推荐系统——矩阵分解
一、隐因子模型(Latent Factor Model,LFM)
LFM是推荐系统中的经典模型,它也就是2006年Simon Funk在博客中公开的算法,当时背景是Netflix Prize比赛。LFM的核心算法是Funk-SVD算法,是推荐系统领域比较知名的算法之一。LFM主要应用在两个方面:一个是用户评分预测,一个是物品隐类Top-N热门排行。做法就是将评分矩阵分解成两个低维矩阵相乘。当年提出算法的博客链接:https://sifter.org/~simon/journal/20061211.html
二、矩阵分解(Matrix Factorization,MF)
基于矩阵分解的方法是一类流行的潜在因子模型。通过将用户和项目映射到联合潜在因子空间,矩阵分解可以将用户-项目交互建模为用户和项目潜在因子向量的内积。但是,已知基于矩阵分解的方法存在稀疏性和透明性的问题。
声明:以下内容源于腾讯技术工程 ,作者zhongzhao
主要介绍了显式矩阵分解和隐式矩阵分解的数学原理,包括模型思想、目标函数、优化求解的公式推导等,旨在为需要了解算法细节的同学提供参考。
1、显式数据和隐式数据
MF用到的用户行为数据分为显式数据和隐式数据两种。显式数据是指用户对item的显式打分,比如用户对电影、商品的评分,通常有5分制和10分制。隐式数据是指用户对item的浏览、点击、购买、收藏、点赞、评论、分享等数据,其特点是用户没有显式地给item打分,用户对item的感兴趣程度都体现在他对item的浏览、点击、购买、收藏、点赞、评论、分享等行为的强度上。
显式数据的优点是行为的置信度高,因为是用户明确给出的打分,所以真实反映了用户对item的喜欢程度。缺点是这种数据的量太小,因为绝大部分用户都不会去给item评分,这就导致数据非常稀疏,同时这部分评分也仅代表了小部分用户的兴趣,可能会导致数据有偏。隐式数据的优点是容易获取,数据量很大。因为几乎所有用户都会有浏览、点击等行为,所以数据量大,几乎覆盖所有用户,不会导致数据有偏。其缺点是置信度不如显式数据的高,比如浏览不一定代表感兴趣,还要看强度,经常浏览同一类东西才能以较高置信度认为用户感兴趣。
根据所使用的数据是显式数据还是隐式数据,矩阵分解算法又分为两种。使用显式数据的矩阵分解算法称为显式矩阵分解算法,使用隐式数据的矩阵分解算法称为隐式矩阵分解算法。由于矩阵分解算法有众多的改进版本和各种变体,本文不打算一一列举,因此下文将以实践中用得最多的矩阵分解算法为例,介绍其具体的数据原理,这也是spark机器学习库mllib中实现的矩阵分解算法。从实际应用的效果来看,隐式矩阵分解的效果一般会更好。
2、显式矩阵分解
在本系列第一篇文章中,我们提到,矩阵分解算法的输入是user对item的评分矩阵(图1等号左边的矩阵),输出是User矩阵和Item矩阵(图1等号右边的矩阵),其中User矩阵的每一行代表一个用户向量,Item矩阵的每一列代表一个item的向量。User对item的预测评分用它们的向量内积来表示,通过最小化预测评分和实际评分的差异来学习User矩阵和Item矩阵。

2.1 目标函数
为了用数学的语言定量表示上述思想,我们先引入一些符号。设rui 表示user u 对item i 的显式评分,当rui >0时,表示用户u 对item i 有评分,当rui =0时,表示用户u 对item i 没有评分,xu 表示用户u 的向量,yi 表示item i 的向量,则显式矩阵分解的目标函数为:
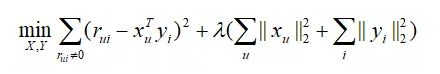
其中xu 和yi 都是k 维的列向量,k 为隐变量的个数。
![]()
是所有xu 构成的矩阵。
![]()
为所有yi 构成的矩阵,N 为用户数,M 为item数,λ为正则化参数。
在上述公式中,![]() 为用户向量与物品向量的内积,表示用户u 对物品i 的预测评分,目标函数通过最小化预测评分和实际评分rui 之间的残差平方和,来学习所有用户向量和物品向量。这里的残差项只包含了有评分的数据,不包括没有评分的数据。目标函数中第二项是L2正则项,用于保证数值计算稳定性和防止过拟合。
为用户向量与物品向量的内积,表示用户u 对物品i 的预测评分,目标函数通过最小化预测评分和实际评分rui 之间的残差平方和,来学习所有用户向量和物品向量。这里的残差项只包含了有评分的数据,不包括没有评分的数据。目标函数中第二项是L2正则项,用于保证数值计算稳定性和防止过拟合。
2.2 求解方法:
求解X 和Y 采用的是交替最小二乘法(alternative least square, ALS),也就是先固定X 优化Y ,然后固定Y 优化X ,这个过程不断重复,直到X 和Y 收敛为止。每次固定其中一个优化另一个都需要解一个最小二乘问题,所以这个算法叫做交替最小二乘方法。
(1)Y 固定为上一步迭代值或初始化值,优化X :
此时,Y 被当做常数处理,目标函数被分解为多个独立的子目标函数,每个子目标函数对应一个用户。对于用户u ,目标函数为:
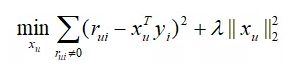
这里面残差项求和的个数等于用于u 评过分的物品的个数,记为m 个。把这个目标函数化为矩阵形式,得:
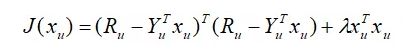
其中,
![]()
表示用户u 对这m 个物品的评分构成的向量。
![]()
表示这m 个物品的向量构成的矩阵,顺序跟Ru 中物品的顺序一致。
对目标函数J关于xu 求梯度,并令梯度为零,得:
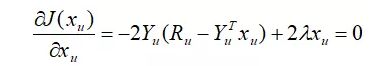
解这个线性方程组,可得到xu 的解析解为:
![]()
(2) X 固定为上一步迭代值或初始化值,优化Y:
此时,X 被当做常数处理,目标函数也被分解为多个独立的子目标函数,每个子目标函数对应一个物品。类似上面的推导,我们可以得到yi 的解析解为:
![]()
其中,
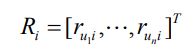
表示n 个用户对物品i 的评分构成的向量,

表示这n 个用户的向量构成的矩阵,顺序跟Ri 中用户的顺序一致。
2.3 工程实现
当固定Y 时,各个xu 的计算是独立的,因此可以对xu 进行分布式并行计算。同理,当固定X 时,各个yi 的计算也是独立的,因此也可以对yi 做分布式并行计算。因为Xi 和Yu 中只包含了有评分的用户或物品,而非全部用户或物品,因此xu 和yi 的计算时间复杂度为O(k2nu+k3)其中nu 是有评分的用户数或物品数,k 为隐变量个数。
3、隐式矩阵分解
隐式矩阵分解与显式矩阵分解的一个比较大的区别,就是它会去拟合评分矩阵中的零,即没有评分的地方也要拟合。
3.1 目标函数
我们仍然用rui 表示用户u 对物品i 的评分,但这里的评分表示的是行为的强度,比如浏览次数、阅读时长、播放完整度等。当rui >0时,表示用户u 对物品i有过行为,当rui =0时,表示用户u 对物品i没有过行为。首先,我们定义一个二值变量pui 如下:
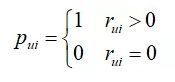
这个pui 是一个依赖于rui 的量,用于表示用户u 对物品i 是否感兴趣,也称为用户偏好。当用户u 对物品i 有过行为时,我们认为用户u 对物品i感兴趣,此时pui =1;当用户u 对物品i 没有过行为时,我们认为用户u 对物品i 不感兴趣,此时pui =0。
模型除了要刻画用户对物品是否感兴趣外,而且还要刻画感兴趣或不感兴趣的程度,所以这里的隐式矩阵分解还引入了置信度的概念。从直观上来说,当rui >0时,rui 越大,我们越确信用户u 喜欢物品i ,而当rui =0时,我们不能确定用户u 是否喜欢物品i ,没有行为可能只是因为用户u 并不知道物品i 的存在。
因此,置信度是rui 的函数,并且当rui >0时,置信度是rui 的增函数;当rui =0时,置信度取值要小。论文中给出的置信度cui 的表达式为:
![]()
当rui >0时,cui 关于rui 线性递增,表示对于有评分的物品,行为强度越大,我们越相信用户u 对物品i 感兴趣;当rui =0时,置信度恒等于1,表示对所有没有评分的物品,用户不感兴趣的置信度都一样,并且比有评分物品的置信度低。用xu 表示用户u 的向量,yi 表示item i 的向量,引入置信度以后,隐式矩阵分解[6]的目标函数为:

其中xu 和yi 都是k 维的列向量,k 为隐变量的个数,
![]()
是所有xu 构成的矩阵,
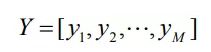
为所有yi 构成的矩阵,N 为用户数,M 为item数,λ为正则化参数。目标函数里的内积用于表示用户对物品的预测偏好,拟合实际偏好pui,拟合强度由cui 控制。并且对于pui =0的项也要拟合。目标函数中的第二项是正则项,用于保证数值计算稳定性以及防止过拟合。
3.2 求解方法
目标函数的求解仍然可以采用交替最小二乘法。具体如下:
(1)Y 固定为上一步迭代值或初始化值,优化X :
此时,Y 被当做常数处理,目标函数被分解为多个独立的子目标函数,每个子目标函数都是某个xu 的函数。对于用户u ,目标函数为:

把这个目标函数化为矩阵形式,得
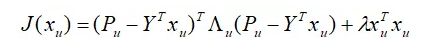
其中,

为用户u 对每个物品的偏好构成的列向量,
![]()
表示所有物品向量构成的矩阵,Λu 为用户u 对所有物品的置信度cui 构成的对角阵,即:
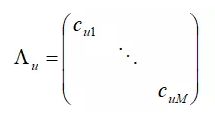
对目标函数J 关于xu 求梯度,并令梯度为零,得:
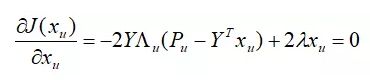
解这个线性方程组,可得到xu 的解析解为:
![]()
(2) X 固定为上一步迭代值或初始化值,优化Y:
此时,X 被当做常数处理,目标函数也被分解为多个独立的子目标函数,每个子目标函数都是关于某个yi 的函数。通过同样的推导方法,可以得到yi 的解析解为:
![]()
其中,
![]()
为所有用户对物品i 的偏好构成的向量,
![]()
表示所有用户的向量构成的矩阵,Λi 为所有用户对物品i 的偏好的置信度构成的对角矩阵,即
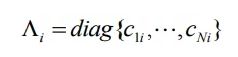
3.3 工程实现
由于固定Y 时,各个xu 的求解都是独立的,所以在固定Y 时可以并行计算各个xu,同理,在固定X时可以并行计算各个yi 。
在计算xu 和yi 时,如果直接用上述解析解的表达式来计算,复杂度将会很高。以xu 的表达式来说,Y Λu YT 这一项就涉及到所有物品的向量,少则几十万,大则上千万,而且每个用户的都不一样,每个用户都算一遍时间上不可行。所以,这里要先对xu 的表达式化简,降低复杂度。
注意到Λi 的特殊性,它是由置信度构成的对角阵,对于一个用户来说,由于大部分物品都没有评分,以此Λi 对角线中大部分元素都是1,利用这个特点,我们可以把Λi 拆成两部分的和,即
![]()
其中I为单位阵,Λu - I 为对角阵,并且对角线上大部分元素为0,于是,可以重写为如下形式:
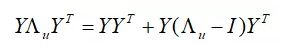
分解成这两项之后,第一项Y YT 对每个用户都是一样的,只需要计算一次,存起来,后面可以重复利用,对于第二项,由于Λu - I 为对角线大部分是0的对角阵,所以计算Y (Λu - I )YT 的复杂度是O(k2nu)。其中nu 是Λu - I 中非零元的个数,也就是用户u 评过分的物品数,通常不会很多,所以整个Y ΛuYT的计算复杂度由O(k2M) 降为O(k2nu)。由于M>>nu,所以计算速度大大加快。对于xu 表达式的Y Λu Pu这一项,则应Y ( Λu Pu) 这样计算,利用Pu 中大部分元素是0的特点,将计算复杂度由O(kM ) 降低到O(knu)。通过使用上述数学技巧,整个xu的计算复杂度可以降低到O(k2nu+k3),其中nu是有评分的用户数或物品数,k 为隐变量个数,完全满足在线计算的需求。
4、增量矩阵分解算法
无论是显式矩阵分解,还是隐式矩阵分解,我们在模型训练完以后,就会得到训练集里每个用户的向量和每个物品的向量。假设现在有一个用户,在训练集里没出现过,但是我们有他的历史行为数据,那这个用户的向量该怎么计算呢?当然,最简单的方法就是把这个用户的行为数据合并到旧的训练集里,重新做一次矩阵分解,进而得到这个用户的向量,但是这样做计算代价太大了,在时间上不可行。
为了解决训练数据集以外的用户(我们称之为新用户)的推荐问题,我们就需要用到增量矩阵分解算法。增量矩阵分解算法能根据用户历史行为数据,在不重算所有用户向量的前提下,快速计算出新用户向量。
在交替最小二乘法里,当固定Y 计算xu 时,我们只需要用到用户u 的历史行为数据rui 以及Y 的当前值,不同用户之间xu的计算是相互独立的。这就启发我们,对于训练集以外的用户,我们同样可以用他的历史行为数据以及训练集上收敛时学到的Y,来计算新用户的用户向量。下面的图2表示了这一过程。

设用户历史行为数据为Pu={Pui },训练集上学到的物品矩阵为Y,要求解的用户向量为xu,则增量矩阵分解算法求解的目标为:
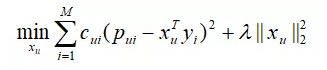
这个目标函数跟第3节中固定Y 时求解xu 的目标函数是一样的,但有两个不同点:
(1)这里的Y 是不需要迭代的,它是MF在训练集上收敛时得到的Y;
(2)用户的历史行为数据Pu 要过滤掉在Y中没出现过的物品。由于Y 是固定的,我们不需要迭代,直接通过xu 的解析表达式求解xu,即:
![]()
式中的所有符号和上一节相同。
事实上,增量矩阵分解的目标函数中的Y 也不一定要是MF在训练集上学出来的,只要Y 中的每个向量都能表示对应物品的特征就行,也就是说,Y 可以是由其他数据和其他算法事先学出来的。矩阵分解的增量算法在图文推荐系统中有着广泛应用,具体的应用将在下一篇文章中介绍。
5、推荐结果的可解释性
好的推荐算法不仅要推得准确,而且还要有良好的可解释性,也就是根据什么给用户推荐了这个物品。传统的ItemCF算法就有很好的可解释性,因为在ItemCF中,用户u 对物品i 的预测评分R (u, i ) 的计算公式为

其中N(u ) 表示用户u 有过行为的物品集合,ruj 表示用户u 对物品j 的历史评分,sji 表示物品j 和物品i 的相似度。在这个公式中,N(u ) 中的物品j 对R(u, i ) 的贡献为ruj sji,因此可以很好地解释物品i 具体是由N(u) 中哪个物品推荐而来。那对于矩阵分解算法来说,是否也能给出类似的可解释性呢?答案是肯定的。
以隐式矩阵分解为例,我们已经推导出,已知物品的矩阵Y 时,用户u 的向量的计算表达式为:
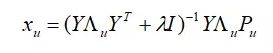
令
![]()
并把Y Λu Pu 展开来写,则的表达式可以写成

其中,
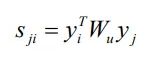
可以看成是物品j 和物品i 之间的相似度,
![]()
可以看成是用户u 对用户j的评分,这样就能像ItemCF那样去解释N(u )中每一项对推荐物品i 的贡献了。从sji 的计算表达式中,我们还可以看到,物品j 和物品i 之间的相似度sji 是跟用户u 有关系的,也就是说,即使是相同的两个物品,在不同用户看来,它们的相似度是不一样的,这跟ItemCF的固定相似度有着本质上的区别,MF的相似度看起来更合理一些。
6、小结
(1)根据用户行为数据的特点,矩阵分解又分为显式矩阵分解和隐式矩阵分解两种;
(2)在显式MF算法中,用户向量和物品向量的内积拟合的是用户对物品的实际评分,并且只拟合有评分的项;
(3)在隐式MF算法中,用户向量和物品向量的内积拟合的是用户对物品的偏好(0或1),拟合的强度由置信度控制,置信度又由行为的强度决定;
(4)在隐式MF中,需要使用一些数学技巧降低计算复杂度,才能满足线上实时计算的性能要求;
(5)对于有行为数据,但不在训练集里的用户,可以使用增量MF算法计算出他的用户向量,进而为他做推荐;
(6)MF算法也能像ItemCF一样,能给出推荐的理由,具有良好的可解释性。
三、参考链接
1、隐因子模型:https://blog.csdn.net/sinat_22594309/article/details/86576757
2、矩阵分解:http://blog.sina.com.cn/s/blog_745323d30101hav2.html
3、SVD 和 Netflix Prize 的 Funk-SVD:https://zhuanlan.zhihu.com/p/33262521
4、从主题模型(Topic Model)到隐语义模型(Latent Factor Model):https://blog.csdn.net/m0_37788308/article/details/78316282
5、论文:Collaborative Filtering for Implicit Feedback Datasets(2008) ,考虑隐式反馈。
6、微信博文:
【科普篇】推荐系统之矩阵分解模型:https://mp.weixin.qq.com/s/u67Xx38I9dnF4ddfb5lfNw
【原理篇】推荐系统之矩阵分解模型:https://mp.weixin.qq.com/s/j_FRp9KFIpgbtnhJlLeECA