Linux内核分析——x86汇编基础
pianogirl 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、计算机是如何工作的
我们平时使用的计算机属于“冯·诺依曼结构”,将程序和数据一起存储在内存中,CPU从内存中不断地取指令并执行指令。除此以外还有“哈佛结构”。
CPU能够执行的指令是二进制指令,为便于理解,人们发明了汇编指令,是对机器指令的简单翻译,增强了可读性。编程语言多属于高级语言,有良好的可读性,却不能被计算机直接执行,因此,高级语言通常都要经过编译或解释说明等过程,转换为计算机能够执行的机器语言。
下面以一个简单的C程序为例,分析计算机如何执行指令。
C程序代码如下,将其命名为main.c
int g(int x)
{
return x + 2;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(12) + 1;
}
然后执行一条命令生成对应的汇编代码:
gcc -S -o 5112.s main.c -m32
注意,Linux 采用的是 AT&T 汇编格式,它与 Intel 汇编格式略有不同。
g:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
addl $2, %eax
popl %ebp
ret
f:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl 8(%ebp), %eax
movl %eax, (%esp)
call g
leave
ret
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $12, (%esp)
call f
addl $1, %eax
leave
ret

二、汇编代码分析
整个程序过程中堆栈以及寄存器的变化如下图:(方便起见,内存编号做了改动)





















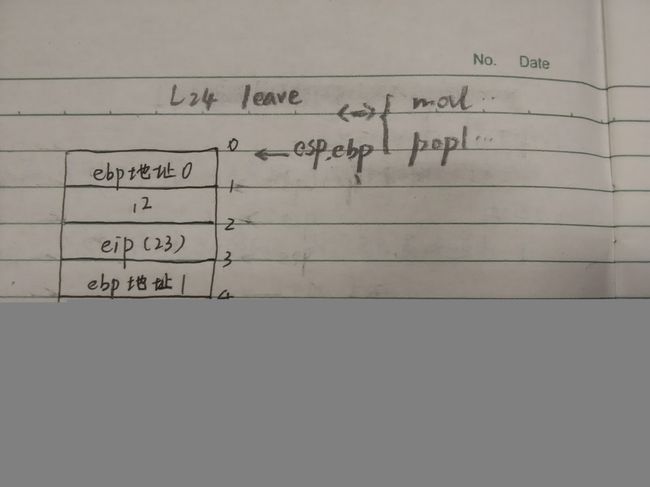

三、思考与总结
1、eip是控制整个程序运行过程的决定因素。
计算机从 eip 指向的地址取出一条指令执行,其情况无外乎三种:
(1、若遇到跳转语句(JMP 等)时,先将 eip 压栈保存,即当前指令的下一条指令的地址,然后将需要跳转的目的地址赋给 eip,实现跳转;
(2、若遇到函数调用call时,除了将 eip 压栈,还要保存当前堆栈的状态,将栈基指针 ebp 压栈,然后将相应函数地址赋给 eip,实现跳转;
(3、若为普通指令,则继续从 eip 指向的地址取出下一条指令执行。
从堆栈分析图中可以看到,该程序的两次函数call调用中,总是先将当前eip值保存在堆栈中,紧接着将栈基指针 ebp 压栈保存,处理好以上两个工作后,才进入新的函数。
2、ebp的移动使得指令执行过程更加层次清晰。
曾经认为堆栈的运动只有栈顶指针在参与,栈底指针无须移动。
然而从这个两次函数调用的例子可以发现,ebp总是保存当前“子堆栈”(我姑且这么称呼)的栈底位置,它和栈顶指针esp一起构成了当前函数用到的“子堆栈”。
进入另一个函数之前,总是保存当前栈的基地址,开始一个新的栈,使每个函数有独立的栈空间,当函数返回时,能恢复到之前函数的栈空间。
从图上可以看到,“ebp地址xxxx”将整个堆栈数据划分为3个区域,分别对应3段函数,结构清晰,层次鲜明,使人不得不佩服机器处理数据的严谨与清晰。
3、总结。
汇编可以用一句话概括:汇编就是在(寄存器和寄存器)或 (寄存器和内存)之间来回move 数据。就是指:数据在内存和寄存器间来回流动,流动的越频繁就代表程序越复杂。
4、其他问题——需要确认的几个问题
(1、同时运行的几个程序,每一个都能在内存中分配到一段堆栈,不会冲突?——保护机制?
(2、5112.s中只把enter指令拆解,不把leave指令拆解——与编译器有关?
(3、32位计算机,pushl指令中,要先做subl $4, %esp。为什么是4?是因为32/8 =4吗?32位计算机里,内存0x000007F(举个例子)指的是几个字节的内容?
(4、从图中可以看到,压栈的是参数,而不是常数。C中的全局变量、形参、实参,究竟在堆栈中怎么体现的?
参考资料:http://blog.csdn.net/liutianshx2012/article/details/50730780 码着,有时间看看。