深度学习 --- 基于RBM的深度置信网络DBN-DNN详解
上一节我们详细的讲解了受限玻尔兹曼机RBM的原理,详细阐述了该网络的快速学习原理以及算法过程,不懂受限玻尔兹曼机的建议先好好理解上一节的内容,本节主要讲解的是使用RBM组成深层神经网络的深度置信网络DBN(Deep Belief Network),但是该网络效果并没有那么理想,hinton在此基础上加入反向传播算法即DNN,使的效果要比DBN好太多了。为什么会有这么好的效果呢?通过前面几节受限玻尔兹曼机的原理我们可以知道受限玻尔兹曼机理论上可以达到全局最优解,即通过他训练的数据基本上会处于全局最优解的范围以内,但为什么深度RBM的表现并不是很好呢?因为特征压缩的很厉害,丢失了很多特征信息,下面会详解,此时在结合BP。我们都知道BP的优缺点(不懂的看我的这篇文章),其中一个缺点就是梯度消失问题,原因是当层数多时,如果梯度小于1,则层数越多就越容易形成梯度消失的问题(这里大家需要深入理解梯度,没深入理解的建议看这篇文章,你会深入理解的),但是DNN的效果好的原因是,DBN训练的权值作为BP的初始化权值,此时BP就在全局最优解附近进行微调即寻找最优解,即使梯度消失也没关系,我们只需微调就好,因此RBM和BP的结合会有很好的效果,下面就开始讲解DBN和DNN,但是讲解前大家需要知道什么是自编码器,什么是稀疏自编码器?
自编码器
大家应该都知道什么是压缩吧,例如一张原始图片有几兆大小,我们通过压缩技术,压缩到几百k,这个压缩率很高了,但是带来的影响就是图像会有明显的马赛克,不清晰,如下图,左图是原图,右图就是压缩的,同时这里的压缩也叫编码,同样的神经网络也可以做压缩编码的工作,或者说神经网络可以做特征提取,下面我们详细看看神经网络是如何做编码的。

图像划分
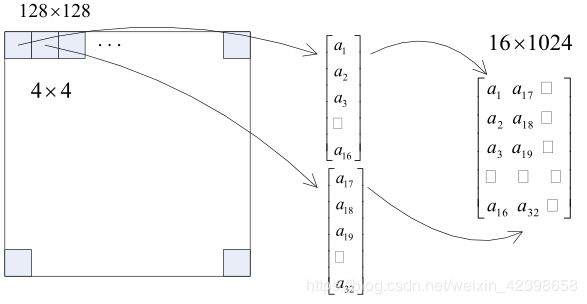
一般图片处理都是通过图片划分技术进行划分,然后写成矩阵的形式,如下图加入一张图片的像素是128x128的,这里使用4x4方格进行划分,每个方格对应一个亮度值(这里以灰度图像为例)即0~255的一个值,因此整个图像可以划分为1024个方格,而每个方格的数据按列排列,最后一张图片就可以存储到一个16x1024的矩阵中,此时每一列就是我们的一个样本,而每个样本应该表示一个亮度值,总有1024个样本,(这里大家需要理解好,因为从这里我就开始引入这些概念了,为后面的CNN做铺垫),这样我们使用这样的样本通过神经网络压缩。如下图所示:
编码神经网络
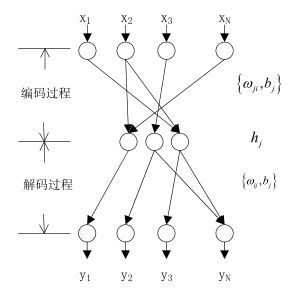
如上图,上图是一个经典的神经网络模型,只是这里不同的是隐层的神经元要比输入输出少的,其实这就是压缩的了即编码,我们上面把图片信息写成矩阵了,假如这里把上图的输入神经元N=16,隐层的神经元为3个,输出仍然为16个神经元,把图片矩阵数据输入这个神经网络进行训练,学习算法使用BP,最后使的误差最小,此时的隐层就可以得到了一个3x1024的矩阵,因此图片就压缩了也叫编码了,此时的训练权值就是压缩权值或者说是编码权值即对应着上图的编码过程,如果解压呢直接输出y即可,对应上图的解压过程,这里应该不难理解。因此是通过训练的,一旦训练好就可以对其他类的图片进行压缩了,因此称为自编码器。但是呢这个编码器有个缺点就是 我不知道隐层我应该设计几个神经元好,如果只最求压缩率,设置一个神经元,但是解压后的图形将严重失真,如果最求失真度,那么中间层我使用15个神经元,虽然 不失真,但是起不到压缩效果,怎样确定合适的神经元呢?这里吴恩达的给出了解决方法即稀疏自编码器。
稀疏自编码器
大家有时间可以好好读读该论文《Sparse autoencoder》,这里我简要的介绍,公式不细推,当然能保证大家能看懂的。所谓稀疏自编码器就是说中间的隐层的神经元数让系统根据不同情况自动做出决定,使其达到压缩率和失真度有个平衡。那么我如何实现使他自动确定神经元的个数呢?又怎么表达呢?这里先按照上面的例子解释一下,假如上面的例子隐层的神经元也为16个,通过自动决定机制让其部分隐层神经元输出逼近0,这时候这神经元就可以舍弃了,是通过这样的机制实现的,但是又是通过什么实现自动决定隐层神经元哪个输出为0哪个不为0呢?这里我先使用语言解释,然后再通过图片和数学来证明它,怎么实现呢,其实很简单,上面的例子自动编码的学习函数其实是BP,他的误差函数就是输出和样本的差,那么我们在这个误差函数的基础上加一个惩罚项,这个惩罚项是隐层所有神经元的输出和,那么我们在求误差函数的极小值时就把隐层的输出考虑到了,因此他会限制隐层的输出,至于怎么限制的我们下面会说明。(这里的惩罚项在机器学习里经常使用,大家应该深入理解加入惩罚项的原因和好处,尤其要知道如何构造惩罚项,以后遇到类似问题,我们能否也类似构造惩罚项呢?),下面我们就详细解释一下稀疏自编码器的工作原理。
这是自编码器的流程图:
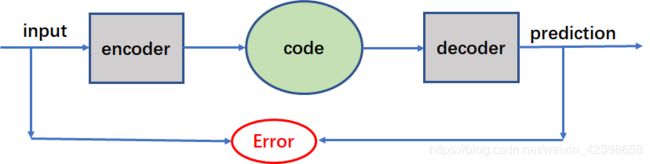
这和我们举得例子是一样的,也就是BP神经网络了,code就是隐层输出了,就是压缩编码了。假如input是比code更高维度的数据,其中误差为下面计算,学习是通过BP学习。
![]()
稀疏自编码器的流程图
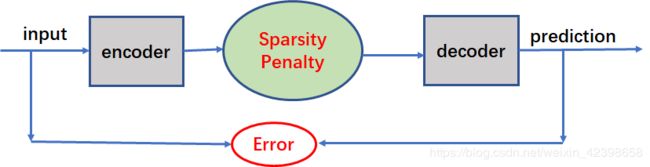
稀疏惩罚项(Sparsity Penalty) :
![]()
误差项:
![]()
loss :
![]()
训练算法使用BP
我们发现了自编码器和稀疏编码的不同就是多了一个惩罚项,其他的都一样,都是使用BP,那么我们下边就详细解释惩罚项的构造,但是BP我不会细讲,前面都讲过了。好,下面开始:
我们知道,常规的自编码器是基于bp 的神经网络,这里直接把损失函数写出来不解释。
![]()
下面细说惩罚项:
这里激活神经元代表输出接近1,未激活代表神经元接近0,我们希望隐层大多数的神经元都是未激活状态,因此如何设计惩罚项就很重要了。
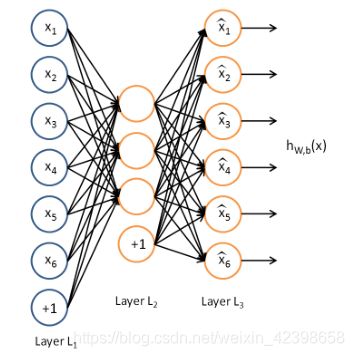
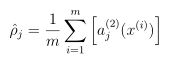
上式![]() 表示隐藏层第j个的神经元输出,上式是对隐藏层的神经元求和在取均值 ,如果想要达到未激活的神经元尽量多的,则上式的均值应该尽量的小,这里我们设置一个阈值
表示隐藏层第j个的神经元输出,上式是对隐藏层的神经元求和在取均值 ,如果想要达到未激活的神经元尽量多的,则上式的均值应该尽量的小,这里我们设置一个阈值 ,使他们尽量相等,即:
,使他们尽量相等,即:
![]()
例如如果我们假如=0.05,他们尽量的相等,且均值很小,在所有的隐层激活函数中激活的神经元并不多才能达到均值很小的目的,因此这样才可以达到目的,关键是如何衡量他俩很接近呢?即如何建立关系式或者说建立优化目标?
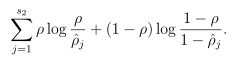
我们看到上式很复杂,其中s2代表隐层神经元的个数, 上式就是我们的惩罚项了,我们看看能否达到要求,如果![]() ,则此时二者的比值为1,取对数后为0,反之不为0,前后都这样的,因此总体为0,因此可以达到我们的效果。
,则此时二者的比值为1,取对数后为0,反之不为0,前后都这样的,因此总体为0,因此可以达到我们的效果。
其实上式的来源是KL距离,这个我们在上一节说过,有兴趣的同学可以查一下相关资料,KL的目的就是衡量两个分布的相似性,如果很相似则为0,反之不为零。
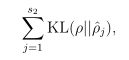
这两个![]() 其实是伯努利分布的接近程度,因此可以使用,我们看看图:
其实是伯努利分布的接近程度,因此可以使用,我们看看图:
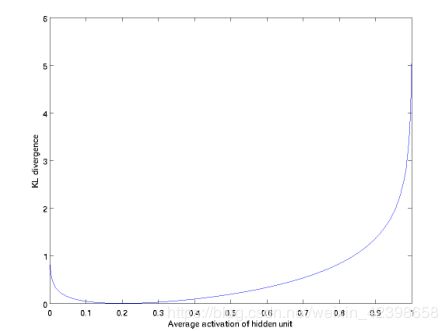
如图,这里设置 =0.2,我们从图中可以看到,在0.2是KL距离为0,在接近于1和0时,KL距离都急剧增大,也就是如果激活的神经元多则均值就会变大,KL距离也会变大,我们的损失函数就会考虑这个情况,因此总的损失函数如下:
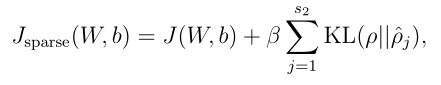
其中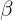 是说明惩罚项的重要程度的意思,后面就是计算了,不细讲了,这就是稀疏自编码器的原理,大家应该能看懂的。下面我们就介绍深度置信网络,因为有前面和上面的基础,DBN会很简单,另外就是稀疏自编码器详细的过程推倒请参考吴恩达的《Sparse autoencoder》这篇论文。
是说明惩罚项的重要程度的意思,后面就是计算了,不细讲了,这就是稀疏自编码器的原理,大家应该能看懂的。下面我们就介绍深度置信网络,因为有前面和上面的基础,DBN会很简单,另外就是稀疏自编码器详细的过程推倒请参考吴恩达的《Sparse autoencoder》这篇论文。
DBN-DNN
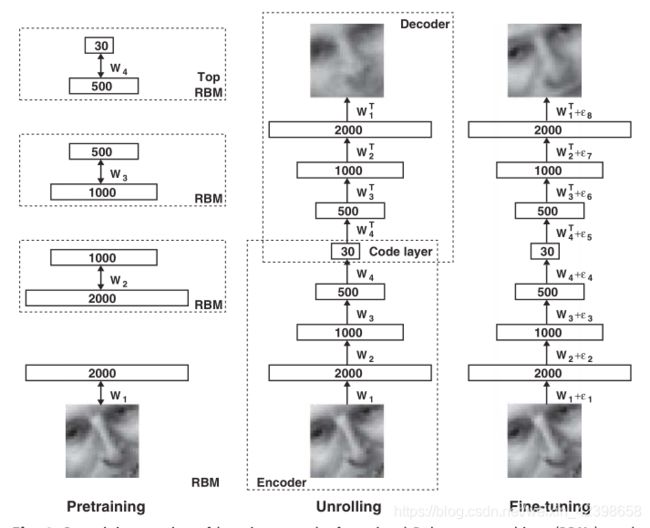
上面的就是hinton发表在nature的一篇经典之作,也因为这篇文章,深度学习开始发展起来,从上图我们可以看到最左边的图是多个受限玻尔兹曼机,按照上面的理解,加入此时的黑白图片的像素点为2000,因此使用2000个神经元读取,然后通过第一个受限玻尔兹曼机的编码或者压缩为1000个神经元,压缩率为1\2,然后通过第二个RBM进行编码为500个神经元,总压缩率为1\4,然后使用第三个RBM继续进行压缩为30个神经元,此时总压缩率接近1\60,可以说压缩率很高了,把他们组合在一起就是编码阶段如上图的中间部分,按照上面进行Decoder即解压在观察图片,发现失真很严重了,但是总体轮廓还是有的,从图中还是可以看出是一个人,好,到这里大家有没有一个疑问,就是上面的自编码器和稀疏自编码器一层效果那么好为什么还要建立深层的压缩机制,直接使用一层不也可以压缩编码吗?这里大家先自己思考一下,下面我给解释,虽然可以通过一步编码也可以达到这个类似效果,但是一步压缩其实是在原图的基础上直接进行特征提取的,那么什么是特征呢?根据上图个人理解就是特征就是图片的轮廓即变化很激烈的地方(这个用信号处理知识来解释会更好,变化很激烈的一般高频分量很丰富),这些地方有明显的突出的地方,例如方桌他的四个角特征很明显,因为都直角变化了,但是桌面变化就不明显了,即使变化也只是颜色的变化,这些不是重要的信息,即我们无法通过颜色特征识别这是个桌子,但是如果我们有桌子的四个拐角的特征,那么我们就可以判断他是一个桌子,因此这里我们可以把桌子的四个拐角看做深层特征,而颜色看做浅层特征了,总结一下,特征就是一个物体的故有表征,是区别其他物体的根本不同所在,例如区别自行车和三轮车,轮子个数就是很明显的特征,男生和女生的区别,头发,衣服,行为等可以区别开,也就是说当我们需要区分很接近的物品时,我们不能只依靠一个特征,我们需要更多的特征取区分,这就是图像识别里的知识。好,我们继续接着讨论为什么需要深层的自编码器而不是一层,因为我们通过多层可以提取深层次的特征即主要特征,即第一层在总体上进行提取,提取到全局的特征,包括颜色、变化不明显的地方都捕捉到了,在第二层我们继续提取,此时在第一层的基础上继续提取特征此时颜色就会被弱化,而变化很剧烈的特征就会保留,后面多层就是把主要的轮廓保留下来了,其他的都舍弃了,如果只使用一层,那么物体的主要轮廓无法凸显,浅层特征还保留着,直接结果可能我们无法从轮廓中识别他是什么,因此需要深层的提取,这就是原因,以上解释是 根据个人的理解(有什么不对的请留言)。好,我们看到上图的中间图像即Unrolling的编码和解码过程就是多个自编码器的堆叠,从结果来看,DBN很好的提取到了深层特征即总体轮廓保留下来了,但是细节损失严重,为了尽可能的保留细节方面,hinton把此训练稳定的权值用作BP网络的初始权值,从前面几节我们知道,RBM一旦收敛一般会收敛到全局最优解附近,那么BP网络在此基础上进行微调,使其到全局最优值,微调的另外一个目的就是尽可能的保留细节,因此得到的效果细节会更丰富,如上右图所示,要比DBN的效果好很多,图片的细节保留的很多,效果很好,因此最右边的图称为DNN,整个图片称为DBN-DNN。
深度信念网络目前已经在语音识别、图像识别、以及自然语言处理等领域取得较好的效果,并得到了广泛的使用。
到这里就基本上结束了,大家有时间看看hinton的《Reducing the Dimensionality of Data with Neural Networks》这篇论文,主要内容就是上面的讲的,讲了RBM的训练算法,我们前几节都讲了,因此看起来会很容易的,好,本节到此结束,下一节我们讲径向基神经网络,这个网络在卷积神经网络会使用到。