Java并发编程:延时任务队列的实现原理
优先级队列DelayedWorkQueue
DelayedWorkQueue用来存放将要执行的任务,其数据结构为有序二叉堆。
有序二叉堆的特点:
- 所有根结点必定不大于其两个叶子节点
- 任意结点的子节点的索引位置是其本身索引位置乘2后+1
- 任意结点的父节点的索引位置是该结点的索引位置-1后除2并向下取整
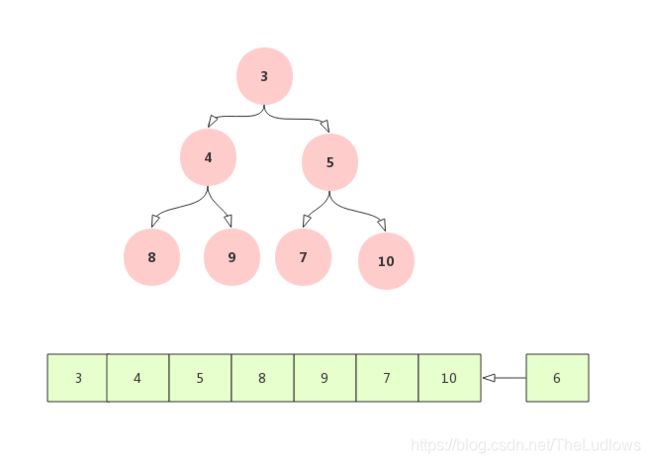
当新添加元素时,加入到数组的尾部,后面我们结合代码分析添加过程DelayedWorkQueue按照任务超时时间升序排序,原因是为了将即将要执行的任务放在尽量靠前的位置。下面分析添加操作:
public boolean offer(Runnable x) {
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
if (i >= queue.length)// 扩容
grow();
size = i + 1;
if (i == 0) {// 第一次添加
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(i, e);
}
if (queue[0] == e) {
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
在调用此方法之前已经把任务封装为RunnableScheduledFuture类型,说白了其内部就是多了一个执行时间,并且重写了compareTo方法。继续看siftUp()的实现,参数i为数组的下标。
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
找到新元素的父节点,然后和父元素进行比较,如果新元素大于大于父节点(compareTo)直接返回,否则和父元素进行交换。获取元素有三种方式,poll()、take()、poll(long timeout, TimeUnit unit),分别为立即获取、等待获取、超时等待获取。这里主要分析等待获取take方法。
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
available.await(); // 如果没有任务,就让线程在available条件下等待
else {
// 任务执行的剩余等待时间
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)// 如果剩余等待时间<=0,返回任务
return finishPoll(first);
first = null;
if (leader != null)// [1]
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);// [2]
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
注意一点leader变量表示正在获取头元素的线程,在代码[1]处的判断是什么意思?假设队列现在是空的,这是线程A进入,发现first为null会调用await方法,进入等待队列。这是他会释放锁,有任务加入。就在此时线程B和线程A同时竞争锁,但是线程B获得了锁,在代码[2]处等待一定时间同时释放锁,但是线程A不一定会被唤醒,除非在B睡眠的时候有任务加入。很巧,此时线程A竞争到了锁,来到[1]处,leader不为null,再次进入await。直到线程B执行完毕,调用了signal方法。
如果任务过期或者到达执行时间返回任务,并且重新组织二叉排序堆
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
int s = --size;
RunnableScheduledFuture<?> x = queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
return f;
}
private void siftDown(int k, RunnableScheduledFuture<?> key) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;// 左子节点下标
RunnableScheduledFuture<?> c = queue[child];// 左子节点
int right = child + 1;// 右子节点下标
if (right < size && c.compareTo(queue[right]) > 0// 如果左子节点大于右子节点
c = queue[child = right];// 将右子节点下标赋值给child,并且将右子节点赋值给c
if (key.compareTo(c) <= 0)// 如果key小于等于c(右节点)跳出
break;
queue[k] = c;// 第一轮将右节点赋值给root,入参k为0,后面循环中作用是`填坑`
setIndex(c, k);// 设置RunnableScheduledFuture的heapIndex属性
k = child;// child为左节点和右节点较小的下标
}
queue[k] = key;// 将key赋值刚给右节点
setIndex(key, k);
}
数组的大小减1,获取最后一个节点同时置位null,调用siftDown方法,入参为0和最后一个节点。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 计划任务线程池,这里就不介绍他的具体使用方式了。其内部有两个重要的内部类,DelayedWorkQueue和ScheduledFutureTask。先看一下schedule方法。
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
RunnableScheduledFuture<?> t = decorateTask(command,new ScheduledFutureTask<Void>(command, null, triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
schedule方法的作用是将定时任务封装为RunnableScheduledFuture类型,并添加值阻塞队列中。至于何时调用,回想线程池中分析过,getTask方法:
private Runnable getTask() {
// 省略...
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
执行poll或者take时会阻塞到任务的执行时间。
总结:
- 计划任务的延时和阻塞功能是在延时队列中实现。
- 文中没有详细的描述ScheduledFutureTask类,该类是对任务的封装,并且scheduleAtFixedRate的也是通过该类实现的,当任务执行完成之后,会再次新建一个任务,加入到延时队列中,这样就可以重复的执行任务了。