ML-Agents安装教程(Unity机器学习/2020.6.30最新更新)
目录
1.安装Anaconda
2.在Anaconda中创建ML-agent环境,并更换Python版本
3.激活项目环境
4.安装Tensorflow
5.安装ML-Agent扩展工具
6.安装环境依赖
7.启动项目
8.开始训练
9. 查看训练结果
1.安装Anaconda
先贴一个官方安装教程。
关于安装Anaconda,之前写过相关教程:链接地址
注意,最新版的Anaconda默认配置Python版本为3.7,而目前ML-agent支持3.6版本,后面需要我们在项目环境中更换Python版本。
添加系统环境变量:在PATH中添加
%UserProfile%\Anaconda3\Scripts
%UserProfile%\Anaconda3\Scripts\conda.exe
%UserProfile%\Anaconda3
%UserProfile%\Anaconda3\python.exe2.在Anaconda中创建ML-agent环境,并更换Python版本
打开Prompt
conda create -n ml-agents python=3.6

出现以上结果代表安装成功。
3.激活项目环境
activate ml-agents4.安装Tensorflow
pip install tensorflow==1.7.1关于tensorflow版本,官方安装文档这样解释:TensorFlow的其他版本可能不起作用,因此您需要确保安装版本为1.7.1。
由于我当时安装网络不太稳定,并且电脑上有多个pip版本,自己用的下面这条指令安装的:
python -m pip --default-timeout=100 install tensorflow==1.7.1也可以更换镜像源下载,举个清华镜像的栗子:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==1.7.1
安装结果:
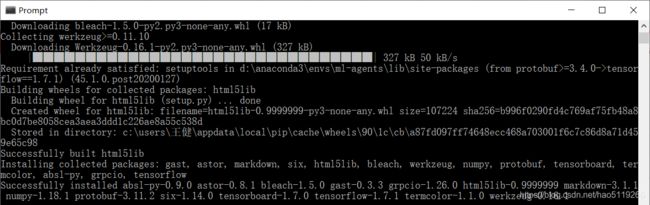
5.安装ML-Agent扩展工具
(1)使用git下载ml-agents工程文件:
git clone --branch latest_release https://github.com/Unity-Technologies/ml-agents.git或者通过此链接直接下载最新的ml-agents工程文件
注意自己的下载路径,后续训练要用到
(2)上一步完成后,再通过pip安装mlagent的Python扩展包
pip install mlagents官方文档中提到windows有时候会出现缓存不足(就是出现读取时间超时的提示)的情况,如果遇到可以通过以下命令安装
pip install mlagents --no-cache-dir当然,还是因为网络问题和环境问题,自己是这样安装的(因为ml-agents更新频繁,镜像下载不一定及时更新):
python -m pip --default-timeout=100 install mlagents安装结果:
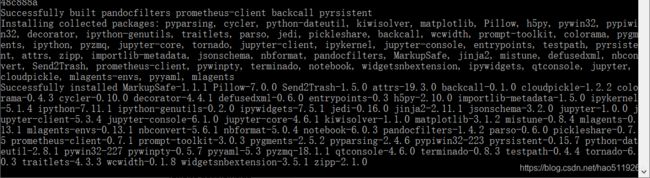
6.安装环境依赖
首先在cmd中找到之前的下载安装路径并激活ml-agents环境

(1)配置相关环境一
cd ml-agents
pip install -e ./安装完成提示
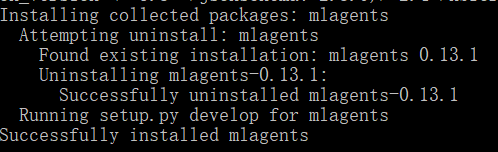
(2)配置相关环境二(别忘了返回路径)
cd ..
cd ml-agents-envs
pip install -e ./安装完成提示
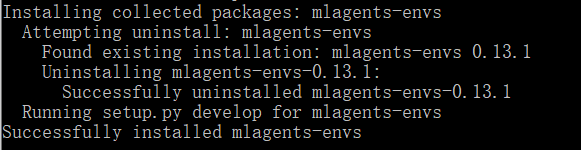
7.启动项目
(1)打开Unity
(2)打开新工程——打开下载的文件中的Unity SDK文件夹
(3)选择菜单Edit > Project Settings > Player
(4)选择对应平台:PC、IOS或者Android均可,并且运行环境选择(.NET 4.6 Equivalent 或者 .NET 4.x Equivalent)
8.开始训练
(1)检测1-6步是否安装成功
mlagents-learn如果任意路径此命令都不会出现错误提示,代表安装成功。
你应该会看到如下画面

(2)键入安装路径,激活环境,
![]()
然后输入
(此为前几个版本的训练指令):
mlagents-learn --run-id= --train 注意,官方最新的release doc给的训练指令为
mlagents-learn --env= --run-id= 此命令并非训练指令,如需训练请在结尾加上--train
mlagents-learn --env= --run-id= --train 同样

就我自己的情况就是:
mlagents-learn config/ppo/3DBall.yaml --run-id=3DBall --train第一次运行还碰到了Window的防火墙提示,允许后再次运行此命令就行了。
OK,如果出现让你启动Unity Play按钮的提示,就代表配置大功告成了:

Unity中点击Play运行,应该会看到如下提示:
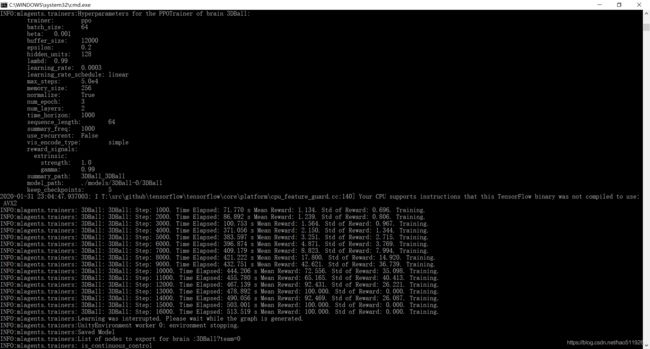
Unity中训练画面:

可以看到后面的都是训练结果:
2020-06-30 14:06:06 INFO [stats.py:111] 3DBall: Step: 12000. Time Elapsed: 17.647 s Mean Reward: 1.193. Std of Reward: 0.776. Training.
2020-06-30 14:06:15 INFO [stats.py:111] 3DBall: Step: 24000. Time Elapsed: 26.153 s Mean Reward: 1.256. Std of Reward: 0.764. Training.
2020-06-30 14:06:23 INFO [stats.py:111] 3DBall: Step: 36000. Time Elapsed: 34.166 s Mean Reward: 1.548. Std of Reward: 1.008. Training.
2020-06-30 14:06:32 INFO [stats.py:111] 3DBall: Step: 48000. Time Elapsed: 43.122 s Mean Reward: 2.247. Std of Reward: 1.422. Training.
2020-06-30 14:06:40 INFO [stats.py:111] 3DBall: Step: 60000. Time Elapsed: 51.094 s Mean Reward: 3.385. Std of Reward: 2.459. Training.
2020-06-30 14:06:47 INFO [stats.py:111] 3DBall: Step: 72000. Time Elapsed: 58.951 s Mean Reward: 6.397. Std of Reward: 5.280. Training.
2020-06-30 14:06:55 INFO [stats.py:111] 3DBall: Step: 84000. Time Elapsed: 66.782 s Mean Reward: 14.555. Std of Reward: 17.268. Training.
2020-06-30 14:07:04 INFO [stats.py:111] 3DBall: Step: 96000. Time Elapsed: 75.288 s Mean Reward: 27.898. Std of Reward: 17.444. Training.
2020-06-30 14:07:13 INFO [stats.py:111] 3DBall: Step: 108000. Time Elapsed: 84.793 s Mean Reward: 75.456. Std of Reward: 33.044. Training.
2020-06-30 14:07:21 INFO [stats.py:111] 3DBall: Step: 120000. Time Elapsed: 92.778 s Mean Reward: 92.992. Std of Reward: 16.129. Training.
2020-06-30 14:07:33 INFO [stats.py:111] 3DBall: Step: 132000. Time Elapsed: 105.000 s Mean Reward: 96.162. Std of Reward: 10.186. Training.
2020-06-30 14:07:42 INFO [stats.py:111] 3DBall: Step: 144000. Time Elapsed: 113.634 s Mean Reward: 100.000. Std of Reward: 0.000. Training.
2020-06-30 14:07:49 INFO [stats.py:111] 3DBall: Step: 156000. Time Elapsed: 120.907 s Mean Reward: 100.000. Std of Reward: 0.000. Training.
2020-06-30 14:07:57 INFO [stats.py:111] 3DBall: Step: 168000. Time Elapsed: 128.464 s Mean Reward: 97.133. Std of Reward: 9.508. Training.
2020-06-30 14:08:04 INFO [stats.py:111] 3DBall: Step: 180000. Time Elapsed: 135.820 s Mean Reward: 95.838. Std of Reward: 13.877. Training.
2020-06-30 14:08:12 INFO [stats.py:111] 3DBall: Step: 192000. Time Elapsed: 143.559 s Mean Reward: 100.000. Std of Reward: 0.000. Training.
2020-06-30 14:08:20 INFO [stats.py:111] 3DBall: Step: 204000. Time Elapsed: 151.464 s Mean Reward: 100.000. Std of Reward: 0.000. Training.旧:
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 1000. Time Elapsed: 71.770 s Mean Reward: 1.134. Std of Reward: 0.696. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 2000. Time Elapsed: 86.892 s Mean Reward: 1.239. Std of Reward: 0.806. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 3000. Time Elapsed: 100.753 s Mean Reward: 1.564. Std of Reward: 0.967. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 4000. Time Elapsed: 371.056 s Mean Reward: 2.150. Std of Reward: 1.344. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 5000. Time Elapsed: 383.597 s Mean Reward: 3.251. Std of Reward: 2.715. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 6000. Time Elapsed: 396.874 s Mean Reward: 4.871. Std of Reward: 3.769. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 7000. Time Elapsed: 409.179 s Mean Reward: 8.823. Std of Reward: 7.994. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 8000. Time Elapsed: 421.222 s Mean Reward: 17.800. Std of Reward: 14.920. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 9000. Time Elapsed: 432.751 s Mean Reward: 42.621. Std of Reward: 36.739. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 10000. Time Elapsed: 444.206 s Mean Reward: 72.556. Std of Reward: 35.098. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 11000. Time Elapsed: 455.780 s Mean Reward: 65.165. Std of Reward: 40.413. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 12000. Time Elapsed: 467.139 s Mean Reward: 92.431. Std of Reward: 26.221. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 13000. Time Elapsed: 478.892 s Mean Reward: 100.000. Std of Reward: 0.000. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 14000. Time Elapsed: 490.056 s Mean Reward: 92.469. Std of Reward: 26.087. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 15000. Time Elapsed: 503.001 s Mean Reward: 100.000. Std of Reward: 0.000. Training.
INFO:mlagents.trainers: 3DBall: 3DBall: Step: 16000. Time Elapsed: 513.519 s Mean Reward: 100.000. Std of Reward: 0.000. Training.中间可以通过Ctrl+C来终止训练
9. 查看训练结果
终止训练后,训练结果会保存到:results/
运行结果会提示你训练的.nn文件保存至哪里
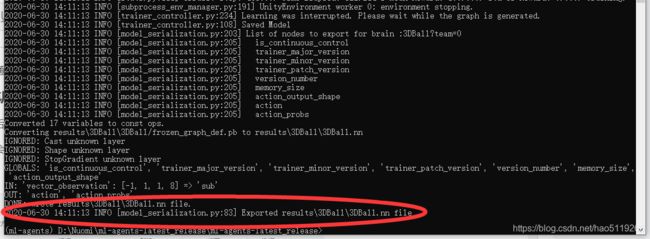
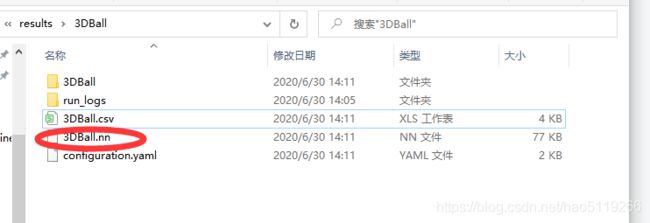
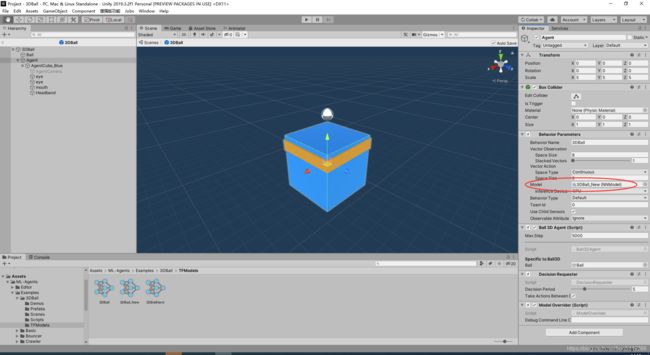
然后,我们把此文件命名为3DBall_New.cnn,把此文件拖入Unity此路径下 :Project/Assets/ML-Agents/Examples/3DBall/TFModels/
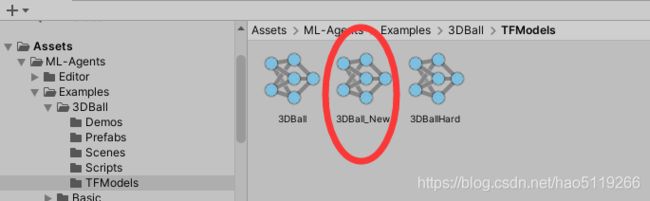
按下图所示替换,然后再次运行游戏场景即可(注意要替换预制体中的而不是游戏场景中的)。
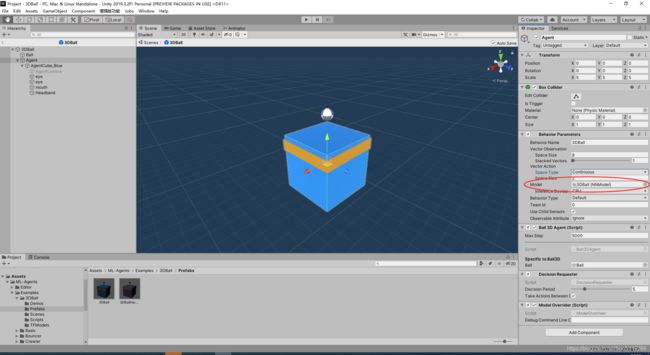
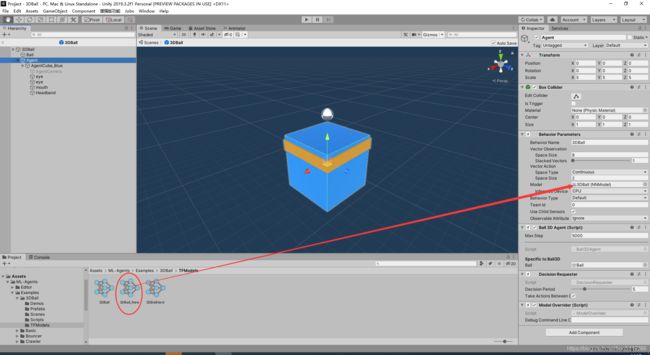
替换完成训练结果
不懂的地方留言提问吧
码字不易,求赞~