实战Intel MKL(Math Kernel Library)
MKL官网所有文档:https://software.intel.com/en-us/articles/intel-math-kernel-library-documentation/
MKL使用详细手册:https://software.intel.com/sites/default/files/mkl-2019-developer-reference-c_0.pdf
MKL中文入门博客:https://blog.csdn.net/zb1165048017/article/category/6857730
LAPACK学习文档:https://software.intel.com/sites/products/documentation/doclib/mkl_sa/11/mkl_lapack_examples/index.htm
查找LAPACK函数工具:https://software.intel.com/en-us/articles/intel-mkl-function-finding-advisor
查找链接库工具:https://software.intel.com/en-us/articles/intel-mkl-link-line-advisor/
intel c++ compiler与GNU c++ compiler对MKL的比较
GNU c++ compiler = gcc,gcc -o dgemm_with_timing_gcc dgemm_with_timing.c -lmkl_rt
intel c++ compiler = icc,icc -o dgemm_with_timing_icc dgemm_with_timing.c -mkl
LOOP_COUNT=220,最终结果是4.50294 vs 4.50688 ms,所以姑且认为编译器对MKL并没有多大的影响。
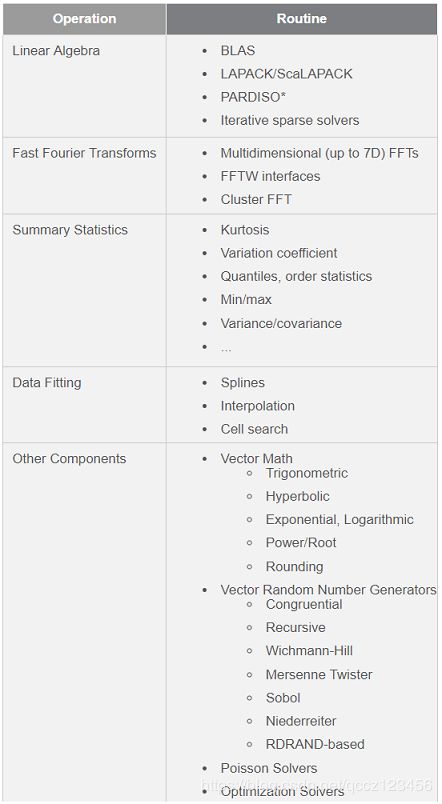
安装
在intel官网注册并下载mkl:https://software.intel.com/en-us/mkl
Linux下安装:
mklvars.sh说明: https://software.intel.com/en-us/mkl-linux-developer-guide-scripts-to-set-environment-variables
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/14895/l_mkl_2019.1.144.tgz
tar -zxvf l_mkl_2019.1.144.tgz
cd l_mkl_2019.1.144/
./install.sh
sudo vim /etc/ld.so.conf.d/intel-mkl.conf
/path/intel/mkl/lib/intel64
/path/intel/lib/intel64
sudo ldconfig
cd /path/intel/mkl/bin
source mklvars.sh intel64
vim dgemm_example.c # input your code
gcc -o run_dgemm_example dgemm_example.c -lmkl_rt
实例
第一次入门教程:https://software.intel.com/en-us/mkl-tutorial-c-overview
mkl_malloc(), mkl_free(),
cblas_dgemm(), dsecnd(),
mkl_get_max_threads(), mkl_set_num_threads()
所有实例:https://software.intel.com/en-us/product-code-samples
wget https://software.intel.com/sites/default/files/ipsxe2019_samples_lin_20180731.tgz
mkdir ipsxe2019_samples_lin_20180731
tar -zxvf ipsxe2019_samples_lin_20180731.tgz -C ipsxe2019_samples_lin_20180731
(1)源码:dgemm_example.c
介绍mkl_malloc(), mkl_free(), cblas_dgemm()的用法。
#include 运行结果如下:
$ ./run_dgemm_example
This example computes real matrix C=alpha*A*B+beta*C using
Intel(R) MKL function dgemm, where A, B, and C are matrices and
alpha and beta are double precision scalars
Initializing data for matrix multiplication C=A*B for matrix
A(2000x200) and matrix B(200x1000)
Allocating memory for matrices aligned on 64-byte boundary for better
performance
Intializing matrix data
Computing matrix product using Intel(R) MKL dgemm function via CBLAS interface
Computations completed.
Top left corner of matrix A:
1 2 3 4 5 6
201 202 203 204 205 206
401 402 403 404 405 406
601 602 603 604 605 606
801 802 803 804 805 806
1001 1002 1003 1004 1005 1006
Top left corner of matrix B:
-1 -2 -3 -4 -5 -6
-1001 -1002 -1003 -1004 -1005 -1006
-2001 -2002 -2003 -2004 -2005 -2006
-3001 -3002 -3003 -3004 -3005 -3006
-4001 -4002 -4003 -4004 -4005 -4006
-5001 -5002 -5003 -5004 -5005 -5006
Top left corner of matrix C:
-2.6666E+09 -2.6666E+09 -2.6667E+09 -2.6667E+09 -2.6667E+09 -2.6667E+09
-6.6467E+09 -6.6467E+09 -6.6468E+09 -6.6468E+09 -6.6469E+09 -6.647E+09
-1.0627E+10 -1.0627E+10 -1.0627E+10 -1.0627E+10 -1.0627E+10 -1.0627E+10
-1.4607E+10 -1.4607E+10 -1.4607E+10 -1.4607E+10 -1.4607E+10 -1.4607E+10
-1.8587E+10 -1.8587E+10 -1.8587E+10 -1.8587E+10 -1.8588E+10 -1.8588E+10
-2.2567E+10 -2.2567E+10 -2.2567E+10 -2.2567E+10 -2.2568E+10 -2.2568E+10
Deallocating memory
Example completed.
(2)源码:dgemm_with_timing.c
介绍dsecnd()用于统计性能情况。
#include 运行结果如下:
$ ./run_dgemm_with_timing
This example measures performance of Intel(R) MKL function dgemm
computing real matrix C=alpha*A*B+beta*C, where A, B, and C
are matrices and alpha and beta are double precision scalars
Initializing data for matrix multiplication C=A*B for matrix
A(2000x200) and matrix B(200x1000)
Allocating memory for matrices aligned on 64-byte boundary for better
performance
Intializing matrix data
Making the first run of matrix product using Intel(R) MKL dgemm function
via CBLAS interface to get stable run time measurements
Measuring performance of matrix product using Intel(R) MKL dgemm function
via CBLAS interface
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.53907 milliseconds ==
Deallocating memory
It is highly recommended to define LOOP_COUNT for this example on your
computer as 221 to have total execution time about 1 second for reliability
of measurements
Example completed.
(3)源码:matrix_multiplication.c
用于比较普通CPU计算和MKL的性能差距。
#define min(x,y) (((x) < (y)) ? (x) : (y))
#include 运行结果如下:
$ ./run_matrix_multiplication
This example measures performance of rcomputing the real matrix product
C=alpha*A*B+beta*C using a triple nested loop, where A, B, and C are
matrices and alpha and beta are double precision scalars
Initializing data for matrix multiplication C=A*B for matrix
A(2000x200) and matrix B(200x1000)
Allocating memory for matrices aligned on 64-byte boundary for better
performance
Intializing matrix data
Making the first run of matrix product using triple nested loop
to get stable run time measurements
Measuring performance of matrix product using triple nested loop
== Matrix multiplication using triple nested loop completed ==
== at 1408.21425 milliseconds ==
Deallocating memory
Example completed.
(4)源码:dgemm_threading_effect_example.c
用于设置MKL运行的线程数,mkl_set_num_threads()。
#include 运行结果如下,当mkl_get_max_threads等于physical cores数时,性能是最佳的,并不是线程数,也就是如下的4,而不是8:
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 94
Model name: Intel(R) Core(TM) i7-6770HQ CPU @ 2.60GHz
Stepping: 3
CPU MHz: 1100.549
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 5184.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 6144K
NUMA node0 CPU(s): 0-7
$ ./run_dgemm_threading_effect_example
This example demonstrates threading impact on computing real matrix product
C=alpha*A*B+beta*C using Intel(R) MKL function dgemm, where A, B, and C are
matrices and alpha and beta are double precision scalars
Initializing data for matrix multiplication C=A*B for matrix
A(2000x200) and matrix B(200x1000)
Allocating memory for matrices aligned on 64-byte boundary for better
performance
Intializing matrix data
Finding max number 4 of threads Intel(R) MKL can use for parallel runs
Running Intel(R) MKL from 1 to 8 threads
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 15.47987 milliseconds using 1 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 8.00033 milliseconds using 2 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 5.51243 milliseconds using 3 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.68829 milliseconds using 4 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.82797 milliseconds using 5 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.83322 milliseconds using 6 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.98721 milliseconds using 7 thread(s) ==
== Matrix multiplication using Intel(R) MKL dgemm completed ==
== at 4.76135 milliseconds using 8 thread(s) ==
Deallocating memory
Example completed.