10w行级别数据的Excel导入优化记录
需求说明
项目中有一个 Excel 导入的需求:缴费记录导入
由实施 / 用户 将别的系统的数据填入我们系统中的 Excel 模板,应用将文件内容读取、校对、转换之后产生欠费数据、票据、票据详情并存储到数据库中。
在我接手之前可能由于之前导入的数据量并不多没有对效率有过高的追求。但是到了 4.0 版本,我预估导入时Excel 行数会是 10w+ 级别,而往数据库插入的数据量是大于 3n 的,也就是说 10w 行的 Excel,则至少向数据库插入 30w 行数据。
因此优化原来的导入代码是势在必行的。我逐步分析和优化了导入的代码,使之在百秒内完成(最终性能瓶颈在数据库的处理速度上,测试服务器 4g 内存不仅放了数据库,还放了很多微服务应用。处理能力不太行)。具体的过程如下,每一步都有列出影响性能的问题和解决的办法。
导入 Excel 的需求在系统中还是很常见的,我的优化办法可能不是最优的,欢迎读者在评论区留言交流提供更优的思路
一些细节
数据导入:导入使用的模板由系统提供,格式是 xlsx (支持 65535+行数据) ,用户按照表头在对应列写入相应的数据
数据校验:数据校验有两种:
-
字段长度、字段正则表达式校验等,内存内校验不存在外部数据交互。对性能影响较小
-
数据重复性校验,如票据号是否和系统已存在的票据号重复(需要查询数据库,十分影响性能)
数据插入:测试环境数据库使用 MySQL 5.7,未分库分表,连接池使用 Druid
迭代记录
第一版:POI + 逐行查询校对 + 逐行插入
这个版本是最古老的版本,采用原生 POI,手动将 Excel 中的行映射成 ArrayList 对象,然后存储到 List ,代码执行的步骤如下:
1.手动读取 Excel 成 List
2.循环遍历,在循环中进行以下步骤
-
检验字段长度
-
一些查询数据库的校验,比如校验当前行欠费对应的房屋是否在系统中存在,需要查询房屋表
-
写入当前行数据
3.返回执行结果,如果出错 / 校验不合格。则返回提示信息并回滚数据
显而易见的,这样实现一定是赶工赶出来的,后续可能用的少也没有察觉到性能问题,但是它最多适用于个位数/十位数级别的数据。存在以下明显的问题:
-
查询数据库的校验对每一行数据都要查询一次数据库,应用访问数据库来回的网络IO次数被放大了 n 倍,时间也就放大了 n 倍
-
写入数据也是逐行写入的,问题和上面的一样
-
数据读取使用原生 POI,代码十分冗余,可维护性差。
第二版:EasyPOI + 缓存数据库查询操作 + 批量插入
针对第一版分析的三个问题,分别采用以下三个方法优化
缓存数据,以空间换时间
逐行查询数据库校验的时间成本主要在来回的网络IO中,优化方法也很简单。将参加校验的数据全部缓存到 HashMap 中。直接到 HashMap 去命中。
例如:校验行中的房屋是否存在,原本是要用 区域 + 楼宇 + 单元 + 房号 去查询房屋表匹配房屋ID,查到则校验通过,生成的欠单中存储房屋ID,校验不通过则返回错误信息给用户。而房屋信息在导入欠费的时候是不会更新的。
并且一个小区的房屋信息也不会很多(5000以内)因此我采用一条SQL,将该小区下所有的房屋以 区域/楼宇/单元/房号 作为 key,以 房屋ID 作为 value,存储到 HashMap 中,后续校验只需要在 HashMap 中命中
自定义 SessionMapper
Mybatis 原生是不支持将查询到的结果直接写人一个 HashMap 中的,需要自定义 SessionMapper
SessionMapper 中指定使用 MapResultHandler 处理 SQL 查询的结果集
@Repository
public class SessionMapper extends SqlSessionDaoSupport {
@Resource
public void setSqlSessionFactory(SqlSessionFactory sqlSessionFactory) {
super.setSqlSessionFactory(sqlSessionFactory);
}
// 区域楼宇单元房号 - 房屋ID
@SuppressWarnings("unchecked")
public Map getHouseMapByAreaId(Long areaId) {
MapResultHandler handler = new MapResultHandler();
this.getSqlSession().select(BaseUnitMapper.class.getName()+".getHouseMapByAreaId", areaId, handler);
Map map = handler.getMappedResults();
return map;
}
}
MapResultHandler 处理程序,将结果集放入 HashMap
public class MapResultHandler implements ResultHandler {
private final Map mappedResults = new HashMap();
@Override
public void handleResult(ResultContext context) {
@SuppressWarnings("rawtypes")
Map map = (Map)context.getResultObject();
mappedResults.put(map.get("key"), map.get("value"));
}
public Map getMappedResults() {
return mappedResults;
}
}
示例 Mapper
@Mapper
@Repository
public interface BaseUnitMapper {
// 收费标准绑定 区域楼宇单元房号 - 房屋ID
Map getHouseMapByAreaId(@Param("areaId") Long areaId);
}
示例 Mapper.xml
SELECT
CONCAT( h.bulid_area_name, h.build_name, h.unit_name, h.house_num ) k,
h.house_id v
FROM
base_house h
WHERE
h.area_id = #{areaId}
GROUP BY
h.house_id
之后在代码中调用 SessionMapper 类对应的方法即可。
使用 values 批量插入
MySQL insert 语句支持使用 values (),(),() 的方式一次插入多行数据,通过 mybatis foreach 结合 java 集合可以实现批量插入,代码写法如下:
insert into table(colom1, colom2)
values
( #{item.colom1}, #{item.colom2})
使用 EasyPOI 读写 Excel
EasyPOI 采用基于注解的导入导出,修改注解就可以修改Excel,非常方便,代码维护起来也容易。
第三版:EasyExcel + 缓存数据库查询操作 + 批量插入
第二版采用 EasyPOI 之后,对于几千、几万的 Excel 数据已经可以轻松导入了,不过耗时有点久(5W 数据 10分钟左右写入到数据库)不过由于后来导入的操作基本都是开发在一边看日志一边导入,也就没有进一步优化。
但是好景不长,有新小区需要迁入,票据 Excel 有 41w 行,这个时候使用 EasyPOI 在开发环境跑直接就 OOM 了,增大 JVM 内存参数之后,虽然不 OOM 了,但是 CPU 占用 100% 20 分钟仍然未能成功读取全部数据。故在读取大 Excel 时需要再优化速度。莫非要我这个渣渣去深入 POI 优化了吗?别慌,
先上 GITHUB 找找别的开源项目。这时阿里 EasyExcel 映入眼帘:
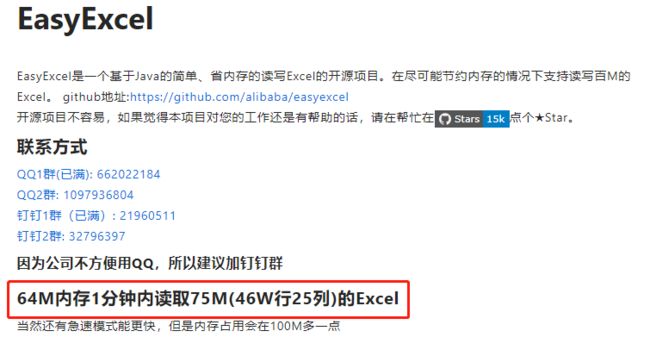
emmm,这不是为我量身定制的吗!赶紧拿来试试。EasyExcel 采用和 EasyPOI 类似的注解方式读写 Excel,因此从 EasyPOI 切换过来很方便,分分钟就搞定了。也确实如阿里大神描述的:41w行、25列、45.5m 数据读取平均耗时 50s,因此对于大 Excel 建议使用 EasyExcel 读取。
第四版:优化数据插入速度
在第二版插入的时候,我使用了 values 批量插入代替逐行插入。每 30000 行拼接一个长 SQL、顺序插入。整个导入方法这块耗时最多,非常拉跨。后来我将每次拼接的行数减少到 10000、5000、3000、1000、500 发现执行最快的是 1000。
结合网上一些对 innodb_buffer_pool_size 描述我猜是因为过长的 SQL 在写操作的时候由于超过内存阈值,发生了磁盘交换。限制了速度,另外测试服务器的数据库性能也不怎么样,过多的插入他也处理不过来。所以最终采用每次 1000 条插入。
每次 1000 条插入后,为了榨干数据库的 CPU,那么网络IO的等待时间就需要利用起来,这个需要多线程来解决,而最简单的多线程可以使用 并行流 来实现,接着我将代码用并行流来测试了一下:
10w行的 excel、42w 欠单、42w记录详情、2w记录、16 线程并行插入数据库、每次 1000 行。插入时间 72s,导入总时间 95 s。

并行插入工具类
并行插入的代码我封装了一个函数式编程的工具类,也提供给大家
/**
* 功能:利用并行流快速插入数据
*
* @author Keats
* @date 2020/7/1 9:25
*/
public class InsertConsumer {
/**
* 每个长 SQL 插入的行数,可以根据数据库性能调整
*/
private final static int SIZE = 1000;
/**
* 如果需要调整并发数目,修改下面方法的第二个参数即可
*/
static {
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "4");
}
/**
* 插入方法
*
* @param list 插入数据集合
* @param consumer 消费型方法,直接使用 mapper::method 方法引用的方式
* @param 插入的数据类型
*/
public static void insertData(List list, Consumer> consumer) {
if (list == null || list.size() < 1) {
return;
}
List> streamList = new ArrayList<>();
for (int i = 0; i < list.size(); i += SIZE) {
int j = Math.min((i + SIZE), list.size());
List subList = list.subList(i, j);
streamList.add(subList);
}
// 并行流使用的并发数是 CPU 核心数,不能局部更改。全局更改影响较大,斟酌
streamList.parallelStream().forEach(consumer);
}
}
这里多数使用到很多 Java8 的API,不了解的朋友可以翻看我之前关于 Java 的博客。方法使用起来很简单
InsertConsumer.insertData(feeList, arrearageMapper::insertList);
其他影响性能的内容
日志
避免在 for 循环中打印过多的 info 日志
在优化的过程中,我还发现了一个特别影响性能的东西:info 日志,还是使用 41w行、25列、45.5m 数据,在 开始-数据读取完毕 之间每 1000 行打印一条 info 日志,缓存校验数据-校验完毕 之间每行打印 3+ 条 info 日志,日志框架使用 Slf4j 。打印并持久化到磁盘。下面是打印日志和不打印日志效率的差别
打印日志

不打印日志

我以为是我选错 Excel 文件了,又重新选了一次,结果依旧

缓存校验数据-校验完毕 不打印日志耗时仅仅是打印日志耗时的 1/10 !
总结
提升Excel导入速度的方法:
-
使用更快的 Excel 读取框架(推荐使用阿里 EasyExcel)
-
对于需要与数据库交互的校验、按照业务逻辑适当的使用缓存。用空间换时间
-
使用 values(),(),() 拼接长 SQL 一次插入多行数据
-
使用多线程插入数据,利用掉网络IO等待时间(推荐使用并行流,简单易用)
-
避免在循环中打印无用的日志