整理下管线
此时一定要有这张图

注意表中的数据流向
强调几个细节 之前对次序理解有点乱
rasterizer之前 管线里是只有逐顶点信息的
IA里面会setup primitive 通过PrimitiveTopology属性 triangle strip之类的
-------------------
在vs 会用matrix 做space trans到 hcs
model- world ---view---- homogeneous clip space-----normalized device coordinates(线性部分/r)
这五个变换都在一个矩阵里 一步就出来了
mvp这个参数是uniform里传入 vs 在vs里乘到 semantic为positon的 varying(vs-ps的structure)
这步只是把顶点数据 变到了 cvv 在hcs
接下来是硬件做了/w真正到了 ndc
之后硬件又做了screen mapping 到了 screen space(这步的涉及的数据在rs的viewport参数表里)
有另外一片blog https://www.cnblogs.com/minggoddess/p/10582663.html讲了相关细节
---------------
setup triangle的时候 会做back face cull 可设置 这附近会做一次earlyz
rasterization
插值顶点属性 在triangle traversal阶段
此时属性是逐像素了
之后pixel process shadeing and merge
merge阶段称为 ROP raster operation pipeline
ROP顺序
pixel Ownership test
Scisssor test
Alpha Test(dx9之后这不是硬件功能了 在shader里用alpha做discard)
Stencil test
depth test
blending
dithering
logic op(color blending 非alphablend的一些位操作 或者max min)
---------------------
CS
gpu computing
以下列了几种cs的使用场合
1这种用法 比较有意思 数据gpu处理之后不交给cpu直接用cs在gpu处理 这样 就不需要cpugpu相互wait了
2因为它能共享资源shared memtory 所以用cs算distribution or average luminace of an image是ps操作的2倍速度 ,这个也挺有意思 可以看下
Giesen, Fabian, \A Trip through the Graphics Pipeline 2011," The ryg blog, July 9, 2011.
Cited on p. 32, 42, 46, 47, 48, 49, 52, 53, 54, 55, 141, 247, 684, 701, 784, 1040
3particle systems, mesh processing such as
facial animation [134], culling [1883, 1884], image ltering [1102, 1710], improving
depth precision [991], shadows [865], depth of feld [764], and any other tasks where a
set of GPU processors can be brought to bear.
4Wihlidal [1884] discusses how compute
shaders can be more ecient than tessellation hull shaders
cs可能比ts有更好的性能
----------如果我们有更多的gpu budget
----------------
TS
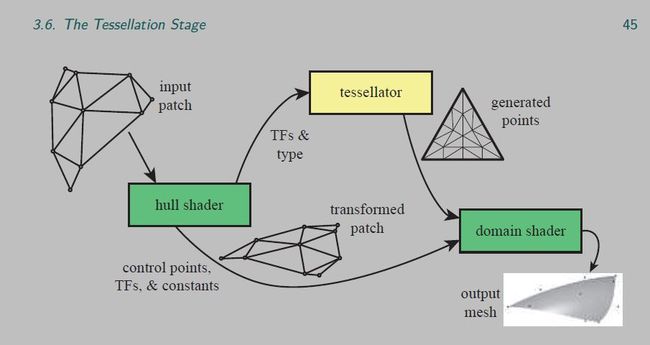
hs加control points
ts加面
ds将他们组合起来 生成vertex normal uv。。。
-------------
gs modify or copy primitives
gs。。。项目里用起来性能略尴尬
cubemap
http://www.zwqxin.com/archives/shaderglsl/talk-about-geometry-shader.html
http://www.klayge.org/2011/07/26/%E4%B8%8D%E4%BA%89%E6%B0%94%E7%9A%84geometry-shader/
可以做着试试 说不定现在显卡不一样了呢。。。
有个实时cubemap的优化 比延迟更新 降低分辨率 是不是帅多了。。会对不上 闪烁
六个matrix传过去画在texturearray上面一个pass出(所以这里也是个texturearray做rtv的例子了 还csm也可以用texturearray做rtv
csm 原理同上https://docs.nvidia.com/gameworks/content/gameworkslibrary/graphicssamples/opengl_samples/cascadedshadowmapping.htm
在ff里用过 一次画四个cascades出来,性能未见明显提升。。因为没bound在那里。。。shadow费 vertex太多。。应该延迟更新 或者bake
fastgeometry 可以试试
毛发 粒子 边缘检测forshadow
---------------------------------------------------------------
stream output 用stream output可以把顶点数据 作为下一次pipleine的输入
比如tessellation lod 第一次pipeline 先生成新的面 去掉rs ps阶段 第二次过pipeline 走vs ps处理刚刚新生成的那些面
还可以做水流 粒子 皮肤 那些需要迭代顶点的
浮点数返回
以primitive展开来返回数据 失去索引 所以用point primitive处理第一遍
================================
pbe 这边有个dither 值得关注 tbdr 下dither once