【YOLO V4】目标检测模型之YOLO V4框架
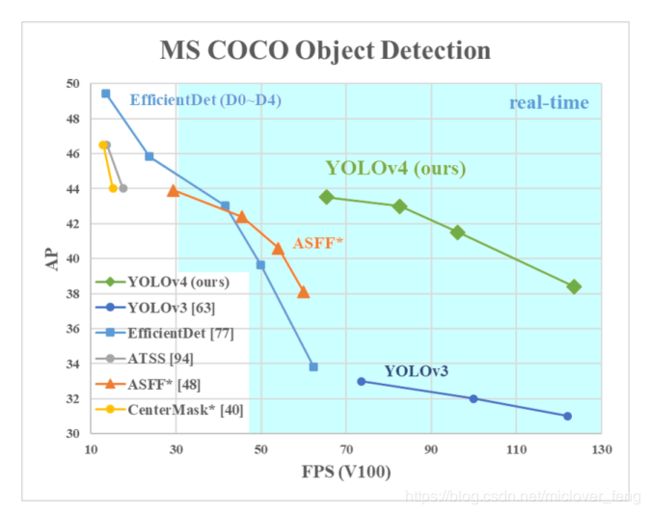
这篇文章的贡献如下:
- 我们设计了一个高效并且强大的目标检测模型。它使每个人都可以使用1080 Ti或2080 TiGPU来训练一个超级快速和精确的目标探测器。
- 我们验证了在检测器训练过程中,最先进的“Bag of freebies(免费包)”和“Bag of specials(特价包)” 的目标检测方法的影响。
- 我们修改了当前最先进的一些方法(包括CBN、PAN、SAM etc.),使其更有效,更适合于单GPU训练。
- 总之,在速度差不多的情况下,精度最好;在精度差不多的情况下,速度最好。
YOLOv4 使用了以下特征组合:
- 加权残差连接(Weighted-Residual-Connections,WRC)
- 跨阶段部分连(Cross-Stage-Partial-connection,CSP)
- 跨小批量标准化(Cross mini-Batch Normalization,CmBN)
- 自对抗训练(Self-adversarial-training,SAT)
- Mish 激活(Mish-activation)
- Mosaic 数据增强
- DropBlock 正则化
- CIoU 损失
2.4.1 目标检测分析
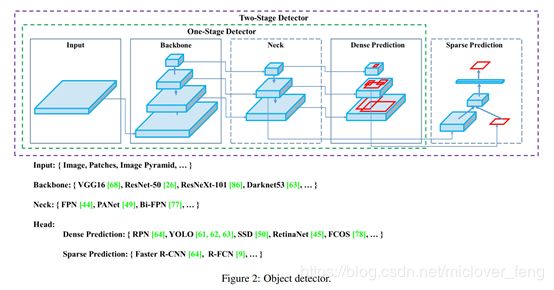
根据上图,对于目标检测器的结构分类如下:
| Input |
Image, Patches, Image Pyramid |
|
| Backbones |
VGG16 [68], ResNet-50 [26], SpineNet[12], EficientNet-B0/B7 [75], CSPResNeXt50 [81],CSPDarknet53 [81] |
|
| Neck |
Additional blocks |
SPP [25], ASPP [5], RFB[47], SAM [85] |
| Path-aggregation blocks |
FPN [44], PAN [49],NAS-FPN [17],Fully-connected FPN, BiFPN[77], ASFF [48], SFAM [98] |
|
| Heads |
Dense Prediction (one-stage) |
RPN [64], SSD [50], YOLO [61], RetinaNet[45] (anchor based),CornerNet [37], CenterNet [13], MatrixNet[60], FCOS [78] (anchor free) |
| Sparse Prediction (two-stage) |
Faster R-CNN [64], R-FCN [9], Mask R-CNN [23] (anchor based),RepPoints [87] (anchor free) |
|
2.4.2 调优手段
作者把所有的调优手段分为了两大类“Bag of freebies(免费礼包)”和“Bag of specials(特价包)”
免费包(Bag of freebies,BOF)
是指在离线训练阶段为了提升精度而广泛使用的调优手段,而这种技巧并不在预测中使用,不会增加预测时间。即:只是改变训练策略或者增加训练代价的方法。
| 数据类 |
数据增强:random erase/CutOut/hide-and-seek/grid mask/MixUp/CutMix/GAN |
| 数据分布:two-stage的有example mining,one-stage的有focal loss |
|
| 特征图类 |
DropOut/DropConnect/DropBlock |
| 边界框回归损失 |
MSE/ IoU loss/l1、l2 loss/GIoU loss/DIoU loss/CIoU loss |
特价包(Bag of Specials,BOS)
对于那些仅增加少量推理成本,却能显著提高目标检测精度的插件模块和后处理方法,称之为“特价包”。插件模块是为了提高模型中的某一属性,扩大感受野、引入注意力机制、增强特征集成能力和激活函数;后处理是为了筛选模型预测结果。
| 插件模块 |
增大感受野 |
SPP/ASPP/RFB |
| 注意力 |
Squeeze-and-Excitation (SE)/Spa-tial Attention Module (SAM) |
|
| 特征集成 |
SFAM/ASFF/BiFPN |
|
| 激活函数 |
ReLu/LReLU/PReLU/ReLU6/Scaled ExponentialLinear Unit (SELU)/Swish/hard-Swish/Mish |
|
| 后处理类 |
soft NMS/DIoU NMS |
|
2.4.3 YOLO V4 方法
| Backbone: |
CSPDarknet53 |
| Neck: |
SPP[25], PAN |
| Head: |
YOLOv3 |
具体而言,YOLO v4 使用了:
- 用于骨干网络的BoF:CutMix 和 Mosaic 数据增强、DropBlock 正则化和类标签平滑;
- 用于骨干网络的BoS:Mish 激活、CSP 和多输入加权残差连接(MiWRC);
- 用于检测器的BoF:CIoU-loss、CmBN、DropBlock 正则化、Mosaic 数据增强、自对抗训练、消除网格敏感性(Eliminate grid sensitivity)、针对一个真值使用多个锚、余弦退火调度器、优化超参数和随机训练形状;
- 用于检测器的BoS:Mish 激活、SPP 块、SAM 块、PAN 路径聚合块和 DIoU-NMS。
架构选择

作者选择架构主要考虑几方面的平衡:输入网络分辨率/卷积层数量/参数数量/输出维度。
一个模型的分类效果好不见得其检测效果就好,想要检测效果好需要以下几点:
- 更大的网络输入分辨率——用于检测小目标——作者使用:CSPDarknet53
- 更深的网络层——能够覆盖更大面积的感受野——作者使用:SPP-block
- 更多的参数——更好的检测同一图像内不同size的目标——作者使用:PANet
最终YOLOv4的架构:
- backbone:CSPResNext50
- additional block:SPP-block
- path-aggregation neck:PANet
- heads:YOLOv3的heads
BoF(免费礼包)和BoS(特价包)的选择
- 对于训练激活函数,由于PReLU和SELU更难训练,而ReLU6是专门为量化网络设计的,因此将上述其余激活函数从候选列表中删除。
- 在regularization方法上,发表Drop-Block的人将其方法与其他方法进行了详细的比较,其regularization方法取得了很大的成果。因此,作者毫不犹豫地选择DropBlock作为regularization方法。
- 在归一化方法的选择上,由于关注的是只使用一个GPU的训练策略,所以没有考虑syncBN。
其他改进
为了使设计的检测器更适合于单GPU上的训练,作者做了如下的附加设计和改进:
- 介绍了一种新的数据增强Mosaic法和Self-AdversarialTraining自对抗训练法。
- 应用遗传算法选择最优超参数。
- 改进SAM,改进PAN,和跨小批量标准化(CmBN),使我们的设计适合于有效的训练和检测
2.4.4 算法中用到的方法
马赛克数据增强(Mosaic data augmentation)

作者是基于CutMix做的改进,将4张训练图片混合成一张的新数据增强方法,这样可以丰富图像的上下文信息。标签是根据所占面积大小给与. 这种做法的好处是允许检测上下文之外的目标,增强模型的鲁棒性。此外,在每一层从4个不同的图像批处理标准化计算激活统计,这大大减少了对大mini-batch处理size的需求。

自对抗训练(Self-Adversarial Training,SAT)

这是一种新的数据扩充技术,该技术分前后两个阶段进行。
- 在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自身执行一种对抗性攻击,改变原始图像,从而造成图像上没有目标的假象。
- 在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
DropBlock 正则化(DropBlock regularization)
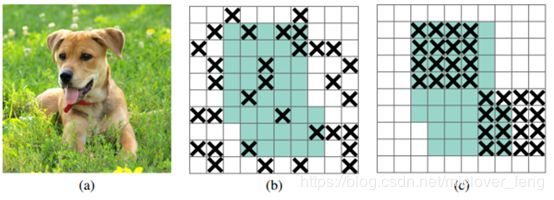
- 像图b,网络还会从drouout掉的激活单元附近学习到同样的信息。
- 图c,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗的别的部位的特征,来实现正确分类,从而表现出更好的泛化。
类标签平滑(Class label smoothing)
[0, 0, 1] —> [0.01, 0.01, 0.98]
[…]·(1-a) + a/n·[1,1…,1]
Eg:a = 0.03 class num = 3,
[0,0,1]*(1-0.03) + 0.03 / 3 *[1,1,1] = [0.01,0.01,0.98]
CIoU 损失(CIoU-loss)
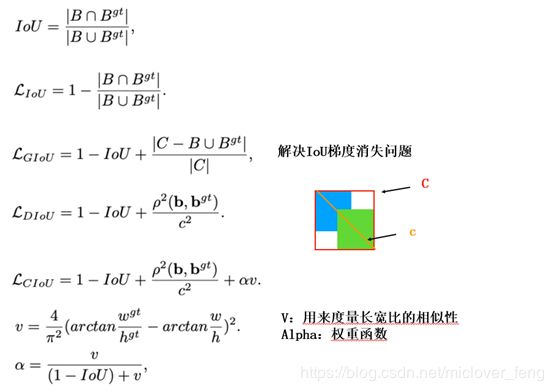
DIoU-NMS

跨小批量标准化(Cross mini-Batch Normalization,CmBN)
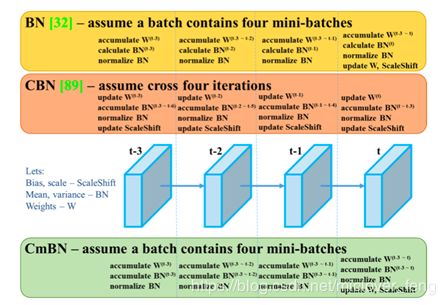
1、Batch Normalization
BN我们都知道他主要由四个参数:均值,方差,和两个重构参数γ、β。在每一次的前向传播中,他会收集mini-batch的均值和方差,通过均值和方差去学习γ和β,从而重构一个原始网络的分布,保证后层数据输入的一直性。一般情况下使用BN,可以增加学习率,进而使训练的速度得到提升等优点[1]。
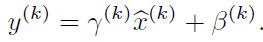


2、Cross-Iteration Batch Normalization
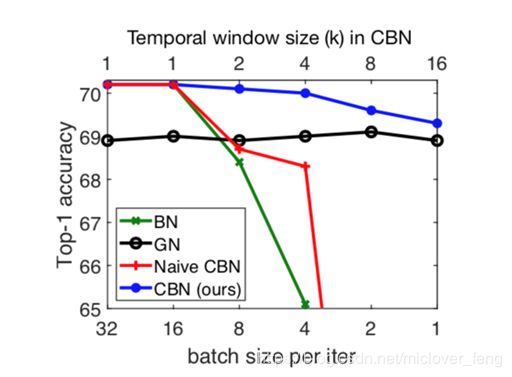
CBN是去估计几个连续batch的统计参数。
1.背景
还是为了解决BN在小batchsize时效果不好的问题
2.CBN
(1)作者认为连续几次训练iteration中模型参数的变化是平滑的
(2)作者将前几次iteration的BN参数保存起来,当前iteration的BN参数由当前batch数据求出的BN参数和保存的前几次的BN参数共同推算得出(顾名思义 Cross-Interation BN)
(3)训练前期BN参数记忆长度短一些,后期训练稳定了可以保存更长时间的BN参数来参与推算,效果更好
3.我个人的理解:
可以将CBN粗糙地总结为 “前几次训练的BN(LN/GN应该都可以)参数” + 当前batch数据计算的BN(LN/GN)参数 来计算得出当前次训练iteration真正的CBN参数。
3、Cross mini-Batch Normalization,CmBN
最终论文中结合了BN和CBN方法。它只收集单个批次中的小批次之间的统计信息。这样做的好处是可以在batch size比较小的情况下维持精度在一个合理的范围下。同时这样做也是为了论文中提到的适合单卡GPU训练。
网格消除敏感(Eliminate grid sensitivity)
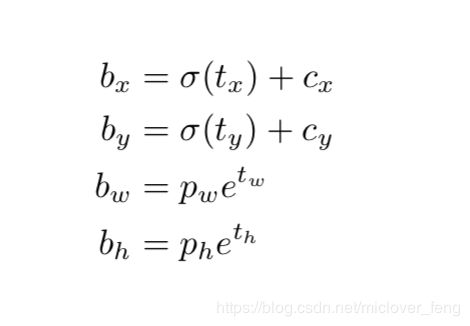
通过将sigmoid乘以一个超过1.0的因子来解决这个问题
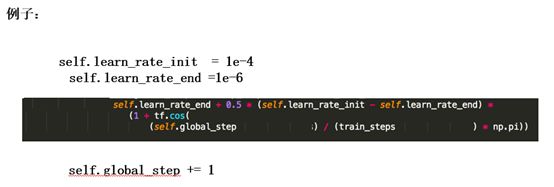
模拟余弦退火(Cosine annealing scheduler)
这是针对学习率的。
Mish激活(Mish activation)
|
Mish=x * tanh(ln(1+e^x)) |
理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。

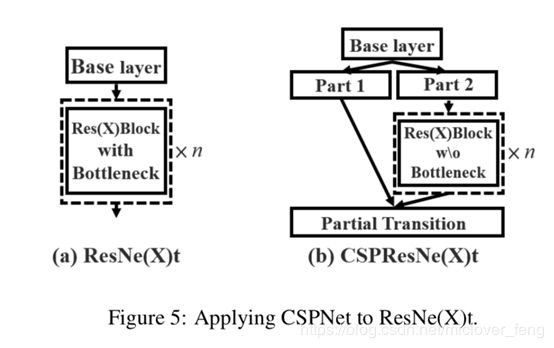
跨阶段部分连接(Cross-Stage-Partial-connection,CSP)
CSPNet可以大大减少计算量,提高推理速度和准确性
一部分经过密集块和过渡层,另一部分与传输的特征映射结合到下一阶段
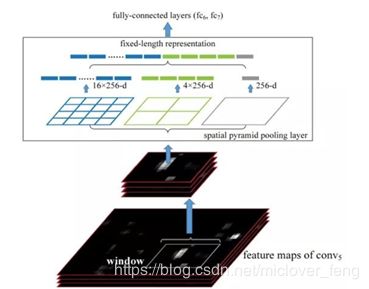
空间金字塔池化(Spatial Pyramid Pooling,SPP)
不管输入尺寸是怎样,SPP层 可以产生固定大小的输出 ,用于多尺度训练
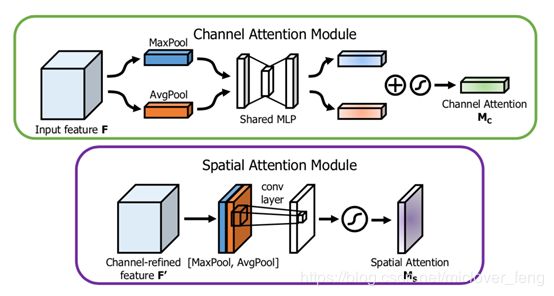
Spatial Attention Module,SAM
作者基于原先的SAM进行了改进。
原先的:不仅在通道上加上了SE注意力机制,在空间上也加入了SE注意力机制
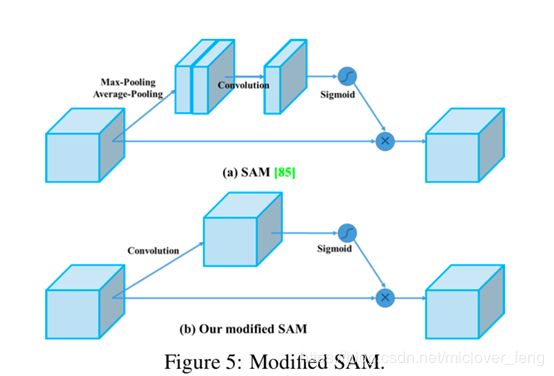
图b作者修改后的,SE结构变成了先进行卷积,在进行sigmoid,然后和原始的特征进行点点相乘。从空间注意力机制(spatial-wise attention)修改为点注意力机制(point-wise attention)
路径聚合网络(Path Aggregation Network,PAN)
PAN基于FPN和Mask RCNN模型之上提出了三点创新:
1、PANet改进了主干网络结构,加强了特征金字塔的结构,缩短了高低层特征融合的路径
2、提出了更灵活的RoI池化。之前FPN的RoI池化只从高层特征取值,现在则在各个尺度上的特征里操作;
3、预测mask的时候使用一个额外的fc支路来辅助全卷积分割支路的结果。
PANet在COCO 17实例分割竞赛中取得了第一名的成绩,在检测任务中取得了第二的成绩。
下图展示PANet的细节:
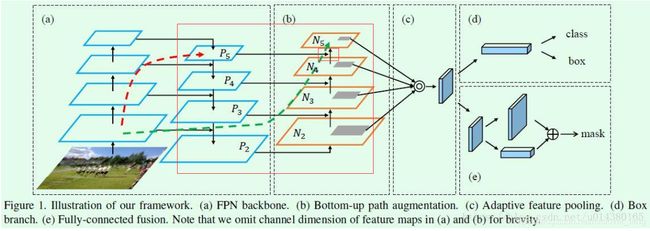
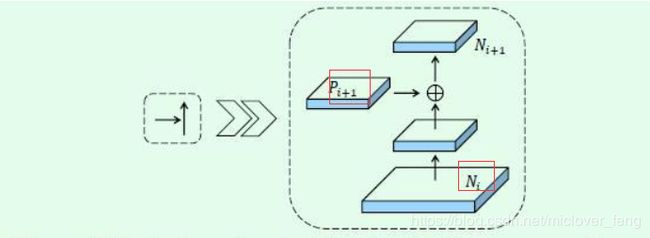
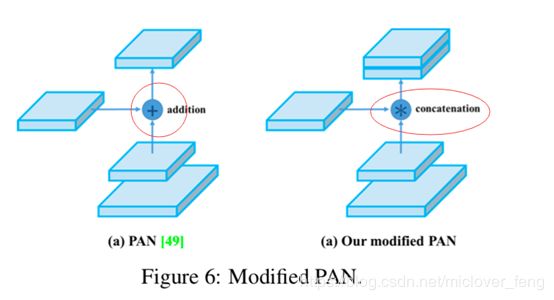
由原来的addition对其修改为级联(concatenation)
TODO.....