Naive Bayes分类器详解
1. 贝叶斯定理
假设随机事件 A A 发生的概率是 P(A) P ( A ) ,随机事件 B B 发生的概率为 P(B) P ( B ) ,则在已知事件 A A 发生的条件下,事件 B B 发生的概率为:
如果事件 A A 和事件 B B 相互独立,则 P(A|B)p(B)=P(AB) P ( A | B ) p ( B ) = P ( A B ) ,上式可以写为:
其中 P(A|B) P ( A | B ) 、 P(P(B)) P ( P ( B ) ) 、 P(A) P ( A ) 称为 先验概率, P(B|A) P ( B | A ) 称为 后验概率。下面举一个小小的例子来进行说明(引用知乎上的,简化了一下,原文在 这里)。
假设某城市发生了一起骑车撞人逃跑事件,该城市只有两种颜色的车,蓝色 15% 15 % ,绿色 85% 85 % ,事发时有一个人在现场看见了,他指证是蓝车。但是根据专家在现场分析,当时那种条件能看正确的可能性是 80% 80 % 。那么,肇事的车是蓝车的概率到底是多少?
令事件 A A 为证人看到车子是蓝色的事件,事件 B B 为车子是蓝色的事件,则事件 P(B|A) P ( B | A ) 表示在已知证人看到车子的条件下,该肇事车辆确实是蓝色的概率,即我们要求的概率。
好了,现在,如果没有证人看到肇事者车的话,那么我们只能盲猜,因此肇事者的车子为蓝色的概率只能是整个城市里面车为蓝色的概率,也就是先验概率P(B)=0.15,因为这时我们还没有其他证据介入,只能做个粗略的估算。
接下来,当当当当,有证人了。证人说他看到了车子,并且说是蓝色的,注意,这分两种情况:贝叶斯里面现象(新的证据)部分总是分两种情况出现的:
一是车子的确是蓝色的,并且证人也正确的分辨出车是蓝色的来了,概率为:
P(A|B)=P(B)⋅P(A|B)=0.15⋅0.8=0.12 P ( A | B ) = P ( B ) ⋅ P ( A | B ) = 0.15 ⋅ 0.8 = 0.12二是车子根本就是绿色的,只是证人看成蓝色的了,概率为:
P(A|¬B)=P(¬B)⋅P(A|¬B)=P(¬B)⋅(1−P(¬A|¬B))=0.85⋅(1−0.8)=0.17 P ( A | ¬ B ) = P ( ¬ B ) ⋅ P ( A | ¬ B ) = P ( ¬ B ) ⋅ ( 1 − P ( ¬ A | ¬ B ) ) = 0.85 ⋅ ( 1 − 0.8 ) = 0.17
所以
其中 P(¬B) P ( ¬ B ) 表示车子是绿色的概率, P(¬A|¬B) P ( ¬ A | ¬ B ) 表示车子确实是蓝色但证人看成绿色的概率。
然后,我们要求解的其实是在有证人的条件下车子为蓝色的概率,也就是
P(B|A) P ( B | A ) 根本就是 P(B) P ( B ) 的加强版本,条件概率跟先验概率描述的根本就是同一件事。
那么当当当当,又一个结论来了:当有新的证据出现时, P(B|A) P ( B | A ) 会替代原来 P(B) P ( B ) 的角色。换句话说,现在警察找到了一个新的证人,他也觉得这辆肇事车是蓝色的,这时在新一轮的贝叶斯概率计算中,基础概率 P(B)=0.41 P ( B ) = 0.41 ,而不是原先的 0.15 0.15 ,大家可以算一下,新的 P(B|A)=0.735 P ( B | A ) = 0.735 ,换句话说,当有两个人看见肇事车辆为蓝色的时候,对比只有一个人看到肇事车辆为蓝色的时候,该车实际为蓝色的概率大大增加。
2. 一般意义下的贝叶斯分类器
贝叶斯分类器属于一种生成学习算法。对于二分类的时候,其实我们是把标签为0和标签为1的样本分别取出来,建立两个模型 model0 m o d e l 0 和 model1 m o d e l 1 ,最后在预测新的样本的类别的时候,我们会把样本的特征分别带入 model0 m o d e l 0 和 model1 m o d e l 1 ,哪个模型拟合的好,则该样本就属于哪个模型。贝叶斯公式变为:
而:
因此上式写为:
如何属性 xi x i 之间互相独立,则:
因此后验概率为:
其中 P(y=1) P ( y = 1 ) 是训练样本中标签为 1 1 的样本比率, P(y=0) P ( y = 0 ) 表示标签为 0 0 的样本的比率, P(xi|y=1) P ( x i | y = 1 ) 表示所有的标签为 1 1 的样本中, xi=1 x i = 1 的样本所占的比率, P(xi|y=0) P ( x i | y = 0 ) 表示所有标签为 0 0 的样本中 xi=1 x i = 1 的比率。
3. 拉普拉斯平滑
拉普拉斯平滑(Laplace Smoothing)主要是为了解决概率为0的问题,如果样本中变量 xk x k 的取值全部为0,即 P(xk|y)=0 P ( x k | y ) = 0 ,则式子 ∏ni=1P(xi|y=1) ∏ i = 1 n P ( x i | y = 1 ) 的结果也为0,显然不合理,因此需要对0概率进行调整。对于此问题,数学家拉普拉斯提出了加1平滑法:
更一般的,加入 xi x i 有 k k 个不同的取值,则拉普拉斯平滑后的概率为:
当样本数量足够大时,这并不会影响到概率的值。
3. 变量符合伯努利分布的贝叶斯分类器
这类样本的每个变量取值不是0就是1,即 xi∈{0,1} x i ∈ { 0 , 1 } ,多用来进行文本的分类,比如判断是否为垃圾邮件。计算过程为:
令自变量为 x x 为:
其中 ai∈{0,1} a i ∈ { 0 , 1 } ,则计算:
根据上面的过程,可以求出 P(y|(x1,x2,⋯,xn)) P ( y | ( x 1 , x 2 , ⋯ , x n ) ) 的值。
4. 变量符合多项式分布的贝叶斯分类器
多项式分布(Multinomial Distribution)是伯努利分布的一种推广。如果说伯努利分布类似于抛硬币的话,那么多项式分布就是掷骰子。比如有的变量是连续型变量,你需要将其按区间换成离散的值。计算过程跟上面一模一样,只不过其中的伯努利分布换成了多项式分布:
即
满足的是二项式分布。
5. 变量符合多元伯努利分布的贝叶斯分类器
在垃圾邮件分类中,前面的模型中,变量 x x 只是描述了某个单词是否出现,却忽略了单词出现的次数,多元伯努利模型就是考虑到了这个问题,因此分类效果往往也更好。假设 M M 为词典中单词的总数, ni n i 为第 i i 封邮件中单词的总数量,因此 (x(i)1,x(i)2,…,x(i)n) ( x 1 ( i ) , x 2 ( i ) , … , x n ( i ) ) 是一个单词构成的向量,每个分量的值表示的是出现的是字典中的第几个词。其中 x(i)j∈{1,2,…,M} x j ( i ) ∈ { 1 , 2 , … , M } 。
因此
n n 是邮件中单词的总数。
而
其中 k k 表示的是某个单词。分母的意思是,在所有的垃圾邮件中,单词 k k 出现的总次数。分母的意思是所有垃圾邮件中单词的总数,然后再进行拉普拉斯平滑。注意由于 xj x j 共有 M M 个不同的取值,因此分母应该加上 M M 。
6. 连续型变量的贝叶斯分类器(变量符合多元高斯分布)
假设自变量为 x1,x2,…,xn x 1 , x 2 , … , x n ,且服从多元高斯分布,此时我们说变量 x x 服从多元搞死分布: x∼N(μ⃗ ,Σ) x ∼ N ( μ → , Σ ) , μ⃗ μ → 是变量 x⃗ x → 的各个分量的均值组成的向量, Σ Σ 是变量 x⃗ x → 的各个分量的协方差,是一个 n×n n × n 的矩阵。对于标签为0和为1的样本分别建模如下:

将其映射到各个变量上看其二位的高斯分布,类似于:

然后拿到新的样本时,计算其分别属于 P(y=1) P ( y = 1 ) 和 P(y=0) P ( y = 0 ) ,哪个概率值越大,则该样本就属于那个标签。
其中 P(x|y=1) P ( x | y = 1 ) 和 P(x|y=0) P ( x | y = 0 ) 需要分别从正负样本建立的两个高斯模型的曲线中求得。
两个高斯判别曲线叠加后的效果类似于 sigmod s i g m o d 函数,但是高斯曲线的假设更强。因此如果数据确实是近似服从高斯分布的,则高斯贝叶斯模型通常比逻辑回归效果更好,否则逻辑回归效果更好。此外,当数据量比较少时,如果大胆假设数据是服从高斯分布的,则高斯效果可能更好。
7. 贝叶斯网络
朴素贝叶斯的假定是:各个自变量之间相互独立。在某些情况下这是成立的,但是很多情况下变量之间存在着相互依赖的关系。因此当独立随机事件不再互相独立时,就需要用到贝叶斯网络了。\
贝叶斯网络(Bayesian Network)又称信念网络(Belief Network)或者有向无环图模型(Directed Acyclic Graphical Model),是一种概率图型模型,借由有向无环图(Directed Acyclic Graphs, or DAGs )中得知一组随机变量{}及其n组条件概率分配(conditional probability distributions, or CPDs)的性质。一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,抑或是隐变量、未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系或是非条件独立的;而节点中变量间若没有箭头相互连接一起的情况就称其随机变量彼此间为条件独立。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(descendants or children)”,两节点就会产生一个条件概率值。
一般情况下,如果不用贝叶斯网络,我们也能解决一个变量间不是互相独立的概率问题。但是当变量数目增多时,我们需要将所有情况下的概率都存储起来,此时空间复杂度为: O(2n) O ( 2 n ) ,显然这是一种非常不可取的方式。主要是其中一些步骤进行了重复计算。因此借鉴动态规划的思想,我们其实只需要存储其中的部分数值即可。
贝叶斯网络由两个成分来定义,有向无环图(DAG)和条件概率表(Conditional Probability Table, CPT)。需要存储的也是这两个成分。一般情况下,假设节点 x x 的”因”为集合 I I , parent(i) p a r e n t ( i ) 表示节点 x x 的第 i i 个父节点,则节点 x x 的条件概率为:
因此:
下面以一个简单的例子来说明:
假设 w w 为草坪是否湿, c c 为是否有云, s s 为是否开洒水器, r r 为天是否下雨,假设原始概率分布为:

概率图模型和相应的条件概率表为:

对于先前的全概率表,我们需要存储15个数值,而对于条件概率表,我们只需要存储9个数值,极大地减少了存储量和计算量。
现假设我们需要求: P(S=1) P ( S = 1 ) 的概率:
常见的贝叶斯网络有:
head-to-head

tail-to-tail
朴素贝叶斯即是这种拓补结构

head-to-tail
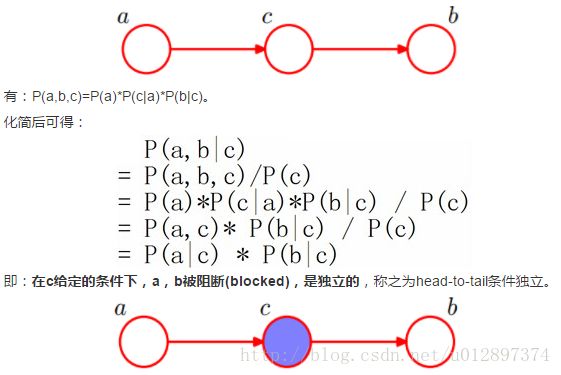
这种结构就是一种链式结构,马尔科夫模型就是采用的这种结构:

贝叶斯网络的拓补结构如何构造:
- 通过专家知识,由专家给出
- 遍历所有的网络拓补结构,哪种效果最好就用哪种。
贝叶斯网络的训练过程,其实就是学习出条件概率表(CPT)的过程。