Mnist数据集单隐层BP神经网络参数调优
本次对mnist数据集采用单隐层的BP神经网络,在对参数初始化,激活函数,学习率,正则系数选择,隐层神经元数量选择,随机采样样本数量进行调优后,模型在测试集上的正确率可以达到98%。
1、 参数初始化方式
首先调优w和b的初始化,对比了0矩阵赋值tf.zero,均值和方差为0的正太分布赋值tf.random_normal,发现随机赋值可以收敛速度更快更好,故而选择了随机赋值。
2、 激活函数
在选择0.3作为学习率时,sigmoid最慢,50k时仅0.97,到200k步时准确率才达到0.9722;而relu较快但正确率在50k时时0.978左右,selu在50k就可以达到0.9804
三种常用激活函数的特点
使用不同模型在minist测试集上,学习率取0.3时,正确率随步数变化 |
|||
步数(k步) |
sigmoid |
relu |
selu |
5 |
0.9426 |
0.9491 |
0.954 |
10 |
0.9641 |
0.9687 |
0.9715 |
15 |
0.9668 |
0.9796 |
0.9748 |
20 |
0.9618 |
0.9827 |
0.971 |
25 |
0.9647 |
0.9833 |
0.977 |
30 |
0.9657 |
0.9834 |
0.979 |
40 |
0.9689 |
0.984 |
0.9814 |
50 |
0.969 |
0.9827 |
0.9814 |
60 |
0.9701 |
0.9827 |
0.981 |
80 |
0.9703 |
0.9827 |
0.9813 |
100 |
0.9705 |
0.9828 |
0.981 |
200 |
0.9722 |
0.984 |
0.9804 |
本次对三种不同的模型,其中relu的性能最好0.984,selu其次,sigmoid最差也最慢,而本文选择暂选择了selu作为进一步的数据探索。
3、 学习率
3.1采用固定学习率
首先对比了0.1、0.2、0.25、0.3、0.35、0.4、0.45、0.5、0.7、0.9在计算收敛,此处计算50k步,结果显示learn_rate=0.3-0.4时效果不错。
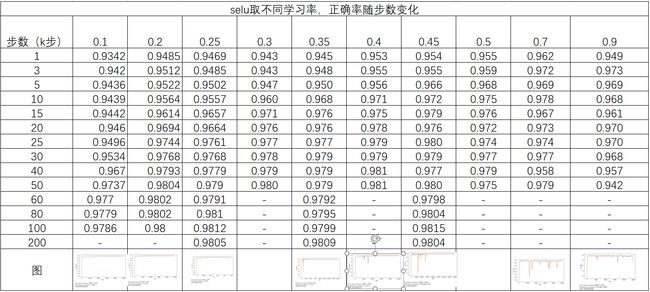
3.2采用可衰减学习率
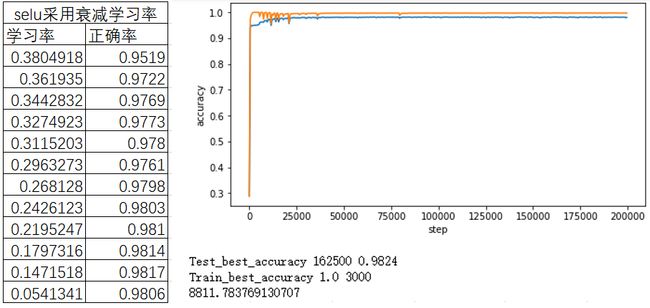
考察了学习率衰减的效果,对比了学习率在不同衰减速率下的效果,结果显示当学习率取0.4时,模型的收敛速度与准确率较好,其在200k步左右可以达到最高进度。故而选择带衰减率的学习率,使得学习率在20k步时前保持0.4,随后开始衰减。
4、 正则参数
通过对比不同正则参数对训练集和测试集上准确率造成的影响,后发现需要将模型训练收敛后才能判断参数是否适合,本次调优训练5k步,进行观测。
判断的标准时,正则对应训练集的正确率需要达到100%,在此间选择测试集上正确率最高的,本次调优选择的正则参数是0.0004.
5、 隐层神经元数量
历遍100~2000区域,训练100k步后,选择了神经元数量=1200
6、 对min_batch进行调优
在历遍100~1000的区域,训练100k步后选择了神经元数量=550
defTrain(batch_size=550,n1=1000,learn_rate_0=0.4,learn_rate_reduce=0.00001,regular_rate=0.0004,steps=10000,plot=False):
#此为第一层数据输入层
w1=tf.Variable(tf.random_normal([784,n1]))
b1=tf.Variable(tf.random_normal([n1]))
logits_1=tf.matmul(x,w1)+b1
keep_prob = tf.placeholder(tf.float32)
logits_1_drop = tf.nn.dropout(logits_1, keep_prob)
h1=tf.nn.selu(logits_1)
#单层神经网络,相当于一个数据784维,其分10个神经元输出故而每个神经元的权重w都有784个
w2 = tf.Variable(tf.random_normal([n1,10]))
b2 = tf.Variable(tf.random_normal([10]))
y= tf.matmul(h1, w2) + b2
#Define loss and optimizer
#定义我们的ground truth 占位符
y_ = tf.placeholder(tf.float32, [None, 10])
#使用正则函数
# L2_loss=regular_rate*(tf.nn.l2_loss(w1)+tf.nn.l2_loss(b1)+tf.nn.l2_loss(w2)+tf.nn.l2_loss(b2))
tv = tf.trainable_variables()
regularization_cost = regular_rate* tf.reduce_sum([ tf.nn.l2_loss(v) forv in tv ])
#接下来我们计算交叉熵,注意这里不要使用注释中的手动计算方式,而是使用系统函数。
#另一个注意点就是,softmax_cross_entropy_with_logits的logits参数是**未经激活的wx+b**
#此处定义损失函数
cross_entropy =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y)+regularization_cost)
learn_rate=learn_rate_0*math.exp(-1*learn_rate_reduce*1)
#生成一个训练step
train_step =tf.train.GradientDescentOptimizer(learn_rate).minimize(cross_entropy)
sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op)
#在这里我们仍然调用系统提供的读取数据,为我们取得一个batch。
#然后我们运行3k个step(5 epochs),对权重进行优化。
acc_dict_train={}
acc_dict={} #用于存储一次运行中acc vs step
for step in range(steps):
#生成可衰减的学习率
learn_rate=learn_rate_0*math.exp(-1*learn_rate_reduce*step)
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y_:batch_ys,keep_prob:0.5})
if step%500==0:
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#获取测试集上的accuracy
acc=sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels,keep_prob:1})
acc_dict[step]=acc
#获取训练集上的accuracy
acc_train=sess.run(accuracy, feed_dict={x: mnist.train.images,
y_:mnist.train.labels,keep_prob:1})
acc_dict_train[step]=acc_train
if plot==True:
print(step,round(step/steps*100,1),'%',acc,learn_rate)
#将accuracy随step变化绘制出来
if plot==True:
plt.figure(figsize=(8,4))
plt.plot(acc_dict.keys(),acc_dict.values())
plt.plot(acc_dict_train.keys(),acc_dict_train.values())
plt.xlabel('step')
plt.ylabel('accuracy')
plt.show()
best_value=max(acc_dict.values())
best_key=list(acc_dict.keys())[list(acc_dict.values()).index(best_value)]
print('Test_best_accuracy',best_key,best_value)
best_value_train=max(acc_dict_train.values())
best_key_train=list(acc_dict_train.keys())[list(acc_dict_train.values()).index(best_value_train)]
print('Train_best_accuracy',best_value_train,best_key_train)
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
acc=sess.run(accuracy, feed_dict={x: mnist.test.images,
y_:mnist.test.labels,keep_prob:1})
return(acc,acc_train)