[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人
图像补全是深度学习领域的热门应用。本文解析和实现论文Image Fine-grained Inpainting中的相关方法。论文亮点在于新增了一种多尺度特征融合的结构,并加入多个的损失用于辅助鉴别生成图像,使生成图像在各个尺度的特征与真实图像匹配。作者本身是有代码库的,但是可能因为疫情影响,仅上传了最后的结果。由于论文中的效果非常好,根据自己动手的原则,笔者按照论文实现了一下算法的各个细节,从最后结果来看,效果确实很不错。
[训练1 epoch的结果]

[训练3 epoch的结果]
补全图

待补全图

原图

【论文地址】
【作者源码地址】
【笔者实现地址】
GAN
一般图像补全算法的补全部分由一个叫GAN(Generative Adversarial Network,生成对抗网络)部分构成。GAN由2个部分构成,鉴别部分(discriminative network)和生成部分(generative network),分别负责鉴别真假图像和生成假图像。最初GAN使用一团无意义的噪声生成虚假图像,以扩充训练数据。现在GAN被广泛用于各种任务,如半监督学习、图像超分辨率、视频补帧,还有本次的任务——图像补全。
EsrGan
一般GAN的损失由两部分构成,生成器和鉴别器损失,两种损失互相对抗,让GAN最后能够生成以假乱真的图像。
本论文中GAN为EsrGAN,其中生成器损失如下:
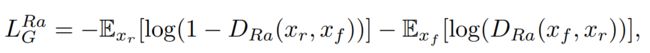
鉴别器损失如下:
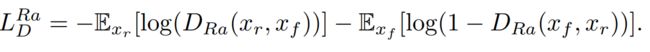
观察上式,发现明显的特点,两个公式就是把Dra()部分中的xr和xf部分交换了一下,符合GAN的基本思想:鉴别器负责鉴定真实图像,生成器负责生成虚假图像。
用python代码实现部分如下:
def Dra(self, x1, x2):
return x1 - torch.mean(x2)
self.G_loss_adv = (self.BCEloss(self.Dra(xr, xf), self.zeros) + self.BCEloss(self.Dra(xf, xr), self.ones)) / 2
self.D_loss = (self.BCEloss(self.Dra(xr, xf), self.ones) + self.BCEloss(self.Dra(xf, xr), self.zeros)) / 2
生成网络设计(亮点)
生成网络最重要的部分是作者引入了一个多个尺度融合的网络(类似inception),使用空洞卷积在不增加参数的情况下额外扩大了感受野。下图是论文中新增的DFMB模块。
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第1张图片](http://img.e-com-net.com/image/info8/75875251d18541dc881204318804c72b.jpg)
具体实现参见https://github.com/HannH/DMFN/blob/2ade61431e243734a9de54c9770856a6fca9ba8c/model/net.py#L15-L46
鉴别网络设计
论文鉴别网络使用了和GMCNN中类似的Global Discriminator和Local Discriminator设计,这种方式可以同时获取补全后的完整图像和补全部分的信息,避免模型出现仅仅关注补全那一部分时带来的误判。下图是鉴别网络结构:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第2张图片](http://img.e-com-net.com/image/info8/023713c267934115ae5173454b570b7e.jpg)
损失设计(亮点)
论文增加了2类损失以真实反映生成图像和真实图像在各个尺度上的特征匹配程度,并用实验数据对这些损失的效果做了验证,结果如下:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第3张图片](http://img.e-com-net.com/image/info8/256bf54b7ab84a57a8be586db1a4e5e7.jpg)
鉴别网络损失
论文额外对鉴别网络各层的输出作了匹配,公式如下:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第4张图片](http://img.e-com-net.com/image/info8/4b8751219b86456dadde37578af72992.jpg)
实现非常简单,就是将鉴别网络中各层的输出,然后用l1_loss对结果进行损失计算。
def forward_fm_dis(self, real, fake, weight_fn):
Dreal = self.local_discriminator(real, middle_output=True)
Dfake = self.local_discriminator(fake, middle_output=True)
fm_dis_list = []
for i in range(5):
fm_dis_list += [F.l1_loss(Dreal[i], Dfake[i], reduction='sum') * weight_fn(Dreal[i])]
fm_dis = reduce(lambda x, y: x + y, fm_dis_list)
return fm_dis
vgg损失
与GMCNN类似,论文作者也引入了VGG提取特征,并设计了多个损失利用VGG提取的特征
1.self guided损失。该损失利用了真实图像和虚假图像的差分图做引导图。公式如下:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第5张图片](http://img.e-com-net.com/image/info8/90e9fd34ff0c4cb2935deca08b8841ca.jpg)
代码实现如下:
guided_loss_list = []
mask_guidance = mask_guidance.unsqueeze(1)
for layer in self.self_guided_layers:
guided_loss_list += [F.l1_loss(gen_vgg_feats[layer] * mask_guidance, tar_vgg_feats[layer] * mask_guidance, reduction='sum') * weight_fn(tar_vgg_feats[layer])]
mask_guidance = self.avg_pool(mask_guidance)
self.guided_loss = reduce(lambda x, y: x + y, guided_loss_list)
2.content损失。该损失利用VGG提取的真实图像和虚假图像特征作输入(区别1损失),求取两者的l1 loss。公式如下:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第6张图片](http://img.e-com-net.com/image/info8/52e5a4edb06846738a1fdbb9fba9a8d7.jpg)
代码如下:
content_loss_list = [F.l1_loss(gen_vgg_feats[layer], tar_vgg_feats[layer], reduction='sum') * weight_fn(tar_vgg_feats[layer]) for layer in self.feat_vgg_layers] self.fm_vgg_loss = reduce(lambda x, y: x + y, content_loss_list)
3.align_loss损失。该损失利用类似质心求取的方式,引入像素位置对损失产生影响,从而计算特征位置偏移导致的细节误差。公式如下:
![[图像补全]Image Fine-grained Inpainting论文解析与实现,效果惊人_第7张图片](http://img.e-com-net.com/image/info8/f2e6db27470d4d0cbd86b8544ecc0ce8.jpg)
代码如下(经作者指出,已将求和范围改为[-1,1]):
```
def calc_align_loss(self, gen, tar):
def sum_u_v(x):
area = x.shape[-2] * x.shape[-1]
return torch.sum(x.view(-1, area), -1) + 1e-7
sum_gen = sum_u_v(gen)
sum_tar = sum_u_v(tar)
c_u_k = sum_u_v(self.coord_x * tar) / sum_tar
c_v_k = sum_u_v(self.coord_y * tar) / sum_tar
c_u_k_p = sum_u_v(self.coord_x * gen) / sum_gen
c_v_k_p = sum_u_v(self.coord_y * gen) / sum_gen
out = F.mse_loss(torch.stack([c_u_k, c_v_k], -1), torch.stack([c_u_k_p, c_v_k_p], -1), reduction='mean')
return out
```
总结
这个论文是目前笔者看到的图像补全最好的算法,其中多尺度特征匹配的方法让人耳目一新,希望对各位后面设计对抗生成网络有帮助。笔者凭着兴趣的算法实现,与作者原本的想法可能有差距。如果有不对的地方,欢迎指出。