2017CS231n李飞飞深度视觉识别笔记(十一)——图像识别和分割
第十一讲 图像识别和分割
上一章中讲到使用循环神经网络来解决问题,同时也看到这个网络结构在很多方面的应用;目前为止谈论最多的是分类问题,这一章中我们在基于计算机视觉的主题上将讨论目标检测、图像分割等内容。
首先是语义分割,然后分类和定位,最后讨论目标检测及实例分割。
课时1 分割
我们希望输入图像,并对图像中每个像素做分类,对于每个像素,确定它属于猫、草地、天空或者背景亦或者其他分类,首先确定分类,就像做图像分类一样,不过现在不能简单地分一类给整个图像,希望能为每个像素产生一个分类类标,这就叫语义分割。
语义分割并不区分同类目标,例如下图中的两头牛并排站立,解决这个问题的时候是为每个像素分类;而在之前的例子中,输出并不能区分结果,也就是说不会区分这两头牛。

语义分割可能仅通过分类实现,这就是问题所在,可以用滑动窗口来实现语义分割,可以想象用输入图像将其打碎为许多小的、局部的图像块,如下:
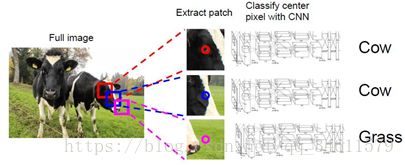
可以用这些小块做分类,但这只能在一定程度上起到作用,并不是完美的解决方案,并且这个方法的计算复杂度很高。
另一个方法是全连接卷积网络,不仅是从图像中提取各个图像块并且分类,还可以把网络当成很多的卷积堆叠在一起。
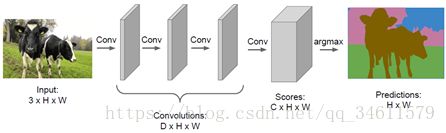
但是如果有比如64或128甚至256个卷积通道,这样运行卷积层在这样高的清晰度逐层训练,可想而知计算量很大会很耗内存;所以我们会在图像内做下采样,之后对特征做上采样,与其全部卷积基于整个图像的全维度,仅仅对一部分的卷积层做原清晰度处理,下采样用包括最大池化或跨卷积。
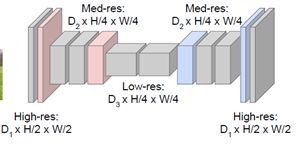
讨论过了下采样,那么怎么进行上采样呢?
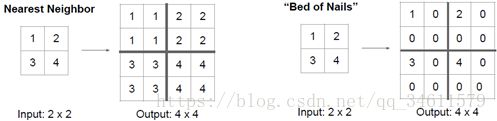
其中一个方法是去池化,上采样做的是最近距离去池化或者钉床函数去池化:
问题:为什么做分割?
答:希望基于像素预测结果尽可能好,想要找到边界让这些细节体现在预测中,如果做最大池化,这种不均匀性会凸显出来,在特征图中,由于最大池化在低清晰度中看不到,会丢失一些空间信息,所以讲向量去池化,它能帮助我们很好的处理细节,帮助我们存储空间信息。
另一个要关注的是转置卷积的概念:
跨卷积就是一种可学习的层,可学习如何下采样针对某一层来做;类比一下叫转置卷积的层,可以用它来做上采样,既上采样特征图又能学习权重,这就是另一种卷积的方式。
跨卷积的过程如下:
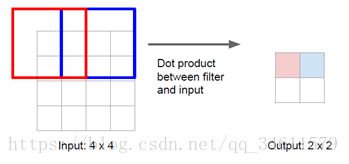
跨卷积的定义是不依次向下放置过滤单元,而是每隔两个像素单元做一次,在输入中,卷积核每次移动一格,输出也这样;所以一个比值为输入中移动距离和输出中移动距离的比。
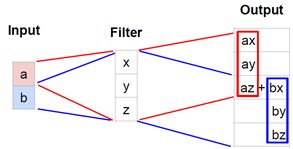
转置卷积的过程如下:

它正好相反,转置卷积不做内乘,而是取特征池的输入值,用这个值乘以卷积核,以3*3的区域的方式复制这些值作为输出。
从一维的角度看卷积转置,如果做3*1的一维转置卷积,可以看到输出是对输入的加权,依次去下移输出中的加权卷积核,跨度为2,最后对的输出中的感受野重叠部分进行叠加。
课时2 定位
接下来我们要讨论的问题是图像分类和定位,刚刚已经谈到过了图像分类,做的是给输入图像分类标签,但有时候也想知道更多关于图像的事,除了预测分类,也想知道图像中内容的定位问题。
定位的情况是提前知道会有一个或几个物体是需要找的,但是预先知道要对这个图像做分类决策,只产生一个边界,这个边界告诉我们物体在图像中的哪里。
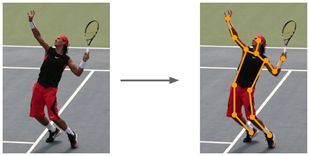
预测图像中固定几个点的位置的想法可以应用到除分类与定位的其他问题上,比如姿态估计。
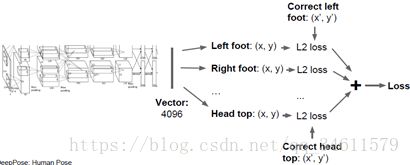
如下图中,拿一张人像作为输入图片,想输出这个人的关节在图中的点位,这样一来就可以在网络中预测这个人的姿态:
输入这张人像后,将输出14个关节点的参数,逐一给出14个关节点的x、y坐标,然后用回归损失(通常是L2损失)来评估这14个点的表现,运用反向传播方法再次训练这个网络。
课时3 识别
下一个要讨论的是对象识别,可以说这在计算机视觉领域占据核心地位。
对象识别主要研究是一开始有固定几个类别,比如猫、狗或其他种类,任务是根据输入的图像,每当在图像中出现其中一类对象时,围绕对象划定一个框并预测该对象从属的类别,因为不知道图像中有多少个对象,所以这个问题是很有挑战性的。
下图是对象识别进程:
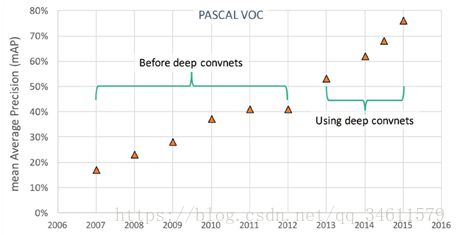
可以看到在深度学习应用于图像识别时,性能水平迅速提高,而如今的识别准确率已经超过了80%。
根据图片中对象的数目不同。所需要的参数也是不一样的,如下图所示:
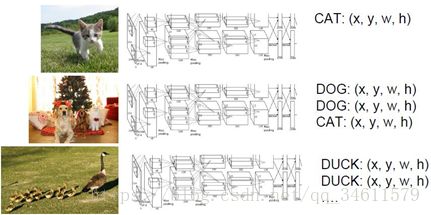
因此,如果把对象识别等同于回归问题考虑会非常棘手,尝试用滑动窗口的方法,类似于图像分割中的将图像划分为小块一样,也可以将其应用到对象识别中去;将图像切分为小块,然后输入到神经网络中,之后网络会对输入的图块进行分类决策。
问题在于如何选择图块,因为图像里的对象数量是不定的,并且它们可能在任何位置,拥有任意尺寸,以任意比例出现,如果想用蛮力,滑动窗口法可能需要测试成千上万次才能处理这个问题,同时计算的复杂度也会很高。
所以相应的会用一种叫做候选区域选择的方法,它更多采用了类似于信号处理、图像处理等方法来建立候选清单,所以对给定的输入图像,候选区域网络在对象周围会给出上千个框,这时就可以进行定位,也就是寻找图像的边界,划定闭合的限定框,区域选择网络会在输入图像中寻找点状的候选区域,也就是对象可能出现的区域。

不同于分类网络在图像的各个位置和范围内进行搜索,首先采取候选区域网络找到物体可能存在的备选区域,再应用卷积神经网络对这些备选区域进行分类,这样做比穷尽所有可能位置的位置和范围要来的更容易一些。
对于候选区域选择有一个改进的方法,不再按感兴趣区域处理,而是通过一些卷积层,整个图像去运行,得到整个图像的高分辨率特征映射,仍旧要用一些备选区域,但不是固定算法(比如选择搜索),而是针对备选区域切分图像的像素,考虑基于备选区域的投影到卷积特征映射,之后从卷积特征映射提取属于备选区域的卷积块而不是直接截取备选区域,通过对整个图像进行处理,当有很多小块时可以重用很多卷积计算。
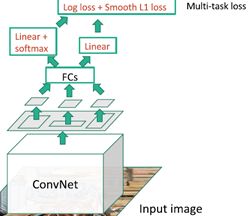
需要强调的是在下游有很多全连接层,这些全连接层的输入应该是固定尺寸的,所以需要对从卷积映射提取出来的图像块进行整形;当通过卷积特征映射得到这些小块,可以通过全连接层运行这些输入预测分类结果以及对线性分类的回归补偿;当训练这个的时候,在反向传播阶段有一个多任务损失,要在这两个约束之间取舍,可以基于全局反向传播同时学习。
还有一种用于目标检测的模型,是一种前馈模型;其中一个模型是YOLO,还有一个是SSD。这类模型的思想不是对这些候选框分别进行处理,而是尝试将其作为回归问题处理,借助于大型卷积网络,所有预测一次完成。
给出输入图像,可以将输入图像分成网格,在每个单元里可以想象一系列的基本边界框,如下图所示:

相对每个网格和每个基本边界框预测几种目标物体,第一要预测边界框偏移从而预测出边界框与目标物体的位置的偏差;第二要预测目标对应类别的分数,所以每个边界框都会对应一个类别分数,即每个物体出现在边界框中的可能性有多大。
课时4 物体分割
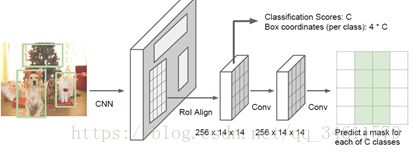
Mask R-CNN是用来解决物体分割最好的方法,这个和Faster R-CNN很像,包含了多步处理,取整张输入图像送进卷积,网络中和训练好的候选框生成网络,得到训练好的候选框后,把候选框投射到卷积特征图上,但并不是进行分类或回归预测边界框,而是想对每一个候选区域的每个边界框预测出一个分割区域。
总结:讨论了不同计算机视觉研究主题的大量工作,也看到了大量源于图像分类任务的结构,可以很容易被应用于解决这些不同的计算机视觉任务