Java 并发和线程安全全面解析(一)
作者:冷血狂魔
博客链接:https://my.oschina.net/u/1778239/blog/1610185
一、前言
长久以来,一直想剖析一下Java线程安全的本质,但是苦于有些微观的点想不明白,便搁置了下来,前段时间慢慢想明白了,便把所有的点串联起来,趁着思路清晰,整理成这样一篇文章。
二、导读
1、为什么有多线程?
2、线程安全描述的本质问题是什么?
3、Java内存模型(JMM)数据可见性问题、指令重排序、内存屏障
三、揭晓答案
1、为什么有多线程
谈到多线程,我们很容易与高性能画上等号,但是并非如此,举个简单的例子,从1加到100,用四个线程计算不一定比一个线程来得快。因为线程的创建和上下文切换,是一笔巨大的开销。
那么设计多线程的初衷是什么呢?来看一个这样的实际例子,计算机通常需要与人来交互,假设计算机只有一个线程,并且这个线程在等待用户的输入,那么在等待的过程中,CPU什么事情也做不了,只能等待,造成CPU的利用率很低。如果设计成多线程,在CPU在等待资源的过程中,可以切到其他的线程上去,提高CPU利用率。
现代处理器大多含有多个CPU核心,那么对于运算量大任务,可以用多线程的方式拆解成多个小任务并发的执行,提高计算的效率。
总结起来无非两点,提高CPU的利用率、提高计算效率。
2、线程安全的本质
我们先来看一个例子:
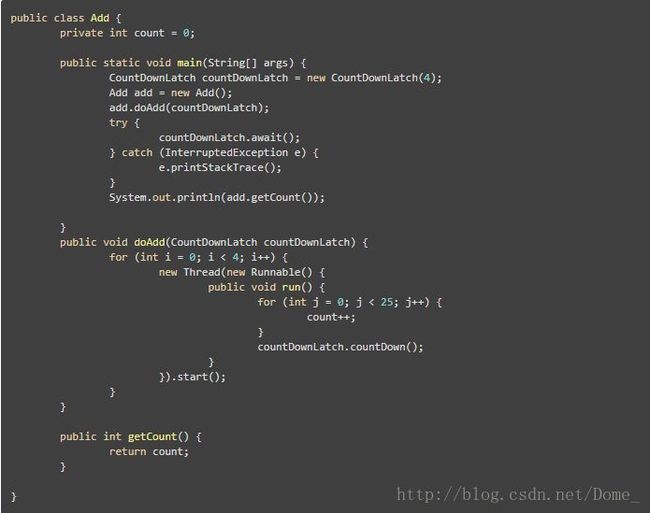
上面是一个把变量自增100次的例子,只不过用了4个线程,每个线程自增25次,用CountDownLatch等4个线程执行完,打印出最终结果。实际上,我们希望程序的结果是100,但是打印出来的结果并非总是100。
这就引出了线程安全所描述的问题,我们先用通俗的话来描述一下线程安全:
线程安全就是要让程序运行出我们想要的结果,或者话句话说,让程序像我们看到的那样执行。
解释一下我总结的这句话,我们先new出了一个add对象,调用了对象的doAdd方法,本来我们希望每个线程有序的自增25次,最终得到正确的结果。如果程序增的像我们预先设定的那样运行,那么这个对象就是线程安全的。
下面我们来看看Brian Goetz对线程安全的描述:当多线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
下面我们就来分析这段代码为什么不能确保总是得到正确的结果。
3、Java内存模型(JMM)数据可见性问题、指令重排序、内存屏障
先从计算机的硬件效率说起,CPU的计算速度比内存快几个数量级,为了平衡CPU和内存之间的矛盾,引入的高速缓存,每个CPU都有高速缓存,甚至是多级缓存L1、L2和L3,那么缓存与内存的交互需要缓存一致性协议,这里就不深入讲解。那么最终处理器、高速缓存、主内存的交互关系如下:

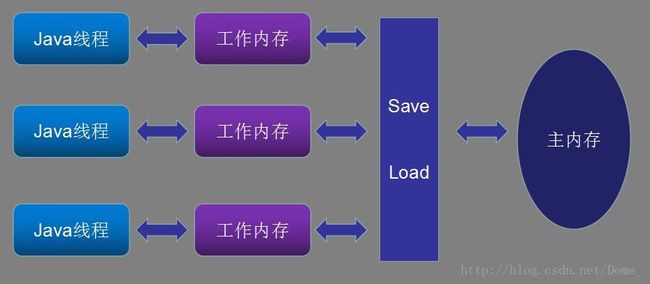
那么Java的内存模型(Java Memory Model,简称JMM)也定义了线程、工作内存、主内存之间的关系,非常类似于硬件方面的定义。
这里顺带提一下,Java虚拟机运行时内存的区域划分
方法区:存储类信息、常量、静态变量等,各线程共享
虚拟机栈:每个方法的执行都会创建栈帧,用于存储局部变量、操作数栈、动态链接等,虚拟机栈主要存储这些信息,线程私有
本地方法栈:虚拟机使用到的Native方法服务,例如c程序等,线程私有
程序计数器:记录程序运行到哪一行了,相当于当前线程字节码的行号计数器,线程私有
堆:new出的实例对象都存储在这个区域,是GC的主战场,线程共享。
所以对于JMM定义的主内存,大部分时候可以对应堆内存、方法区等线程共享的区域,这里只是概念上对应,其实程序计数器、虚拟机栈等也有部分是放在主内存的,具体看虚拟机的设计。
好了,了解了JMM内存模型,我们来分析一下,上面的程序为什么没得到正确的结果。请看下图,线程A、B同时去读取主内存的count初始值存放在各自的工作内存里,同时执行了自增操作,写回主内存,最终得到了错误的结果。

我们再来深入分析一下,造成这个错误的本质原因:
(1)、可见性,工作内存的最新值不知道什么时候会写回主内存
(2)、有序性,线程之间必须是有序的访问共享变量,我们用“视界”这个概念来描述一下这个过程,以B线程的视角看,当他看到A线程运算好之后,把值写回之内存之后,马上去读取最新的值来做运算。A线程也应该是看到B运算完之后,马上去读取,在做运算,这样就得到了正确的结果。
接下来,我们来具体分析一下,为什么要从可见性和有序性两个方面来限定。
给count加上volatile关键字,就保证了可见性。
![]()
volatile关键字,会在最终编译出来的指令上加上lock前缀,lock前缀的指令做三件事情
(1)、防止指令重排序(这里对本问题的分析不重要,后面会详细来讲)
(2)、锁住总线或者使用锁定缓存来保证执行的原子性,早期的处理可能用锁定总线的方式,这样其他处理器没办法通过总线访问内存,开销比较大,现在的处理器都是用锁定缓存的方式,在配合缓存一致性来解决。
(3)、把缓冲区的所有数据都写回主内存,并保证其他处理器缓存的该变量失效
既然保证了可见性,加上了volatile关键词,为什么还是无法得到正确的结果,原因是count++,并非原子操作,count++等效于如下步骤:
(1)、 从主内存中读取count赋值给线程副本变量:
temp=count
(2)、线程副本变量加1
temp=temp+1
(3)、线程副本变量写回主内存
count=temp
就算是真的严苛的给总线加锁,导致同一时刻,只能有一个处理器访问到count变量,但是在执行第(2)步操作时,其他cpu已经可以访问count变量,此时最新运算结果还没刷回主内存,造成了错误的结果,所以必须保证顺序性。
那么保证顺序性的本质,就是保证同一时刻只有一个CPU可以执行临界区代码。这时候做法通常是加锁,锁本质是分两种:悲观锁和乐观锁。如典型的悲观锁synchronized、JUC包下面典型的乐观锁ReentrantLock。
总结一下:要保证线程安全,必须保证两点:共享变量的可见性、临界区代码访问的顺序性。
下一篇博客将从指令重排序、内存屏障等微观的角度,站在线程的视角来看一个乱序的Java世界,请关注下一篇博客《Java并发和线程安全(二)》
快乐源于分享。
此博客乃作者原创, 转载请注明出处
作者:冷血狂魔
博客链接:https://my.oschina.net/u/1778239/blog/1610185
一、前言
长久以来,一直想剖析一下Java线程安全的本质,但是苦于有些微观的点想不明白,便搁置了下来,前段时间慢慢想明白了,便把所有的点串联起来,趁着思路清晰,整理成这样一篇文章。
二、导读
1、为什么有多线程?
2、线程安全描述的本质问题是什么?
3、Java内存模型(JMM)数据可见性问题、指令重排序、内存屏障
三、揭晓答案
1、为什么有多线程
谈到多线程,我们很容易与高性能画上等号,但是并非如此,举个简单的例子,从1加到100,用四个线程计算不一定比一个线程来得快。因为线程的创建和上下文切换,是一笔巨大的开销。
那么设计多线程的初衷是什么呢?来看一个这样的实际例子,计算机通常需要与人来交互,假设计算机只有一个线程,并且这个线程在等待用户的输入,那么在等待的过程中,CPU什么事情也做不了,只能等待,造成CPU的利用率很低。如果设计成多线程,在CPU在等待资源的过程中,可以切到其他的线程上去,提高CPU利用率。
现代处理器大多含有多个CPU核心,那么对于运算量大任务,可以用多线程的方式拆解成多个小任务并发的执行,提高计算的效率。
总结起来无非两点,提高CPU的利用率、提高计算效率。
2、线程安全的本质
我们先来看一个例子:
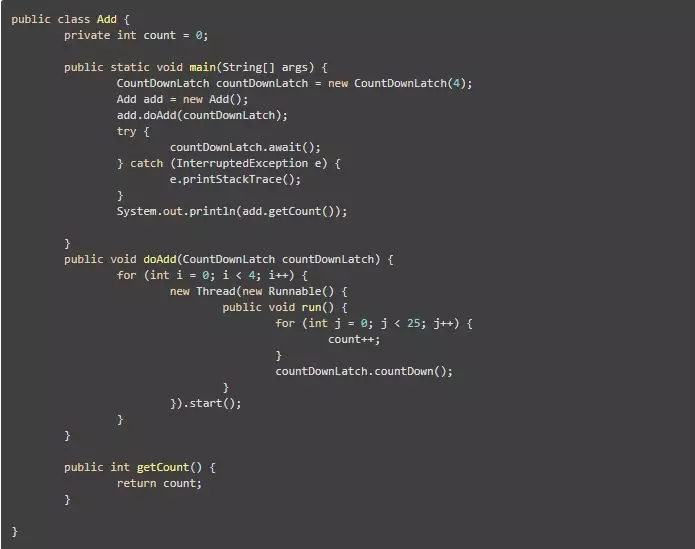
上面是一个把变量自增100次的例子,只不过用了4个线程,每个线程自增25次,用CountDownLatch等4个线程执行完,打印出最终结果。实际上,我们希望程序的结果是100,但是打印出来的结果并非总是100。
这就引出了线程安全所描述的问题,我们先用通俗的话来描述一下线程安全:
线程安全就是要让程序运行出我们想要的结果,或者话句话说,让程序像我们看到的那样执行。
解释一下我总结的这句话,我们先new出了一个add对象,调用了对象的doAdd方法,本来我们希望每个线程有序的自增25次,最终得到正确的结果。如果程序增的像我们预先设定的那样运行,那么这个对象就是线程安全的。
下面我们来看看Brian Goetz对线程安全的描述:当多线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
下面我们就来分析这段代码为什么不能确保总是得到正确的结果。
3、Java内存模型(JMM)数据可见性问题、指令重排序、内存屏障
先从计算机的硬件效率说起,CPU的计算速度比内存快几个数量级,为了平衡CPU和内存之间的矛盾,引入的高速缓存,每个CPU都有高速缓存,甚至是多级缓存L1、L2和L3,那么缓存与内存的交互需要缓存一致性协议,这里就不深入讲解。那么最终处理器、高速缓存、主内存的交互关系如下:

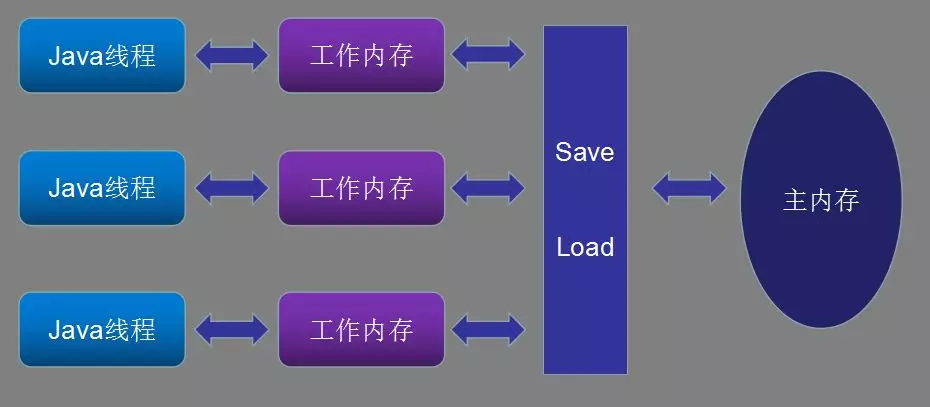
那么Java的内存模型(Java Memory Model,简称JMM)也定义了线程、工作内存、主内存之间的关系,非常类似于硬件方面的定义。
这里顺带提一下,Java虚拟机运行时内存的区域划分
方法区:存储类信息、常量、静态变量等,各线程共享
虚拟机栈:每个方法的执行都会创建栈帧,用于存储局部变量、操作数栈、动态链接等,虚拟机栈主要存储这些信息,线程私有
本地方法栈:虚拟机使用到的Native方法服务,例如c程序等,线程私有
程序计数器:记录程序运行到哪一行了,相当于当前线程字节码的行号计数器,线程私有
堆:new出的实例对象都存储在这个区域,是GC的主战场,线程共享。
所以对于JMM定义的主内存,大部分时候可以对应堆内存、方法区等线程共享的区域,这里只是概念上对应,其实程序计数器、虚拟机栈等也有部分是放在主内存的,具体看虚拟机的设计。
好了,了解了JMM内存模型,我们来分析一下,上面的程序为什么没得到正确的结果。请看下图,线程A、B同时去读取主内存的count初始值存放在各自的工作内存里,同时执行了自增操作,写回主内存,最终得到了错误的结果。

我们再来深入分析一下,造成这个错误的本质原因:
(1)、可见性,工作内存的最新值不知道什么时候会写回主内存
(2)、有序性,线程之间必须是有序的访问共享变量,我们用“视界”这个概念来描述一下这个过程,以B线程的视角看,当他看到A线程运算好之后,把值写回之内存之后,马上去读取最新的值来做运算。A线程也应该是看到B运算完之后,马上去读取,在做运算,这样就得到了正确的结果。
接下来,我们来具体分析一下,为什么要从可见性和有序性两个方面来限定。
给count加上volatile关键字,就保证了可见性。
![]()
volatile关键字,会在最终编译出来的指令上加上lock前缀,lock前缀的指令做三件事情
(1)、防止指令重排序(这里对本问题的分析不重要,后面会详细来讲)
(2)、锁住总线或者使用锁定缓存来保证执行的原子性,早期的处理可能用锁定总线的方式,这样其他处理器没办法通过总线访问内存,开销比较大,现在的处理器都是用锁定缓存的方式,在配合缓存一致性来解决。
(3)、把缓冲区的所有数据都写回主内存,并保证其他处理器缓存的该变量失效
既然保证了可见性,加上了volatile关键词,为什么还是无法得到正确的结果,原因是count++,并非原子操作,count++等效于如下步骤:
(1)、 从主内存中读取count赋值给线程副本变量:
temp=count
(2)、线程副本变量加1
temp=temp+1
(3)、线程副本变量写回主内存
count=temp
就算是真的严苛的给总线加锁,导致同一时刻,只能有一个处理器访问到count变量,但是在执行第(2)步操作时,其他cpu已经可以访问count变量,此时最新运算结果还没刷回主内存,造成了错误的结果,所以必须保证顺序性。
那么保证顺序性的本质,就是保证同一时刻只有一个CPU可以执行临界区代码。这时候做法通常是加锁,锁本质是分两种:悲观锁和乐观锁。如典型的悲观锁synchronized、JUC包下面典型的乐观锁ReentrantLock。
总结一下:要保证线程安全,必须保证两点:共享变量的可见性、临界区代码访问的顺序性。
下一篇博客将从指令重排序、内存屏障等微观的角度,站在线程的视角来看一个乱序的Java世界,请关注下一篇博客《Java并发和线程安全(二)》
快乐源于分享。
此博客乃作者原创, 转载请注明出处