Proposal, Tracking and Segmentation (PTS)论文解读和代码解读
这是一篇在arxiv7月2号新上的一篇论文,做视频目标分割的。论文本身没有什么太多的创意,使用现有的一些模块组合,提出了一种串联结构,把VOS任务分成三步骤,每一步骤对应一个模块,最后的结果达到了state of the art 的效果。
论文地址
开源地址
overview
作者将VOS分层三个步骤
- object proposal network : 先用mask rcnn开源的RPN,通过IOU可以挑选出属于特定目标的候选框,挑选出k个。
- object tracking network : 上一步得到的K个候选框,送入到一个分类网络(MDNet)作为判别器,去判别这些候选框的质量如何。筛选出最好的5个。之后把这5个框的坐标都取平均,作为最后的当前帧的目标区域。
- Dynamic Reference Segmentation Network :上一步得到的最终的目标区域送入到一个分割头网络(seg head)里面,同时结合了mask rcnn得到的粗略mask,第一帧的image pair(图像和预测的percise mask)和第t-2的 image pair,第t-4帧的image pair的结果。
再更细的解释一下第一步的过程。第一步之所以用IOU,是因为RPN是对全部的目标提取潜在(potential)的目标候选框,但VOS仅仅针对特定的几个目标或者一个目标。通过IOU,得到所有候选框和上一帧预测区域的符合程度,挑选出IOU大于0.6的作为当前帧目标可能存在的位置。
image pair的意思是:一个从原图crop出来的候选框区域和这个候选框区域对应的预测mask。
所以说整个方法,实质没有创新,没有提出一个新的学习方法,使用串行结构(现有模块)解决了VOS任务。更像是解决了技术问题,不是提出一种新方法。不过还是感谢作者们的贡献和开源。
整体速度应该不会太快,而且实现复杂,连作者都用了 effective这个词形容PTSNet而不是efficient。论文的方法需要FineTuning,所以不能线上运行了。
architecture
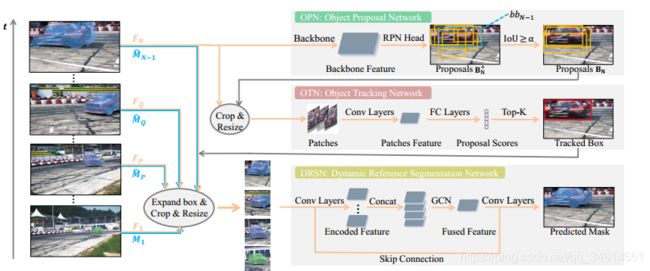
蓝色线是mask,黄色线是crop出来的目标区域,这两组成image pair。注意当前帧使用上一帧预测的mask作为image pair的mask成员。当前帧 F n F_n Fn(黄色线)送到OPN中经过RPN得到候选框,根据 I O U > a IOU > a IOU>a挑选出合适的候选框。然后跟着右上角灰色线走,这些被挑选出的候选框经过合适的Resize之后,送入到OTN中(论文中用MDNet,一个跟踪网络),继而挑选出Top -k 的框。然后平均一下这个k个框,结合上一帧的mask组成image pair,还有第Q帧的image pair,第P帧的image pair,和第一帧的image pair,送入到DRSN中,获得分割结果。
Q为当前帧号-2,P为当前帧号-4。
OPN

RPN就不在多少,上面的图是经过IOU之后挑选出来的框,可以发现框的质量还是不错的,确实包含了特定的目标。
Object Tracking Network
这一步就是indentify候选框质量的过程。MDNet结构被完全保留下来,先在DAVIS2017数据集上做预训练。(非常重要,就是说MDNet在PTS中起到的作用就是一个二分类的效果),在使用的时候,候选框resize成合适的尺寸(符合MdNet的要求),然后送进网络,得到正例的概率,选取最大的k个概率对应的候选框,再平均一下坐标。OK,这就是OTN的输出了。
note: OTN中使用到的MDNet也是要使用长短时更新的。top -k个框对应的概率如果相加大于0,则代表成功找到合适的候选框,进行短时更新;如果小于0,说明这k个框都不合适,则进行长时更新。
Dynamic Reference Segmentation Network
如果非要说论文的创新点在哪,我愿意把创新点归结到这里。
从OSVOS,maskTrack到如今的siammask,MOTS和PTSNet,代表了VOS从静态图像发展到利用动态信息,多帧的联系。以往基于单帧的办法,是靠appearance。现在一些方法行之有效,证明了在video任务中,建模多帧之间的联系是很重要的。作者认为,第一帧的mask可以提供很可靠,但同时不具有最新的形象特征(比如视频开头走过来一个人,看到的是正面,人走过了,就只能看见背面了)。现在想引入多帧的信息,尽管除了第一帧,后面的帧的image pair的mask可能不准确,但作者认为,仍然可以提供有效的appearance cues。
四帧的image pair都通过resnet50,最后在GCN处,在通道轴拼接,送到全卷机网络中,输出通道数为2的最终预测。
训练方法
整个过程不是不是端到端训练的。
- RPN来自在COCO中预训练的模型,且参数固定,就是不参加训练的意思。RPN的NMS被移除,来获得大概2000个框,这2000个框和上一帧的prediction外接的矩形框计算IOU,挑选出IOU大于a的框,a设置为0.3
- OTN采用MDNet,把长时更新的帧数变成了20,短时更新的帧数变成了5。
- DSRN,ResNet50是pretrained的,输入图像为4256256,4是指三通道的图像和1通道的掩码,所以ResNet的第一层的所有卷积核都要加上一个通道,和MaskTrack加通道的方法类似。另外,和MaskTrack类似的还有,该模块需要online finetuning,方法是在预测一个序列之前,用第一帧和其mask产生image -pair对。其他设置和训练保持一致。
代码解读
我们只看看DRSN的部分。
def forward(self, ref_imask, p_imask, q_imask, x):
_, _, h, w = x.size()
visual_fea_list = []
for g_imask in [ref_imask, p_imask, q_imask]:
visual_fea_list.append(self.generate_visual_params(g_imask))
visual_features = torch.cat(visual_fea_list, 1)
feas = self.features(x)
x = torch.cat((feas[-1],visual_features), 1)
x = self.GCB(x)
x = self.RM1(x, feas[-2])
x = self.RM2(x, feas[-3])
x = self.RM3(x, feas[-4])
x = self.dropout2d(x)
out = F.upsample(input=self.classfier(x), size=(h, w), mode='bilinear')
return out
首先就是四个输入依次送入resNet50,获得stage5的输出,然后concat,送到GCB中串行 送到3个RM模块。