学习笔记 | 核心网KPI异常检测
核心网KPI异常检测
业务目标
- 核心网在运营商网络中位置高,很少发生故障。但一旦发生故障,对全网稳定性和服务质量影响很大,另外,有时候网络问题只影响小部分用户,此时没有显性告警,只有当用户服务质量受损、投诉时才发现,在核心网网元 upgrade、关键配置修改时,需要快速发现网络异常,及时回退,核心网网元种类多,复杂网元 KPI 达数千个,人工难以全面精确识别故障异常,云核 KPI 数量多, 固定阈值维护复杂,精确度不高,无法支撑故障初期快速识别,这些问题都是由于传统的 KPI 监控无法及时的发现问题而产生的。
- 随着大数据技术的发展,我们可以结合大数据新技术建立 KPI 异常智能监控,及时预测以及发现异常 KPI,有效的高的网络的良好运行。
实验数据
- 通信系统中 ATS: 通用语音业务网元主要上报核心网的语音业务网元 KPI 信息。
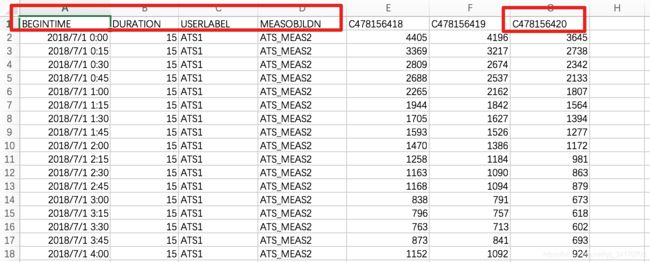
- 有“BEGINTIME”、“DURATION”、“USERLABEL”、 “MEASOBJLDN”和“C478156420”列。


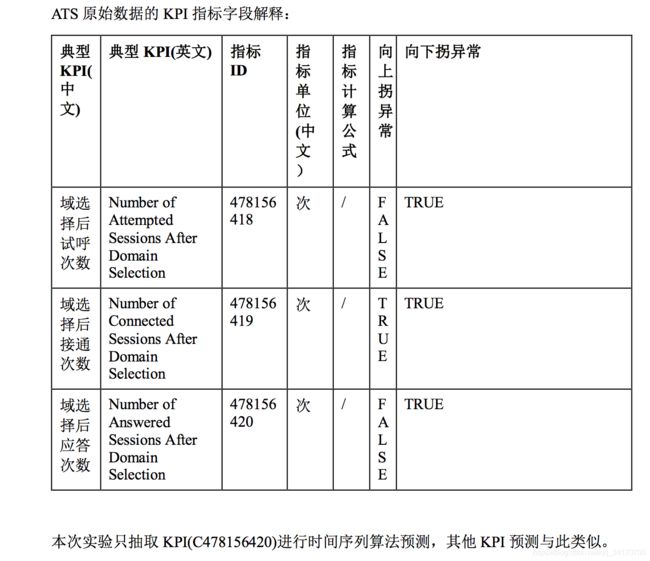

- 该场景目标为判断 KPI 的异常值,属于异常点检测问题,但是数据是时间序列数据, 故选择时间序列预测算法。本实验以 ARIMA 为例,该算法实现简单、不需做特征选 择,且有训练速度快等优势。
- 导入的 ATS 原始数据,需要按照时间维度进行分隔,前三十天的数据,用于生成训练集。最后一天的数据,用于生成测试集。分别需要创建用于生成训练集的特征工程和用于生成测试集的特征工程。
01 特征构建算法——生成训练集
- ATS 原始数据中列出了 31 天的数据,需要将前 30 天的数据拆分出来作为训练集。
下述代码就是过滤出前 30 天的数据。
# -*- coding: utf-8 -*-
# Automatically generated code template for feature operation 'time_fiter'
import pandas as pd
from datetime import datetime
# Real custom feature operation
# args:
# data: input pandas dataframe
# return:
# output pandas dataframe
def feature_op(data):
cond_start_time=datetime.strptime("2018/07/31 00:00:00","%Y/%m/%d %H:%M:%S")
data['BEGINTIME']=pd.to_datetime(data['BEGINTIME'],format="%Y/%m/%d %H:%M:%S")
data=data.loc[(data.BEGINTIME<cond_start_time)]
return data
02 特征构建算法——生成测试集
- 数据集界面仅导入了一份 ATS 原始数据,需要拆分出最后一天的数据生成测试集。
下述代码就是过滤出最后一天的数据,即 7 月 31 号的数据。
# -*- coding: utf-8 -*-
# Automatically generated code template for feature operation 'time_fiter'
import pandas as pd
from datetime import datetime
# Real custom feature operation
# args:
# data: input pandas dataframe
# return:
# output pandas dataframe
def feature_op(data):
cond_start_time=datetime.strptime("2018/07/31 00:00:00","%Y/%m/%d %H:%M:%S")
data['BEGINTIME']=pd.to_datetime(data['BEGINTIME'],format="%Y/%m/%d %H:%M:%S")
data=data.loc[(data.BEGINTIME>=cond_start_time)]
return data
03 训练算法 - KPI
# -*- coding: utf-8 -*-
# Automatically generated simple classification code for algorithm kpiprediction
from __future__ import print_function
from naie.datasets import get_data_reference
from naie.context import Context
from naie.metrics import report
from threading import Thread
from time import sleep
from sklearn.metrics import *
from sklearn.neural_network import MLPClassifier
import moxing as mox
import os
import pickle
import string
import pandas as pd
import numpy as np
import pandas as pd
import numpy as np
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.stattools import arma_order_select_ic
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.tsa.seasonal import seasonal_decompose
# Get parameters from training configuration
def get_params():
'''获取文件路径函数'''
train_data = get_data_reference(Context.get('train_data')['dataset'], Context.get('train_data')['entity']).get_files_paths()[0]
return train_data
# Load data by dataset entity name
def load_data(data_path):
'''加载数据函数'''
with open(data_path, 'r') as f:
df = pd.read_csv(f)
return df
def interpolate_demo(series):
'''空值处理函数'''
print('empty values:%s' % np.isnan(series).sum()) #判断数据集的空值
series1 = series.interpolate(method='linear') #用线性方法进行空值填充
print('after linear interpolate, empty values:%s' % np.isnan(series1).sum())
series2 = series.interpolate(method='nearest') #用邻近数据均值进行空值填充
print('after nearest interpolate, empty values:%s' % np.isnan(series2).sum())
return series2
def denoise_3sigma(series):
'''3sigma异常点检测函数'''
array_data = series.values
array_data =[float(i) for i in array_data] #数据集格式转换
mu = np.mean(array_data) #数据集均值
sigma = np.std(array_data) #数据集方差
up_bound = mu + 2*sigma
low_bound = mu - 2*sigma
for i in range(len(array_data)):
item = array_data[i]
if (item > up_bound) or (item < low_bound):
array_data[i] = np.nan
print('after 3sigma denoise, empty value is %s' % np.isnan(array_data).sum()) #讲超出2sigma上下边界点的设置为空,便于统计异常点
series = pd.Series(array_data)
series = series.interpolate(method='linear') #用插值法处理空值
return series
def denoise_boxplot(series):
'''boxplot异常点检测函数'''
array_data = series.values
q1 = np.percentile(array_data, 25)
q3 = np.percentile(array_data, 75)
delta = (q3 - q1) / 2.
iqr = delta * 1.5
up_bound = q3 + iqr
low_bound = q1 - iqr
for i in range(len(array_data)):
item = array_data[i]
if (item > up_bound) or (item < low_bound):
array_data[i] = np.nan
print('after boxplot denoise, empty value is %s' % np.isnan(array_data).sum())
series = pd.Series(array_data)
series = series.interpolate(method='linear')
return series
def diff_series(series):
'''计算差分函数'''
result = list()
for i in range(len(series)-1):
result.append(series[i+1]-series[i])
return result
def stationary_test(series):
'''计算差分阶数d的取值函数'''
stationary_array = series.values
for i in range(5):
if i > 0:
stationary_array = diff_series(stationary_array)
adftest = adfuller(series)
adf = adftest[0]
adf_p = adftest[1]
if adf_p > 1e-4:
continue
threhold = adftest[4]
percent1_threshold = threhold.get('1%')
if adf < percent1_threshold:
break
return i
def arima_demo(series):
'''arima算法建模函数'''
d = stationary_test(series) #确认参数d
'''
l-bfgs algorithm to find best AR(p) MA(q), D(diff) is already find in function stationary_test
'''
(p, q) = (arma_order_select_ic(series, max_ar=3, max_ma=3, ic='aic')['aic_min_order'])
print('arma parameter:p-%s,q-%s,d-%s' % (p, q, d)) #自动化定阶参数去q和p
arma = ARIMA(series, (p, d, q)).fit(disp=0, method='mle') #模型训练
results = arma
#results.aic
#results.summary()
array_data1 = series.values
array_data1 =[float(i) for i in array_data1]
array_data2 = results.predict() #输出预测值
error = mean_squared_error(array_data1,array_data2) #计算评估指标MES
return arma.resid,error,arma
def anomaly_3sigma(resid):
'''用3sigma异常点检测方法检测残差的异常值函数'''
resid = abs(resid)
mu = np.mean(resid)
sigma = np.std(resid)
up_bound = mu + 3 * sigma
low_bound = mu - 3 * sigma
anomaly_idx = list()
for i in range(len(resid)):
item = resid[i]
if (item > up_bound) or (item < low_bound):
anomaly_idx.append(i)
return anomaly_idx
def print_error(df, anomaly_idx):
'''输出异常点函数'''
for item in anomaly_idx:
record = df.iloc[item, :]
print(record)
# Save the model
def save_model(clf):
with open(os.path.join(Context.get_output_path(), 'model_clf.pkl'), 'wb') as mf:
pickle.dump(clf, mf) #打包模型
# Score the model
def score_model(error, logs):
'''评估指标输出函数'''
logs.log_property("mse", error)
# Run
def main():
# logs = LogReport(True)
train_data = get_params() #获取文件路径
df = load_data(train_data) #加载数据集
series = df[['BEGINTIME','C478156420']] #选取需要特征
series['BEGINTIME'] = pd.to_datetime(series['BEGINTIME'])
series.set_index("BEGINTIME", inplace=True) #时间特征作为索引
series = interpolate_demo(series) #空值处理
series = denoise_3sigma(series) #2sigma异常值处理
series = denoise_boxplot(series) # boxplot异常值处理
arma_resid,error,arma = arima_demo(series) #arima数据建模
print_error(df.loc[:, ['BEGINTIME', 'C478156420']], anomaly_3sigma(arma_resid)) #输出异常点检测结果
print(error) #输出评估指标
save_model(arma) #保存模型
with report(True) as logs:
score_model(error, logs) #保存评估指标
# logs.log_end()
if __name__ == '__main__':
main()
- ATS 原始数据集中,总共有 7 个真实的异常点,通过 ARIMA 算法进行 KPI 时序 预测之后,在运行日志中可以查看,异常点的个数和每一个异常点的信息(时 刻、具体值)。

04 验证算法 - KPI
# -*- coding: utf-8 -*-
from __future__ import print_function
from naie.context import Context
from naie.datasets import get_data_reference
from naie.metrics import report
from sklearn.externals import joblib
from sklearn.metrics import *
import pandas as pd
import os
import numpy as np
import pickle
if __name__ == '__main__':
data_reference = get_data_reference(dataset=Context.get('validation_data')['dataset'], dataset_entity=Context.get('validation_data')['entity'])
val_data = data_reference.to_pandas_dataframe()
label_column = Context.get('validation_data')["label"]
Y = val_data[label_column]
print(Y)
#val_data = val_data.loc[:, val_data.columns != label_column]
model_path = Context.get_package_path()
print(model_path)
clf_path = ""
for f in os.listdir(model_path):
if f.endswith(".pkl"):
clf_path = os.path.join(model_path, f)
break
print(clf_path)
with open(clf_path, 'rb') as ff:
model = pickle.load(ff)
val_result = model.forecast(len(Y))
yhat = val_result[0]
with report(True) as logs:
logs.log_property("MSE", mean_squared_error(Y,yhat))
- MSE 是均方误差函数,一般用来检测模型预测值与真实值之间的偏差。值越小,说明偏差越小。
