详细记录了python爬取小说《元尊》的整个过程,看了你必会~
学了好几天的渗透测试基础理论,周末了让自己放松一下,最近听说天蚕土豆有一本新小说,叫做《元尊》,学生时代的我可是十分喜欢读天蚕土豆的小说,《斗破苍穹》相信很多小伙伴都看过吧。今天我们就来看看如果一步一步爬下来《元尊》的所有内容。
首先我们需要选择一个网站进行爬取,我这边使用的是书家园网站,其它网站的操作也是类似原理。
相关库文件
我们使用的库有requests、re和time,其中re和time都是python自带库,我们只需要安装一个requests库。
pip install requests
编码过程
我们可以先访问书家园网站找到《元尊》书籍首页的url——https://www.shujy.com/5200/9683/。
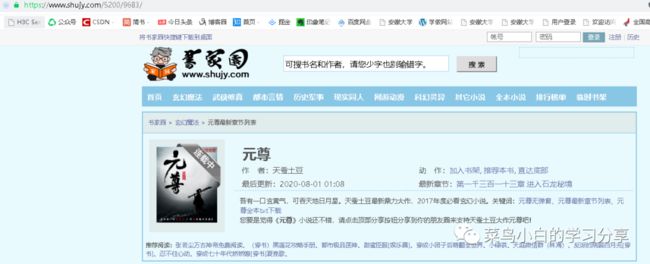
通过requests进行请求,然后将html打印出来。
import requests
url ='https://www.shujy.com/5200/9683/'
response = requests.get(url)
html = response.text
print(html)
打印出来如下图:
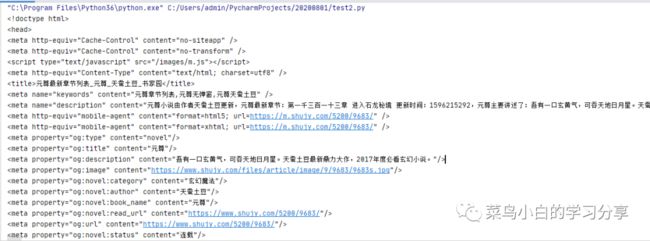
我们找到html中关于文章标题和作者的部分
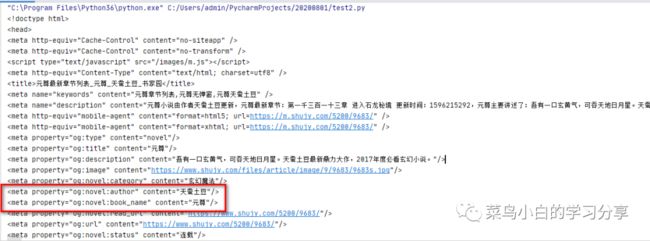
我们通过正则表达式将标题和作者提取出来
title = re.findall(r'',html)[0]
author = re.findall(r'',html)[0]
接下来我们就需要将每一章小说的链接拿出来了,我们通过浏览器中F12工具
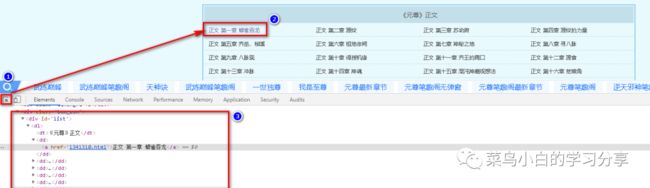
- 点击左上角的箭头
- 点击我们需要定位的元素,我们需要找到每一章的链接,所以我们点击“正文 第一章”
- 我们就可以看到开发者工具中出现了对象在html中的位置
分析链接的位置我们发现都是在“
dl =re.findall(r'.*?',html,re.S)[0]
chapter_info_list=re.findall(r'(.*?)',dl)
这样我们就拿到了所有的章节列表,现在我们需要考虑如何去获取每一章节的内容。我们将首页的URL和每一个章节的链接进行拼接。
chapter_url = url+'/'+chapter_url
chapter_url = chapter_url.replace(' ','')
然后我们同样通过requests库获取到章节内容的HTML文件
chapter_response = requests.get(chapter_url)
chapter_html = chapter_response.text
通过同样的方式,我们发现正文的内容都是在“

我们将这个div标签中的正文内容全部拿出来
#获取第一页正文内容
chapter_content = re.findall(r'(.*?)',chapter_html,re.S)[0]
我们将取出来的内容打印一下看看

我们发现还存在一些“
”和“ ”这样的元素,这些都是我们不希望看到的,那我们就通过replace函数给过滤掉。
chapter_content = chapter_content.replace(' ','')
chapter_content = chapter_content.replace('
','')
我们看看过滤后的内容

发现还是有些不对,为什么每一行文字都空了一行呢?我们通过debug看一下过程中的chapter_content内容

果然还存在一些制表符,那我们就只保留一个换行符“\n”
chapter_content = chapter_content.replace('\r\n\r', '')

这样我们就将这个页面的正文全部扒下来了,但我们翻到页面的末尾我们发现每章可能不仅仅一页,可能存在两页、三页甚至更多内容,怎么才能完整的将这不确定的内容拿下来呢?
我们看到在每一页的正文中都写明了这一章一共需要多少页,并且提供了下一页的链接,我们就通过这个线索来完成。
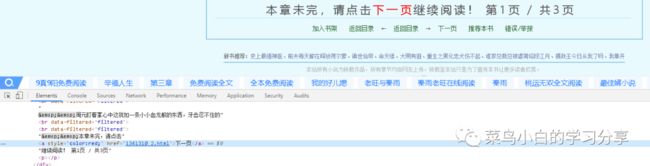
首先我们需要将总共的页数和下一页的链接取出来。
chapter_url,current_page,total_pages = re.findall(r'本章未完,请点击下一页继续阅读!第(.*?)页 / 共(.*?)页', chapter_content,re.S)[0]
然后我们利用一个for循环去取内容,取的方式和前面类似,就不再详细描述了,直接上代码。
for i in range(1,int(total_pages)):
chapter_url,current_page,total_pages = re.findall(r'本章未完,请点击下一页继续阅读!第(.*?)页 / 共(.*?)页',chapter_content)[0]
chapter_url = url+'/'+chapter_url
chapter_url = chapter_url.replace(' ','')
chapter_response = requests.get(chapter_url)
chapter_html =chapter_response.text
chapter_content = re.findall(r'(.*?)', chapter_html, re.S)[0]
chapter_content = chapter_content.replace(' ', '')
chapter_content = chapter_content.replace('
', '')
chapter_content = chapter_content.replace('\r\n\r', '')
f.write('\n')
f.write(chapter_content)
最后我们只需要在外面加一个文件写入操作,将每一次读出的正文内容写入进去就好了。
with open('%s.txt'%title,'w') as f:
f.write(title)
f.write('\n')
f.write(author)
f.write('\n')
list index out of range报错的处理
看着是一切都完成了,可是在我最后来下载的时候,经常在不同的章节出现这样的错误。

这一次可能是在第四章出现问题,下一个可能是在第十章出现问题,总之不固定。我查询了一下这种错误一般会有两种情况
- list[index]index超出范围
- list是一个空的,没有一个元素,进行list[0]就会出现错误!
虽说查询到了原因,这两种情况都不能应该出现随机章节出现报错呀,我还是没有找到原因,如果有大神看到了可以指定一二。
但是我找到一个规避的措施,就是既然它是随机章节报错,那就是我一旦检测到报错之后就再重新请求一次url,重新通过正则校验一次。为此我拎出来一个这样的函数。
def find(pattern,string,url):
try:
chapter_content = re.findall(pattern, string, re.S)[0]
return chapter_content
except Exception as e:
print(e)
time.sleep(1)
chapter_response = requests.get(url)
chapter_html = chapter_response.text
print(chapter_html)
print(url)
i = find(pattern,chapter_html,url)
return i
执行之后果然可行,我一直执行着,现在已经下载了一百多章了
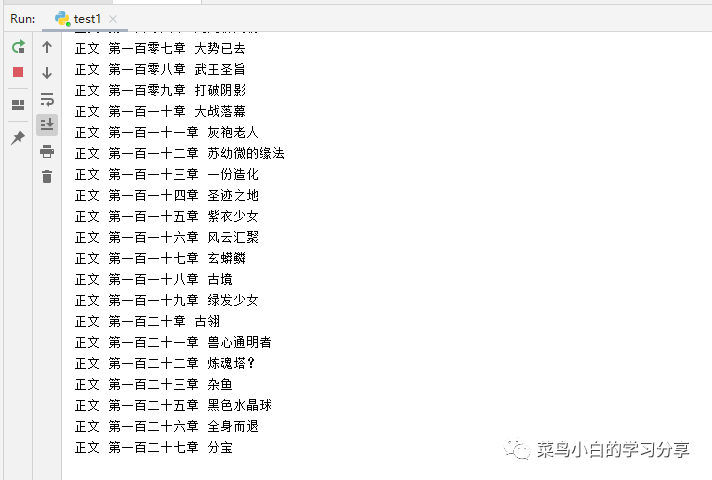
现在看来唯一的缺点就是有点慢,原谅菜鸟小白还没有怎么弄过多线程和多进程,下次我们再来改进吧。
源码获取
源码获取还是老规矩,关注公众号“菜鸟小白的学习分享”,私信回复“小说爬虫源码”即可获取。

好了,今天的内容就到了,如果你觉得菜鸟小白的分享对你有帮助的,就帮忙点一个点赞、在看和关注呗,我们下次再会~