buffer被提交到GPU并且命令被完全执行,Staging资源才能被正确Map访问。所以这里的问题在于何时可以用Map访问数据,如果应用在CopyResource之后立刻Map,那么带来的结果是CPU和GUP将被立刻同步,command buffer中的内容会立刻被提交,而CPU则要等待命令提交并最终拷贝完成,这一系列操作都是非常耗费时间的,会带来严重的性能问题。所以当CopyResource调用之后,应当等待一段时间再使用Map访问数据,具体来说,等待2帧就能保证命令已经执行完全了。
总之,CPU在访问资源时需要mapping。Mapping意味着应用在尝试赋予CPU访问资源的权限。Mapping一个资源的底层存储空间可能造成性能瓶颈,所以应当要注意如何和何时进行这个操作。在错误的时候进行一个mapping操作可能引起巨大的性能问题,因为它会强制GPU和CPU之间同步。
注
[1]Command buffer是用于存储硬件可识别的命令的缓冲区,API上的状态信息、Draw Call等硬件是无法识别的,需要通过UMD(User Mode Driver)转换成硬件可识别的命令并写入command buffer中,写满或在特殊情况下就提交KMD(Kernel Mode Driver),KMD再以某种方式把command送到GPU。Command buffer可以放在System memory或Video memory,取决于具体硬件实现。
以下四种情况下command buffer的命令会被立即提交
-
Present调用时
-
Flush调用时
-
Command buffer满时。它的尺寸是动态的,由操作系统和图形驱动控制。
-
CPU要求访问命令执行的结果时。
参考
《Introduction to 3D Game Programming with Directx 11》
D3D11_USAGE_STAGING, what kind of GPU/CPU memory is used?
Resource Management Best Practices
Vertex Buffers Interleaved or Separate
How To Use Dynamic Resources
Devicecontext-UpdateSubresource
DirectX 11: how to define input layout when using more than one vertex buffer?
Submitting a Command Buffer