CNN入门算法LeNet-5介绍(论文详细解读)
本文是深度学习经典算法解读的一部分,原文发之:https://www.datalearner.com/blog/1051558603213207
(本网站是合肥工业大学电子商务研究所的知识分享网站。)
来源论文:LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
LeNet-5是LeCun大神在1998年提出的卷积神经网络算法。本篇博客将简要解释相关内容。
在90年代,由于支持向量机(Support Vecotr Machine,SVM)等算法的发展,深度学习的发展受到了很大的阻碍(尽管Geoffery Hinton在1986年发明的BP算法(Backpropagation)解决了神经网络的非线性分类学习的问题,但梯度消失的问题没有得到很好的解决)。但LeCun等人坚持不懈,依然在该领域苦苦研究。1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等(LeNet-2和LeNet-3并没有找到相关资料)。
LeCun也把自己发表的与LeNet相关的论文放到了一起,从1989年到1998年之间共12篇论文。详细请参考:http://yann.lecun.com/exdb/lenet/index.html
本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。第一部分介绍里面说了很多与深度学习有关的经验和内容,比如为什么大数据对深度学习有好处?基于梯度的反向传播算法在深度学习中的作用等等。这些问题的答案在上世纪90年代就有了答案了。第二部分的第一节讲了为什么卷积网络在图像识别领域比全连接网络有效。然后描述了LeNet-5的网络结构,最后总结一下LeNet-5中过时的操作,改进方向等。如果只对LeNet-5感兴趣,可以直接跳到2.B小节中。
关于为什么LeNet-5如此重要,可以参考:
LeNet-5 was used on large scale to automatically classify hand-written digits on bank cheques in the United States. This network is a convolutional neural network (CNN). CNNs are the foundation of modern state-of-the art deep learning-based computer vision. These networks are built upon 3 main ideas: local receptive fields, shared weights and spacial subsampling. Local receptive fields with shared weights are the essence of the convolutional layer and most architectures described below use convolutional layers in one form or another.
Another reason why LeNet is an important architecture is that before it was invented, character recognition had been done mostly by using feature engineering by hand, followed by a machine learning model to learn to classify hand engineered features. LeNet made hand engineering features redundant, because the network learns the best internal representation from raw images automatically.
来自: https://medium.com/pechyonkin/key-deep-learning-architectures-lenet-5-6fc3c59e6f4
一、介绍
LeCun认为,使用机器学习的技术解决模式识别问题变得越发重要。他写这篇论文的一个重要目的就是证明模式识别的系统可以依赖自动学习的技术,而不是手工设计的启发式方法。以字符识别为例,LeCun证明人工设计特征抽取的工作可以通过特别设计的机器学习方法替代,并直接应用在原始的像素图像上。这里字符识别任务是指从识别图像上的字符。当然,LeCun这里想要证明的就是使用神经网络可以较好地做字符识别任务。
在使用机器学习自动识别字符之前,研究者通常使用人工设计特征抽取的方式,将图像的特征抽取出来,然后使用分类器进行分类,得到字符识别的结果。人工设计的特征抽取方法通常叫做视觉描述器(Visual Descriptor - Wikipedia),如局部二值模式(Local Binary Patterns)就是用某个像素周围的8个像素值与之比较,大的是0,小的是1,得到的特征。如下图所示:

使用人工设计的特征抽取结果做字符识别的过程如下:

这样做的原因是当时的分类器只能处理低维空间且容易分类的问题。这种方法最核心的步骤就是设计能力,这是完全手工工作,并且结果主要取决于特征设计能力。
但是,在过去十年中(记住此时是1998年)有三个方面的因素影响了这种识别方法:
- 带有快速运算的低成本机器的可用允许我们更多地依赖“蛮力”的数值运算而不是算法的改进
- 与问题相关的大的数据库的可用性使得研究者更加依赖真实数据而不是人工设计的特征来构造模式识别系统(这么早就意识到了算力和数据的重要性(⊙﹏⊙)牛B)
- 更加强大的算法的出现使得可以处理更高维度的数据并产生更复杂的决策功能
在介绍算法之前,LeCun还描述了五个方面的基础知识,这五个方面内容个人觉得很重要,它回答了很多我们现在习以为常的“结论”,我们分别看一下。
A、从数据中学习(Learning from Data)
在神经网络领域,基于梯度的学习非常流行。我们知道神经网络的学习主要是学习到权重矩阵 的值,也就是找到使得
的值,也就是找到使得![]() 最小,这个
最小,这个 表示的是损失函数。在实际中,对于训练集的误差我们并不是很关心,我们最重要的是降低实际运行的误差。一般会以测试集的形式来度量。注意,这里有一个很重要的结论了。目前,很多理论和实验工作都表明,测试集的误差和训练集误差之间的gap会随着训练集数据的增长而降低,这个值是:
表示的是损失函数。在实际中,对于训练集的误差我们并不是很关心,我们最重要的是降低实际运行的误差。一般会以测试集的形式来度量。注意,这里有一个很重要的结论了。目前,很多理论和实验工作都表明,测试集的误差和训练集误差之间的gap会随着训练集数据的增长而降低,这个值是:
![]()
这里的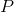 是训练集的样本数量,
是训练集的样本数量, 是一种“有效容量(effective capacity)”的度量,或者说是系统复杂性的度量。α是一个介于0.5到1之间的值,k是一个常量。当训练集数量增长的时候,这个gap值总是降低的。同时,h增长,
是一种“有效容量(effective capacity)”的度量,或者说是系统复杂性的度量。α是一个介于0.5到1之间的值,k是一个常量。当训练集数量增长的时候,这个gap值总是降低的。同时,h增长,![]() 降低。因此,这里有一个权衡,当容量h增长的时候,
降低。因此,这里有一个权衡,当容量h增长的时候,![]() 降低和gap增长之间有一个权衡,我们需要找到一个最优的h值,使得最小化泛化误差
降低和gap增长之间有一个权衡,我们需要找到一个最优的h值,使得最小化泛化误差![]() 。大多数学习方法在降低训练集误差的时候也会估计测试集误差。这个东西的正式名字叫结构风险最小化(structural risk minimization)。
。大多数学习方法在降低训练集误差的时候也会估计测试集误差。这个东西的正式名字叫结构风险最小化(structural risk minimization)。
B、基于梯度的学习(Gradient-Based Learning)
最小化问题是很多计算机领域问题的核心问题。基于梯度的学习证明最小化连续的函数要比最小化离散函数更容易。在本文中,大多数未知数的梯度求解都是很容易的。也就是我们只要循环求解下式即可:
![]()
这里的ϵ就是步长,最简单的情况下,这个值是一个常数,当然也有人使用变量。有人使用对角矩阵表示,或者是在牛顿方法中,使用逆-海塞(inverse-Hessian)矩阵,或者使用共轭梯度方法。在论文的附件B中,作者证明了这些与论文中的声明相反,这些二阶方法在大规模学习中非常有限。
这里,随机梯度下降(Stochastic Gradient Descent)方法是很有效的。在较大数据规模下,这个方法在很多时候都比常规的梯度下降方法或者二阶方法更快地收敛(当然,现在深度学习一般用Adam更多了,这个以后有机会再说)。随机梯度下降方法有效的原因作者也在附件B中解释了。这个方法在60年代有集中的理论研究,但是直到80年代中期才有实际的成功运用。
C、梯度后向传播(Gradient Back Propagation)
基于梯度的学习在20世纪50年代末期开始被使用,但主要是应用在线性系统中。LeCun认为这种简单的方法现在可以用在复杂系统中主要是由于三个方面的原因。我们分别看一下。
第一个是之前认为的局部最优问题并不是主要的问题。在非线性基于梯度的学习技术,如玻尔兹曼机(Boltzmann machines)的成功之后,局部最优并不是一个主要的障碍变得很明显(apparent)。
第二个是Rummelhart等人提出的一个简单的但却很有效的梯度计算方法的流行,该方法可以用来处理多个层组成的复杂系统,即反向传播算法(back-propagation)。
第三个是反向传播方法和sigmoid单元在神经网络中的应用可以用来解决复杂的学习任务。
反向传播算法的基本思想是梯度可以通过从输出到输入的计算得到。这个思想在20世纪60年代在控制论论文中提出,直到最近才运用到机器学习中。有意思的是,之前在神经网络中反向传播的推导并不是用的“梯度”,用的是中间层单元的虚拟目标(vertual targets)或者是最小干扰参数(minimal disturbance arguments)。而那个控制论文献中提供的lagrange formalism可能是推导反向传播最理想的方法。
多层神经网络中局部最优问题似乎不是一个问题,这一点在理论上是有点“神秘”的。如果网络的大小相对于任务来说过大的话,那么参数空间中“多余的维度(extra dimensions)”将会降低无法触及区域的风险。反向传播是目前最广泛的神经网络的学习方法,也许是任何形式的最广泛的学习方法。(这一点其实还没有具体描述清楚,也就是理论上其实目前并不清楚,但就是有效。这是二十多年前的观点了)
D、手写识别系统的学习
在这一段中,LeCun主要说明了手写识别系统的算法目前看神经网络效果最好,尤其是卷积神经网络。可以直接从像素图像中抽取相关特征。
当然,手写识别最困难的是要把字符从它邻居中隔开,也就是分割(segmentation)。主要是先用启发式方法产生大量可能的分割结果,然后基于得分找出最好的一个。这种情况,分割的质量主要取决于生成分割的启发式方法以及如何找出最匹配的分割结果。这里,使用人工标出不正确的分割非常重要。显然这种方式不仅非常耗时费力,而且非常困难。比如8的右边分出来之后应该标注为3还是8呢?
在这篇文章中,LeCun提出了两个方法解决这个问题。一个是优化全局的损失函数,第二个方法是识别出每一个可能的分割结果,并选出最中心的字符。
E、全局训练系统
如前所述,大多数的识别系统都是多个模块的。例如,文档识别系统由field定位器、field分割器和识别器组成,还包括一个情景后处理器。一般情况下,模块之间的通信都是数字信息。
最好的方式应该是全局系统都是最小化一个目标来获得文档级别的识别准确性。LeCun据此提出了一个由多个可微的神经网络组成的前馈网络。每一个模块都是连续且可微的。这样就使得我们可以通过反向传播算法优化整个系统了。
二、用于字符识别的卷积神经网络
在传统的模式识别任务中,通常需要先人工设计特征抽取方法,从输入变量中消除不相关的变量,然后构造特征,再使用一个分类器方法进行分类。在这种情况下,全连接的多层神经网络作为分类器使用。但是,我们也可以依赖算法自己学习特征抽取的部分。以字符识别为例,我们可以以几乎原始的输入数据来作为网络的输入。但是这也有一些问题:
首先,一般来说图片都是比较大的,一个图片通常都有好几百个变量(像素)。假如神经网络的第一层有100个神经元。那么这里就已经有数以万计的权重了。这么大的参数数量需要更复杂的系统,更多的训练集样本。此外,这么多的参数也需要更多的内存,这就已经让一些机器无法使用了。但是,最主要的问题还是这样的网络不能处理不同输入的情况。在输入到神经网络固定大小的的第一层之前,输入的图像必须是标准大小,且是图像的正中间(也就是输入的图像需要比较正式,不能偏差太大)。不幸的是,并没有一个完美的预处理方法可以达到这样的效果。因为输入的图像一般不是很正规的图像,大小、位置甚至是风格都不同。当然,如果网络足够大,这样的有较大差别的图像也是可以处理的,只是这需要很大的网络,目前这样的网络无法训练。
其次,全连接网络也会忽视输入的拓扑特征。输入变量可以以任何顺序呈现,但却不影响输出。但实际上,图像有很强的局部特征:那些相近的变量具有很强的相关性。局部相关性也就是为什么在识别空间或者时间相关的目标的时候,先抽取并联合局部特征可以提升效果。因为相邻的变量可以被分到一个相同的小类别中。
A、卷积网络
卷积网络联合了三个架构特征导致了转换、拉伸和扭曲的不变形:1)局部感受野(Local Receptive Fields);2)共享权重(Shared Weights);3)时间和空间的二次抽样(Spatial or Temporal Subsampling)。
局部感受野就是接受输入的几个相邻的单元来操作。它可以追溯到20世纪60年代早期的感知机时代。局部连接在神经网络处理视觉问题中很常见。局部感受野可以抽取图像初级的特征,如边、转角等。这些特征会在后来的层中通过各种联合的方式来检测高级别特征。此外,局部初级的特征也能在全局图像中发挥作用。这个知识可以用来强制某些单元,其感受野在图像的不同位置,但是拥有相同权重。一个层里面的单元,可以通过平面的方式共享权重。这样一个平面的输出结果可以称作是feature map(这个feature map就是一个卷积核的输出结果)。一个feature map内部的单元可以做相同的操作。一个卷几层可以有多个feature map组成,因此,每个位置都可以抽取多个特征。
这一段这么啰嗦其实就是卷积操作的基本知识。还有一些关于卷积的操作,这里说的是二次抽样,其实是一个概念,就不细说了。
B、LeNet-5
接下来就是重点内容,我们介绍一下LeNet-5的结构。LeNet-5是用来处理手写字符的识别问题的。总共有7层。其结果如下:
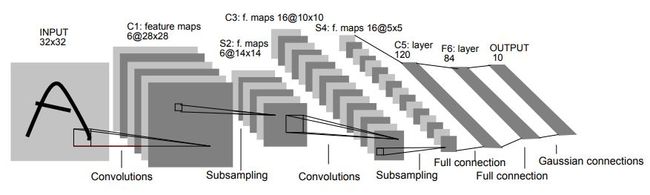
LeNet-5结构:
输入:32x32的灰度图像,也就是一个通道,那么一个图像就是一个2维的矩阵,没有RGB三个通道。
Layer1:6个大小为5x5的卷积核,步长为1。因此,到这里的输出变成了28x28x6。
Layer2:2x2大小的池化层,使用的是average pooling,步长为2。那么这一层的输出就是14x14x6。
Layer3:16个大小为5x5的卷积核,步长为1。但是,这一层16个卷积核中只有10个和前面的6层相连接。也就是说,这16个卷积核并不是扫描前一层所有的6个通道。而是只扫描其中的三个。

这么做的原因是打破图像的对称性,并减少连接的数量。如果不这样做的话,每一个卷积核扫描一层之后是10x10,一个核大小是5x5,输入6个通道,输出16个,所以是10x10x5x5x6x16=240000个连接。但实际上只有156000连接。训练参数的数量从2400变成了1516个。
Layer4:和第二层一样,2x2大小的池化层,使用的是average pooling,步长为2。
Layer5:全连接卷积层,120个卷积核,大小为1x1。
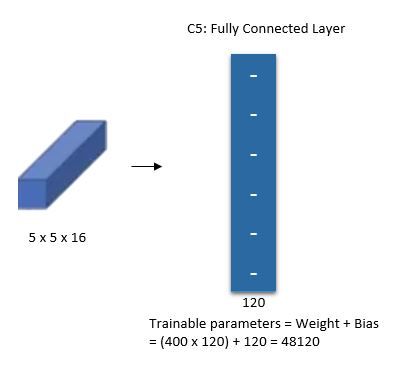
这里的第五层转换理解起来有点困难,第四层结束输出为16x5x5,相当于这里16x5x5展开为400个特征,然后使用120神经元去做全连接,如下图所示:
Layer6:全连接层,隐藏单元是84个。
Layer7:输出层,输出单元是10个,因为数字识别是0-9。
最终,LeNet-5的总结如下:
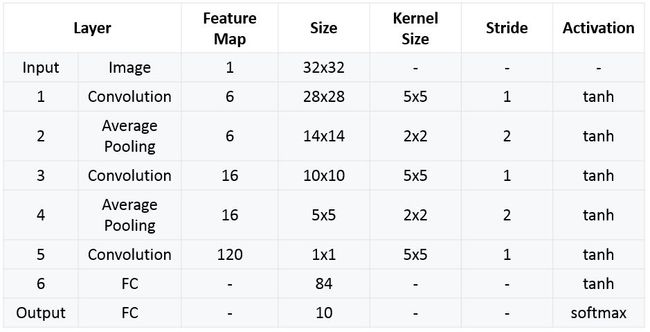
这部分来源参考:https://engmrk.com/lenet-5-a-classic-cnn-architecture/
三、LeNet特点
LeNet有一些操作,在现在看来并不是很常见。第一个就是第三层的卷几层并没有利用上一层所有的通道。这个一般很少这么做。这个一方面是减少了训练参数,一方面也是希望能检测到不同的模式。另一个是输出层之前加了一个全连接层,也就是强制要把所有的图像变成一个84维的向量,然后去分类。还有一点就是使用average pooling。这个一般现在主要是用maxpooling,因为maxpooling的效果更好。
参考:https://medium.com/pechyonkin/key-deep-learning-architectures-lenet-5-6fc3c59e6f4
四、LeNet-5的代码实现
代码实现:https://github.com/TaavishThaman/LeNet-5-with-Keras