HDFS
一、HDFS
当数据量达到PB,ZB级别,或者传统关系型数据库遇到难题的时候,那么采用HDFS来替代是最好不过的工具了。
操作步骤
1. 架构图
Hadoop是由Apache基金会所开发的分布式系统基础架构,组织架构如下图所示:
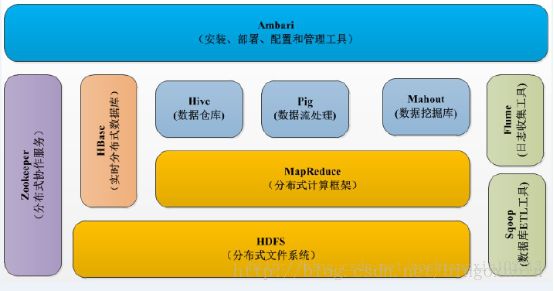
正如上图所示:Hadoop包含很多优秀的子项目,例如HDFS,Mapreduce,Hbase,Hive,Zookeeper等,其中最重要的,也是Hadoop当时风靡一时的原因是HDFS(分布式文件系统)和Mapreduce(分布式计算框架)。HDFS解释了,hadoop如何解决大数据的存储问题,而Mapreduce解释了,hadoop如何对大数据的计算问题。
2. HDFS
到底,Hadoop的HDFS是如何进行大数据存储的,下面一一道来。
首先,需要我们搭建Hadoop集群,hadoop集群简单来说就是把很多廉价的机器,通过hadoop组合起来,组成一个庞大的数据中心,全国著名的数据中心包括:谷歌,Facebook,微软等,平均一个数据中心大约几千万台机器,中国的北京,武汉,成都,上海,南京等城市,也有数据中心,这些数据中心为大数据提供了可靠的解决方案。
在hadoop集群中,负责大数据存储的当然就是HDFS,它主要由以下部分组成:
1个namenode:负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系;
1个secondary namenode:负责实现HDFS的高可用,当namenode宕机后,自动切换,取代namenode,保证数据的安全性;
无数个datanode:负责大量数据的存储,当然大部分容错机制都是在datanode上实现的。
Hadoop集群架构如下图所示:
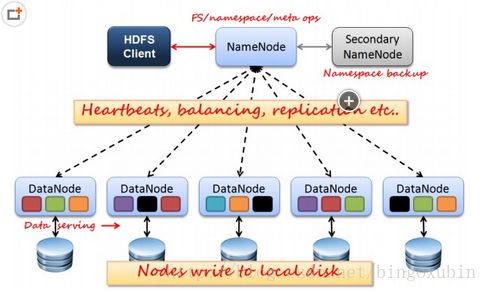
下面用简单的例子说明HDFS的存储操作:

例如,现在有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置,HDFS分布在三个机架上Rack1,Rack2,Rack3,具体步骤如下:
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
在HDFS中,数据块的大小默认为64M,并且每一块数据保存3份,所以不用担心数据的丢失问题,这样机架的个数,机器的个数可以无限扩展,就可以存放无限大的数据。
二、无法启动
问题描述:HDFS格式化后Namenode无法启动Datanode
解决办法:修改datanode节点中,VERSION文件的clusterID
打开hdfs-site.xml里配置的datanode和namenode对应的目录,分别打开current文件夹里的VERSION,
- NameNode的目录为:主节点的HADOOP_HOME/dfs/name/VERSION
- DataNode的目录为:从节点的HADOOP_HOME/dfs/data/VERSION
修改datanode里VERSION文件的clusterID与namenode里的一致,再重新启动dfs(执行start-dfs.sh)再执行jps命令可以看到datanode已正常启动。
三、API
功能:上传 下载文件到HDFS
package oa.epoint.com.hdfs;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.net.URI;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsTest {
public static void upload() throws Exception {
Configuration conf = new Configuration();
URI uri = new URI("hdfs://100.2.5.1:8020");
FileSystem fs = FileSystem.get(uri, conf, "HDFS");
Path resP = new Path("D://files/file1.txt");
Path destP = new Path("/tmp");
if (!fs.exists(destP)) {
fs.mkdirs(destP);
}
fs.copyFromLocalFile(resP, destP);
fs.close();
System.out.println("***********************");
System.out.println("上传成功!");
}
public static void download() throws Exception {
Configuration conf = new Configuration();
String dest = "hdfs://100.2.5.1/tmp/file1.txt";
String local = "D://files/downloads/file1.txt";
FileSystem fs = FileSystem.get(URI.create(dest), conf, "hdfs");
FSDataInputStream fsdi = fs.open(new Path(dest));
OutputStream output = new FileOutputStream(local);
IOUtils.copyBytes(fsdi, output, 4096, true);
System.out.println("***********************");
System.out.println("下载成功!");
}
public static void main(String[] args) throws Exception {
String arg = "";
Scanner scanner = new Scanner(System.in);
System.out.println("1、上传文件");
System.out.println("2、下载文件");
boolean isconture = true;
while (isconture) {
arg = scanner.next();
if ("1".equals(arg)) {
upload();
} else if ("2".equals(arg)) {
download();
}
System.out.println("是否继续 y/n");
if (scanner.next().equals("n")) {
isconture = false;
}
}
scanner.close();
}
}
四、监控
代码实例
package oa.epoint.com.watchFile;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
/**
* Title: 文件监控之定时器
*/
public class FileScheduler {
//定时器设置
private final Timer timer;
//构造方法
public FileScheduler(){
timer = new Timer();;
}
//设置守护线程
public FileScheduler(boolean isDaemon){
// 是否为守护线程
timer = new Timer(isDaemon);
}
/**
* MethodsTitle: 为定时器分配可执行任务
*/
public void schedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 重新执行任务
*/
private void reSchedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 停止当前定时器
*/
public void cancle(){
timer.cancel();
}
/**
* Title:停止当前定时器
*/
private class SchedulerTimerTask extends TimerTask{
private Runnable task;
private TimeStep step;
public SchedulerTimerTask(Runnable task,TimeStep step){
this.task = task;
this.step = step;
}
public void run() {
// 执行指定任务
task.run();
// 继续重复执行任务
reSchedule(task, step);
}
}
}
package oa.epoint.com.watchFile;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
/**
* Title: 文件监控之定时器
*/
public class FileScheduler {
//定时器设置
private final Timer timer;
//构造方法
public FileScheduler(){
timer = new Timer();;
}
//设置守护线程
public FileScheduler(boolean isDaemon){
// 是否为守护线程
timer = new Timer(isDaemon);
}
/**
* MethodsTitle: 为定时器分配可执行任务
*/
public void schedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 重新执行任务
*/
private void reSchedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 停止当前定时器
*/
public void cancle(){
timer.cancel();
}
/**
* Title:停止当前定时器
*/
private class SchedulerTimerTask extends TimerTask{
private Runnable task;
private TimeStep step;
public SchedulerTimerTask(Runnable task,TimeStep step){
this.task = task;
this.step = step;
}
public void run() {
// 执行指定任务
task.run();
// 继续重复执行任务
reSchedule(task, step);
}
}
}
package oa.epoint.com.watchFile;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
/**
* Title: 文件监控之定时器
*/
public class FileScheduler {
//定时器设置
private final Timer timer;
//构造方法
public FileScheduler(){
timer = new Timer();;
}
//设置守护线程
public FileScheduler(boolean isDaemon){
// 是否为守护线程
timer = new Timer(isDaemon);
}
/**
* MethodsTitle: 为定时器分配可执行任务
*/
public void schedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 重新执行任务
*/
private void reSchedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 停止当前定时器
*/
public void cancle(){
timer.cancel();
}
/**
* Title:停止当前定时器
*/
private class SchedulerTimerTask extends TimerTask{
private Runnable task;
private TimeStep step;
public SchedulerTimerTask(Runnable task,TimeStep step){
this.task = task;
this.step = step;
}
public void run() {
// 执行指定任务
task.run();
// 继续重复执行任务
reSchedule(task, step);
}
}
}
package oa.epoint.com.watchFile;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
/**
* Title: 文件监控之定时器
*/
public class FileScheduler {
//定时器设置
private final Timer timer;
//构造方法
public FileScheduler(){
timer = new Timer();;
}
//设置守护线程
public FileScheduler(boolean isDaemon){
// 是否为守护线程
timer = new Timer(isDaemon);
}
/**
* MethodsTitle: 为定时器分配可执行任务
*/
public void schedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 重新执行任务
*/
private void reSchedule(Runnable task,TimeStep step){
Date time = step.next();
SchedulerTimerTask timeTask = new SchedulerTimerTask(task,step);
// 安排在指定的时间 time 执行指定的任务 timetask
timer.schedule(timeTask, time);
}
/**
* MethodsTitle: 停止当前定时器
*/
public void cancle(){
timer.cancel();
}
/**
* Title:停止当前定时器
*/
private class SchedulerTimerTask extends TimerTask{
private Runnable task;
private TimeStep step;
public SchedulerTimerTask(Runnable task,TimeStep step){
this.task = task;
this.step = step;
}
public void run() {
// 执行指定任务
task.run();
// 继续重复执行任务
reSchedule(task, step);
}
}
}
五、eclipse连接
1. eclipse配置连接hadoop
将hadoop的plugins包,拷贝到eclipse的plugins目录下。管理员启动eclipse
在eclipse的windows下,preferences,找到Hadoop Map/Reduce,添加hadoop安装目录。即可。
在eclipse下,选windows,show view下,将map/reduce location调出来。 右击添加,具体端口参考配置文件。
# vim /opt/hadoop-2.6.0/etc/hadoop/core-site.xml
hadoop.tmp.dir
file:/opt/hadoop-2.6.0/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://192.168.208.110:9000
# vim /opt/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/opt/hadoop-2.6.0/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/hadoop-2.6.0/tmp/dfs/data
dfs.permissions.enabled
false
# vim /opt/hadoop-2.6.0/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapred.job.tracker
192.168.208.110:10020
# vim /opt/hadoop-2.6.0/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
2. eclipse运行mapreduce程序
hdfs://192.168.208.110:9000/tmp/input
hdfs://192.168.208.110:9000/tmp/output