MNIST手写字体数据集神经网络实现(tensorflow)
1.MNIST数据集简介
当我们学习编程时,第一节课会学习一个简单的“Holle Word”程序,而MNIST手写字体识别算得上是机器学习的“Holle Word”。MNIST数据集是由一些手写数字的图片和相应的标签组成。图片一共10类,分别对应0~9.
数据结构:
| 数据分类 | 图像数量/张 | 图像向量 | 标签向量 | 图像尺寸 |
| 训练集 | 55000 | [784, 1] | [10, 1] | 28× 28 |
| 训练集 | 10000 | [784, 1] | [10, 1] | 28× 28 |
2.数据集图片显示
# -*- coding: utf-8 -*-
import tensorflow as tf
import pylab
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
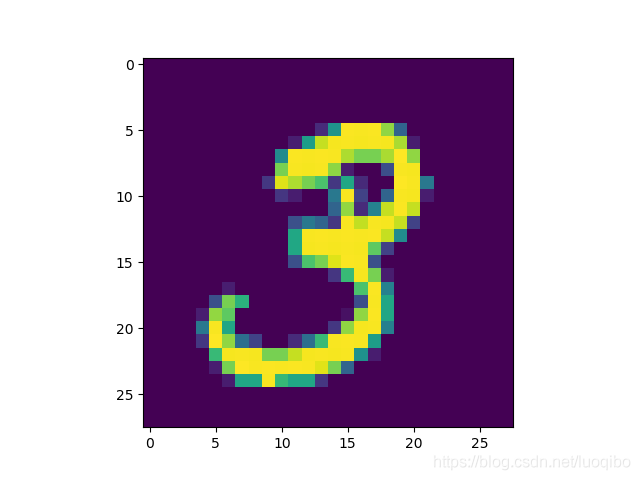
imx = mnist.train.images[1]
print ("image shape", imx.shape)
imy = mnist.train.labels[1]
print ("label shape", imy.shape)
imx = imx.reshape(-1,28) #整理一下形状28*28
print ("整形过得数据", imx.shape)
print ( imx ) #打印原始数据
print ( imy )
pylab.imshow(imx) #显示图片
pylab.show()
其他信息就不放在上面了,
3.神经网络结构
直接上图

4.程序
一开始只是训练,慢慢的加入了指数衰减学习率、L2正则化和Dropout。
# -*- coding: utf-8 -*-
import tensorflow as tf
import matplotlib.pyplot as plt
import time # 引入time模块
start =time.clock()
step = []
test_accuracy = []
training_accuracy = []
# 导入 MINST 数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#参数设置
training_epochs = 500 #训练的轮数
batch_size = 50 #每次训练包含的数据个数,
display_step = 10
LEARNING_RATE_BASE = 0.01 #最初学习率
LEARNING_RATE_DECAY = 0.99 #学习率衰减率
LEARNING_RATE_STEP \
= mnist.train.num_examples/batch_size #喂入多少轮BATCH_SIZE后,更新一次学习率,一般设为:总样本数/BATCH_SIZE
#运行了几轮BATCH_SIZE的计数器,初值给0,设为不被训练
global_step = tf.Variable(0, trainable=False)
# 网络参量
n_input = 784 # MNIST data 输入 (img shape: 28*28)
n_hidden_1 = 392 # 1st layer number of features
n_hidden_2 = 392 # 2nd layer number of features
n_classes = 10 # MNIST 列别 (0-9 ,一共10类)
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32)
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
layer_1 = tf.nn.dropout(layer_1, keep_prob=keep_prob)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
layer_2 = tf.nn.dropout(layer_2, keep_prob=keep_prob)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# Store layers weight & bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# 构建模型
pred = multilayer_perceptron(x, weights, biases)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
# Define loss and optimizer
reg = 0.01
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) \
+ tf.nn.l2_loss(weights['h1'])*reg + tf.nn.l2_loss(weights['h2'])*reg
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost, global_step=global_step)
# 初始化变量
init = tf.global_variables_initializer()
# 启动session
with tf.Session() as sess:
sess.run(init)
# 启动循环开始训练
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# 遍历全部数据集
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_x,
y: batch_y, keep_prob: 0.8})
avg_cost += c
avg_cost = avg_cost / total_batch # 计算平均损失
# 显示训练中的详细信息
if epoch % display_step == 0:
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
train_acc = accuracy.eval({x: mnist.train.images, y: mnist.train.labels, keep_prob: 1}, session=sess)
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost), "Accuracy:", '%g' % train_acc)
training_accuracy.append(train_acc)
step.append(epoch)
print(sess.run(learning_rate))
print (" Finished!")
# 测试
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels, keep_prob: 1}))
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
end = time.clock()
Running_time=float(end-start)/60
print('Running time: %g 分钟'% float(Running_time))
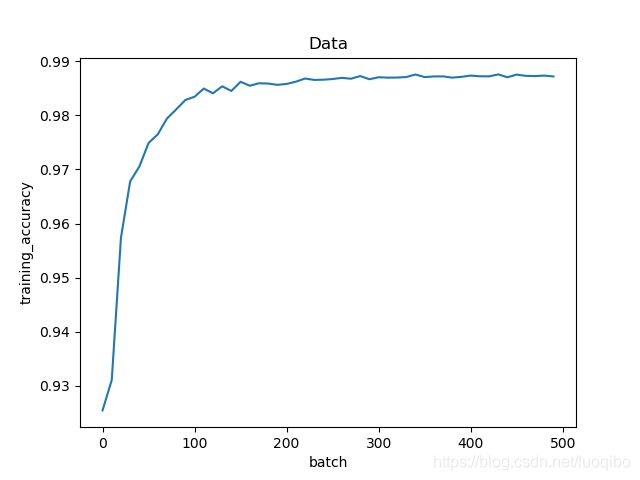
plt.plot(step, training_accuracy)
plt.xlabel('batch')
plt.ylabel('training_accuracy')
plt.title('Data')
plt.show()4.结果
Epoch: 0491 cost= 0.184582227 Accuracy: 0.988291
Finished!
Accuracy: 0.9785
2019-10-31 21:02:46
Running time: 14.0165 分钟训练时的精度随训练批次的变化如下图