red hat 7 64位 安装jdk和hadoop记录
redhat 7 64位
1.停掉防火墙命令
systemctl stop firewalld.service
停止防火墙命令(重启也无法开启)
systemctl disable firewalld.service
2.更改主机域名
vi /ctx/hosts
打开后输入自己主机名比如新增一行
192.168.23.110 dapeng110
3.解压文件
tar -zxvf 要解压得文件名 -C 解压到哪一个路径
tar -zxvf hadoop-2.7.3.tar.gz -C /root/training
4.设置环境变量(编辑文件 vi + 路径)
vi ~/.bash_profile
----打开文件后相关得操作-----------------
i或者a 开始编辑 esc退出
shift+: 到指令行 wq是保存并退出
q!是不保存退出
===如何设置行号!!!
一般模式下(摁下esc键,即返回到一般模式下)
输入:set nu
取消行号:set nonu
可以做一个设置 永久打开文件自带行号
打开 vim ~/.vimrc
在里面加入 set nu
保存退出即可!!
===如果文件冲突出现 Found a swap file by the name
是因为上次编辑文件非法退出 出现异常 会在操作的文件所在的目录下生成一个swp文件
此文件为隐藏文件 使用命令 ls -a 查看
找到这个文件 执行 rm .文件名.swp
删除即可
----打开文件后相关得操作-----------------
设置完环境变量后要执行一下 ,执行命令如下:
source ~/.bash_profile 这样重启之后环境变量依旧存在
----jdk环境变量得设置
JAVA_HOME=/root/training/jdk1.8.0_144
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
----hadoop得环境变量
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
这里插一句 如果你不晓得一个命令 可以输入后 按两次tab会给出提示
比如输入start 按两次tab可以出来提示第一次是按回车
第二次是按两次Tab
好了 以上就安装成功了
接下来 我们配置hadoop
三种模式
1.本地模式(只需要一台电脑)
没有HDFS,只能测试MapReduce程序
配置简单只要配置一个hadoop安装目录/etc/hadoop/hadoop-env.sh 文件中得 JAVA_HOME属性指位环境变量中得java_home
 修改为
修改为

配置完成
2.伪分布模式(只需要一台电脑)
是在一个电脑上模拟一个分布式的环境,说白了就是假的,但是具有Hadoop的所有功能
其中 HDFS的NameNode SecondaryNameNode DataNade
yarn 的 ResourceManager NodeManager都是在一个节点中
配置如下
---1.配置一个hadoop安装目录/etc/hadoop/hadoop-env.sh 文件中得 JAVA_HOME属性指位环境变量中得java_home 实现方式参照上面
---2.修改
hdfs-site.xml 设置
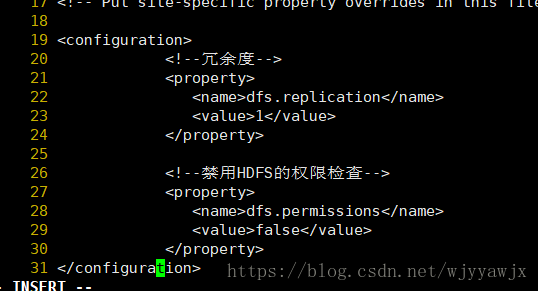
---3.修改
core-site.xml 配置
---4.使用cp mapred-site.xml.template mapred-site.xml命令复制出
mapred-site.xml文件并配置
---5。修改
yarn-site.xml
---6.在使用前先格式话NameNode
![]()
当出现如下图所示信息表示配置完成
![]()
3.全分布模式(最少需要三台电脑)
首先创建三个虚拟机安装好Linux JDK 免密码登陆,配置主机名称,环境变量
1.修改主机 /etc/hosts文件,增加ip和别名
2.依次修改配置文件
hdfs-site.xml
core-site.xml
mapred-site.xml
yarn-site.xml
slaves 从节点地址
使用vi slaves 命令更改 /root/training/hadoop-2.7.3/etc/hadoop目录下的slaves文件
将localhost修改为从属机器 dapeng112和dapeng113