(PaddlePaddle 论文复现) Few-shot Video-to-Video Synthesis解读(一) 起源
PaddlePaddle 论文复现
课程链接 https://aistudio.baidu.com/aistudio/education/group/info/1340
Few-shot Video-to-Video Synthesis解读(一) 起源
Few-shot Video-to-Video Synthesis使用了GAN的基础原理,在应用领域上,可以分类到图像翻译。既然为图像翻译领域,自然绕不过,它的三位前辈,也是其实现基础的3篇论文。pix2pix,pix2pixHD,vid2vid
这只是一个大纲,后续还有很多不严谨的地方需要修改
CGAN
pix2pix是图像翻译的开山之作,虽说是开山之作,但是其并非提出了全新的思想。其思想来源源于GAN的变体——CGAN(conditional GAN)。
这里简单介绍一下CGAN的特点,CGAN不同于传统的GAN(以DCGAN为代表),在其输入流中引入了条件变量 X 。DCGAN中,生成器的全部数据都来源于Gaussian Noise,而判别器则收到不同的数据分别是real data 和生成器生成的fake data。而在CGAN中,条件变量被添加到Gaussain Noise和real data中,因此,生成器生成的fake data将受到条件变量 X 的影响(或者称为条件约束)。而CGAN的核心就在于此,由于Gaussian Noise的每次生成的具体值是不固定的,我们只是通过设计一个数据分布,从中进行采样得到的输入数据。所以对于数据的性质(或者说各个维度表示的特征的意义)的影响是不可知的。数据分布,描述的是一组数据的分布规律,对于当个数据,数据分布是没有意义的,我们更关心的单个数据的维度(dimension),因为每一个维度,都可能具有一个实际的物理意义,同时影响着输出的结果。另一方面,由于Gaussain Noise的随机属性,使得其具有很好的泛化意义,即不具有指向性,适合做生成数据。但是,当我们需要对数据添加指向性的时候,这也就成为了一个重要的问题。而条件变量 X 则就是解决这个问题的一种方法。
条件变量 X 不用于Gaussain Noise,由于其是人为引入的,因此,我们可以确定变量的属性,从而直接影响生成器的生成方向。这一点是CGAN的核心。从数学上说,条件变量 X 的引入,使得GAN模型由生成模型P(Z,Y)转变为P(Z,Y|X)。其中,Z为Gaussian Noise 而 Y为real data。通过改变条件变量 X, 则可以改变输出的结果,从而让模型更加可控。
1.pix2pix
在pix2pix中,简单定义了图像翻译的任务。作者将CGAN的应用领域描述为图像映射(Mapping),将条件变量 X 和Gaussain Noise 映射到 real data Y中。在论文中,X使用的语义图像,而real data则是与语义图像对应采集的RGB图像。相比之下,语义图像更加模糊,同一语义的object,使用同样的色块的标注,失去了很多的细节。而利用CGAN的技术,以语义图像进行约束,使得生成器的能够在语义图像上,较快地生成object的轮廓。而通过real data和Gaussian Noise的对抗,能够生成object上的细节。
作者比较了不使用Gaussian Noise,直接输入条件变量 X 的网络,发现直接输入条件变量 X 的方式效果并不理解。此外,作者还指出了使用L1正则化,能够比L2正则化达到更好的去模糊效果。
在网络构架上,作者和传统的GAN一样,使用Conv-BatchNorm层,作为基本卷积层。但是,在网络构架上,使用了不同的技巧。对于生成器,根据任务要求,作者提出了两种网络构架进行特征生成,一种是传统的AutoEncoderd网络。虽然AutoEncoder能够较好实现低维信息的映射(Mapping),但是其bottleneck结构带来一定程度的信息损失,为了解决这个问题,作者在这个基础上加入了skip-connect,并按照 U-net 的构架进行设计。对于判别器,使用L1正则化能够很好的分辨low-frequencies特征,但是对于high-freqencies则不能有效提取,针对这一情况,作者又引入了Patch的概念,将判别器设计成PatchGAN的模式,使其能够区分一些high-frequencies的特征。

2.pix2pixHD
pix2pixHD是在pix2pix的基础上发展而来的,其主要聚焦的问题是如何生成更加高清(HD)的图像。作者在文中指出,pix2pix生成图像模糊的原因来源于其训练的不稳定,和优化问题。
作者的贡献主要在以下两个方面:
- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式,这一点不同于pix2pix中使用dropout保证输出的多样性。
对于生成器,作者为了加强生成器生成图像的质量(HD),需要同时提取全局特征和局部特征,pix2pix中的生成器仅仅能够提取全局特征,难以有效提取较小的局部特征。针对这样的情况,作者设计了两个不同的网络构架G1和G2,共同组成了生成器G,且G1和G2相互交替。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。

不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:

- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
这个方法将CGAN的思想发挥到了极致,pix2pix中的条件变量 X ,是固定的,由我们人工选取输入的,从一定程度上说 X 更接近于常量,一旦赋值后就不再改变。但是在pix2pixHD中,条件变量 X 变成了一个隐变量,其隐藏在输入数据中,并并由输入数据决定,我们是通过Auto Encoder从中提取到的隐变量并作为条件变量输入的,这在很大程度上减少了人为干涉和工作量,而且一般来说,通过神经网络得到的变量更加准确的接近输入的抽象特征。
3.vid2vid

作者在文中指出,vid2vid是对imag to image translation在视频方向的补充。对于vid2vid,主要难点在于生成的视频很难保证前后帧的一致性,容易出现抖动。为了解决视频抖动这一问题,作者利用了传统方法的思路——引入光流。同时,vid2vid是基于pix2pixHD的模型演变而来的,因此其生成的video具有很高的分辨率和清晰度。最终的结果是实现了2K分辨率,30秒长的视频。
vid2vid的模型构架相对复杂,因为其处理对象由过去的real data Y 和 条件变量 Z 等图像,拓展为 Y 序列 和 Z 序列,引入时间维度的变化。同时,作者简化了序列中帧与帧之间的关系,假定帧与帧之间为遵循马尔可夫假设,这使得在数学上就可以使用条件概率进行递推展开。

作者精心设计了一个独特的loss函数,其函数式相对复杂

上面这个公式有三个未知量 这三个未知量都是通过学习一个CNN得到的。
Wt-1 表示t-1帧到t帧的光流,光流的计算通过学习一个CNN来实现。
Wt-1(Xt-1) 表示利用t-1帧光流信息预测得到的第t帧的输出
ht表示当前帧的输出结果,也是利用CNN来实现。
mt 表示输出结果的模糊程度。
最终输出的结果由 Wt-1(Xt-1) 和ht 加权得到。二者的权重通过学习一个CNN来实现,权重代表 Wt-1(Xt-1) 生成结果的模糊程度,越模糊,则 Wt-1(Xt-1) 的比重越低。
这个思路很好理解,既然直接生成的原始图像没有考虑光流约束可能造成时序不一致,而仅仅使用光流wrap得到下一帧图像在多帧图像之后容易造成累计误差,且当图像出现遮挡或者移出画面会造成预测不准确,那么直接将这两种方法生成的图像融合在一起就可以了,融合的方法也很简单,就是把这两部分的结果加权平均,而这个权重就是 mt ,是一个与生成图像一样大小的map(mask),这样图像的不同区域还可以使用不同的权重。这个 mt 也是网络自己学出来的。
在这里需要指出的是,这里的很多参数都是通过其他网络训练出来的,因此相当于融合了多个网络。且这些网络之间是乘性的操作,而不是像过去一样采用简单的串联/并联操作。
在判别器中,作者使用了两个判别器,一个是图像粒度的判别器。这个比较简答,使用CGAN。 另一个是视频粒度的判别器。输入为视频序列及其光流信息,同样输入到CGAN。
最后,作者还尝试对视频中的前景和背景进行分别建模,以期加快速度。从最后的结果上课,确实起到了很好的作用。
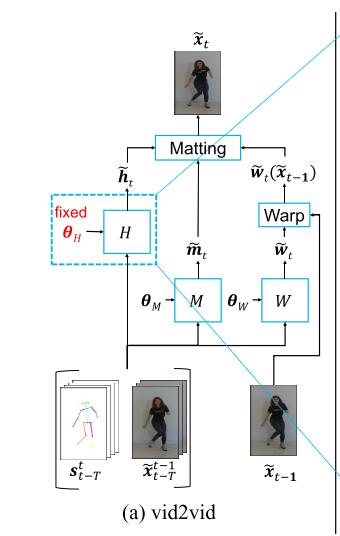
可以看到,虽然只有2个输入流,但是却对应3种数据的输入,使用了H,M,W 三个网络提取不同的特征,其融合机制也不是简单的concat,结构其实相对复杂。
上述的图像翻译三部曲,已经将图像翻译的模型建好了。剩下的就是对原有模型的修修补补了。
那么,Few-shot Video-to-Video都进行了哪些改进?
还是从题目入手,题目中最明显的改变就是Few-shot,中文翻译为“小样本训练”。所谓“小样本”训练是和“大样本训练“相对的。一般来说,一个模型的能力很大程度都是来源于数据的复杂度,样本数据越大、越多,模型的拟合能力越强,这一点在复杂模型上表现尤为明显。但是,在实际过程中,”大样本”从来都是缺乏的。这里的缺乏,指的的是缺乏经过合理的预处理过,符合规范的数据。也许数据很多,但是数据的预处理成本过高,例如,打标签,这样就使得大量的数据无法使用。相比之下,就显示出“小样本训练”的优势,利用有限的数据,花费更长的时间得到相同的效果。针对few-shot,发展出了终生学习(Long life learning),这即使另外一个话题了。
Ref:
https://zhuanlan.zhihu.com/p/56808180
https://zhuanlan.zhihu.com/p/90363315