产品发布后,一个QA的总结与思考
题记:上周,产品终于Release了,前后历时近两年时间,期间经历了一次需求变动,四次Interation。产品是新版本开发,需要同时在四个平台(window,Linux,Aix,zLinux)开发,每次迭代实现一个feature。在敏捷盛行的今天,这样的开发周期是很多公司所无法接受的,但作为一个服务器端产品,对软件质量的要求比较高(作为一名资历尚浅的QA,暂浅不评述这种有点类似“螺旋模型”的开发模式的优劣),只想谈谈在每次迭代测试间,我们还有哪些地方可以做得更好!
背景:前一版留有测试用例1600+,其中P1的大概200个左右,P2有600多,剩下主要是P3以及少部分P4。在上一版,在没有automation的来做Regression test的情况下,跑完一轮full cycle,即1600+的测试用例, 差不多需要4名QA,10 working day,也就是每人每天完成40左右的测试用例。
1. 自动化测试
其实之前的版本留有一套自动化测试,但没有任何文档、不稳定、难以维护,所以在做新版产品开发时就决定要投入精力重新开发出一套自动化测试来。作为一个生命周期很长的产品(>5年),有着一套健壮、稳定的自动化测试来做回归测试,以确保代码改动,或新增功能不会影响以前能够正常工作的功能,这是十分又必须要的。需要明确的是:不要期望自动化测试能够帮助你发现新的bug。
其次,在写自动化脚本之前需要明确哪些测试用例有自动化的价值,并不是之前1600+的测试用例都需要实现自动化,比如讲,有些测试用例实现起来很简单,但它的优先级很低,或者有个P2的测试用例,如果要实现自动化,在技术上有很大难度,而且即使实现了,也不能保证很稳定,在这个时候,就需要考虑投入产出比(ROI)。
从技术上讲,自动化框架编码,写自动化脚本并不是十分困难,那难在什么地方呢?我觉得难点在于:自动化测试用例能真实全面反映用户场景。同样的关键字,同样的用例,但不同的人写出来的自动化脚本可能是不同的,不同在于对用例的理解,在于经验。
整个自动化测试完成后的Pass Rate。 如果自动化脚本误报率很高的话,就会让人对自动化测试的可靠性大加怀疑了。为了保证准确性,会在一些keyword中,或则自动化脚本中添加一些容错延时机制。自动化测试完成的时间是可接受的。如果自动化测试跑完需要两三天时间,这就有点无法接受了。要在保证Pass Rate的前提下,尽可能能缩短时间。自动化测试用例的tuning。当代码改动导致自动化测试用例Fail,排除了是bug,这时候要及时调整keyword,或则自动化脚本。
自动化的开发也分成了两个Interation,第一个阶段完成了自动化框架、大部分的keyword和基本的smoke测试用例的自动化,第二个阶段,补充一些keyword,完成regression测试用例。最后,新Feature的自动化。到目前为止,产品的自动化覆盖率差不多40%左右,但覆盖了产品核心功能。
这套自动化测试发现了哪些问题呢?这个问题肯定经常被问到,稍微归纳下:
代码改动导致以前正常工作的功能Fail。举例,之前可以正常处理uuencode编码的邮件(注: UUEncode格式本来就比较难处理),因为一次代码改动fail。
验证HotFix/Patch。一次帮sustain team验证Patch, 打完patch后,没跑几个cases ,系统就挂了。
内存泄露。发现过一次内存泄露,当跑完十几个特定用例后,内存居然被吃光了后Crash。结果发现在跑这十几个cases时,需要reload配置,但每次reload都没释放之前资源。
多线程竞争资源。这次automation 过程中的crash很难重现,最后是RD分析dump文件后找到Root Cause的。
自动化开发过程中的一些经验教训:
- sync-up meeting(也叫stand up meeting)。每天花上十分钟,sync下进度,讨论下在编码、写自动化用例过程中遇到的问题,这在自动化开发初始阶段还是很有必要的。
- 确保每天完成的自动化脚本都能100%通过,然后把这些没问题的自动化脚本和之前的脚本串起来跑,确保没问题。
- 实现好的自动化脚本需要交互检查,看步骤,看检查点是否完备。
- 自动化框架源码、实现的关键字、自动化脚本、配置文件、生成的Data 都必须加入到版本控制系统中去,如SVN,Git都可以。确保代码,脚本没问题后,及时Check in。
- 每天自动化测试的结果整理统计后,发给team里面的人。
- 对于那些Fail的测试用例,需要有人去follow up。
- 当发现测试用例的fail是由代码改动引起的,确认不是bug后,需要及时调整自动化代码,自动化测试用例。记得Check in 你的变动。
- 自动化环境的部署文档,自动化框架和关键字实现文档。前人栽树,后人乘凉的道理,方便他人接手。
现有的自动化测试有哪些不足呢:
- 自动化环境的部署略显复杂。让一个新人跟着文档部署好一套自动化环境,至少需要半天时间,要掌握基本的troubleshoting技巧,写自动化脚本,差不多需要一周时间。
- 自动化关键字的实现稍显复杂。部分原因是Domino这样的环境决定的。
- 部分自动化测试用例执行时间偏长。
- 自动化测试是个持续投入的过程,一套稳健的自动化测试能提高你对产品质量的信心。
2. 迭代测试
基于这样的开发模型,每一轮迭代,和测试相关的活动有这些:写SRS(也可以RD写),SRS的review, 根据SRS完成Test Design,创建测试用例,测试用例review,一轮新功能的测试,每天自动化回归测试,发现问题,验证问题,又一轮新功能测试,最后一轮full cycle测试,实现新功能的自动化,性能测试等。
四轮迭代下来,新增测试用例700左右,提的tracker有360多个。因为早期自动化测试的投入,大大减轻了后期手动回归测试的工作量。可以想象下,四个平台,每个平台又要支持多个操作系统版本,这样的测试工作量!
在每次迭代过程中,就测试而言,有哪些地方可以做的更好呢?
首先,每轮迭代后,是不是可以做下测试用例的Refine,即新创建测试用例的优化,可能创建用例的时候时间比较仓促,对产品的理解不透彻,或其他什么原因,在执行的过程,或多或少都会发现测试用例的不合理,有些测试点缺少测试用例,也就是当初的测试用例没有覆盖,有哪些地方需要优化的呢?
· 测试用例的执行步骤(Step), 预期结果(Expected Result)。 可能是需求的变化,或则创建用例时理解的错误,按照步骤得不到预期结果,这时候就需要调整执行步骤,或则预期结果。
· 测试用例的优先级(Priority)。随着测试的进行,对产品的理解也更加透彻,这时候对测试用例的优先级可能和当初写测试用例的时候有些变化。
· 补充测试用例。回过头来看那些已经发现的bug,你会发现很大一部分不是通过当初设计的测试用例发现的。这时候需要及时补充测试用例。
其次,每一轮迭代测试后,好好分析研究那些已经提交的Tracker, 整理统计这些bug,会学到很多。
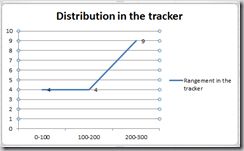
· 在测试的过程中关注Bug曲线、分布。那个著名的测试理论“Defect Clustering”告诉我们bug总是喜欢扎堆出现,通过Bug曲线,你会知道那个模块这段时间需要重点测。下面这两幅并不是Bug曲线图,而是我统计的导致产品Crash的Bug的分布,能告诉我哪些模块的代码质量如何。

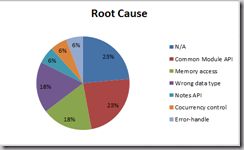
· 关注Bug的Root Cause。我觉得一个好的QA不仅发现Bug, 而且应该有意识的尝试提出Bug预防策略。通过把Bug分类,把Root Cause类似的bug放一起,你会发现很多Bug是可以避免的。比如,之前SEG在处理一个用户提交的bug时,发现这是由于用错了数据类型。而在这一版中,也发现了三四个由于用错数据类型导致crash的例子。如果能整理出来,给RD,让他们有这个意识,这样的Bug可以避免。下面这个图统计的是导致crash的Root Cause有哪些。
· 那些每个Iteration都会出现的Bug。四次迭代,期间都经历的UI的变动,每次添加一个新的Feature,都会在log数据库,Notification,隔离数据库中添加相关的UI界面。你会发现每次那些细微的地方,如log数据库中的delete records, log records, notification中新加的功能的条目, 还有那个Copy按钮,RD在第一次迭代的时候,不会注意到这些地方的UI也需要改动,在第三次迭代的时候RD可能换了一个人,这时候他也不会关注到这些地方,这种类似的问题,每次迭代都提,是不是可以在RD在做这一块的时候,就给予些提醒呢?
· 通过Bug反思测试用例设计。当发现一个Bug并不是通过已有的测试用例发现的(这种情况很常见),特别是新功能,这时候我们可以回忆下当时设计测试用例的时候,是怎么想的,当时采用了什么方法,有没有更好的测试用例设计技术。上一篇文章讲的就是这个问题。
· 通过分析Bug获得测试经验。最近在看<探索式测试>这本书,书中讲到一些测试方法。比如取消测试法,看看那些提交的tracker, 在安装那一块,我们发现有好几个bug,都是关于“back”按钮不起作用的。再如,强迫症测试法,我们发现的一个类似的就是,把我们的一个进程reload十次,就crash了,另一个连续敲15次同样的命令,也crash了。我想说的是这些测试方法,测试经验的总结,而这些测试经验的获取应该是通过与Bug的一次次亲密接触获取的。
转载来自:http://www.cnblogs.com/matt123/archive/2012/11/05/2755900.html