Keras 自编码器AutoEncoder(五)
一、什么是自编码器(Autoencoder)
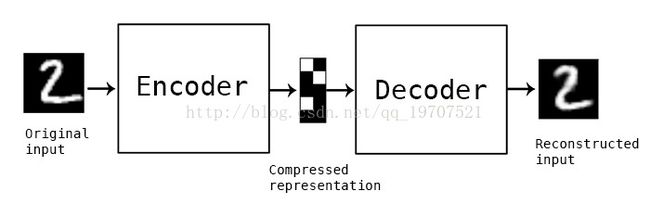
“自编码”是一种数据压缩算法,其中压缩和解压缩功能是1)数据特定的,2)有损的,3)从例子中自动学习而不是由人工设计。此外,在几乎所有使用术语“自动编码器”的情况下,压缩和解压缩功能都是用神经网络来实现的。
1)自动编码器是特定于数据的,这意味着它们只能压缩类似于他们所训练的数据。这与例如MPEG-2音频层III(MP3)压缩算法不同,后者通常只保留关于“声音”的假设,而不涉及特定类型的声音。在面部图片上训练的自动编码器在压缩树的图片方面做得相当差,因为它将学习的特征是面部特定的。
2)自动编码器是有损的,这意味着与原始输入相比,解压缩的输出会降低(类似于MP3或JPEG压缩)。这与无损算术压缩不同。
3)自动编码器是从数据实例中自动学习的,这是一个有用的属性:这意味着很容易培养算法的特定实例,在特定类型的输入上运行良好。它不需要任何新的工程,只需要适当的培训数据。
要构建一个自动编码器,需要三件事情:编码函数,解码函数和数据压缩表示与解压缩表示(即“丢失”函数)之间的信息损失量之间的距离函数。编码器和解码器将被选择为参数函数(通常是神经网络),并且相对于距离函数是可微分的,因此可以优化编码/解码函数的参数以最小化重构损失,使用随机梯度下降。这很简单!而且你甚至不需要理解这些词语在实践中开始使用自动编码器。
什么是自动编码器的好处?
二、使用Keras建立简单的自编码器
1. 单隐含层自编码器
建立一个全连接的编码器和解码器。也可以单独使用编码器和解码器,在此使用Keras的函数式模型API即Model可以灵活地构建自编码器。
50个epoch后,看起来我们的自编码器优化的不错了,损失val_loss: 0.1037。
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input, outputs=decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
2. 稀疏自编码器、深层自编码器
为码字加上稀疏性约束。如果我们对隐层单元施加稀疏性约束的话,会得到更为紧凑的表达,只有一小部分神经元会被激活。在Keras中,我们可以通过添加一个activity_regularizer达到对某层激活值进行约束的目的。
encoded = Dense(encoding_dim, activation='relu',activity_regularizer=regularizers.activity_l1(10e-5))(input_img)
把多个自编码器叠起来即加深自编码器的深度,50个epoch后,损失val_loss:0.0926,比1个隐含层的自编码器要好一些。
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Model #泛型模型
from keras.layers import Dense, Input
import matplotlib.pyplot as plt
# X shape (60,000 28x28), y shape (10,000, )
(x_train, _), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.astype('float32') / 255. # minmax_normalized
x_test = x_test.astype('float32') / 255. # minmax_normalized
x_train = x_train.reshape((x_train.shape[0], -1))
x_test = x_test.reshape((x_test.shape[0], -1))
print(x_train.shape)
print(x_test.shape)
# 压缩特征维度至2维
encoding_dim = 2
# this is our input placeholder
input_img = Input(shape=(784,))
# 编码层
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim)(encoded)
# 解码层
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded)
# 构建自编码模型
autoencoder = Model(inputs=input_img, outputs=decoded)
# 构建编码模型
encoder = Model(inputs=input_img, outputs=encoder_output)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.summary()
encoder.summary()
# training
autoencoder.fit(x_train, x_train, epochs=10, batch_size=256, shuffle=True)
# plotting
encoded_imgs = encoder.predict(x_test)
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test,s=3)
plt.colorbar()
plt.show()
decoded_imgs = autoencoder.predict(x_test)
# use Matplotlib (don't ask)
import matplotlib.pyplot as plt
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
3. 卷积自编码器:用卷积层构建自编码器
当输入是图像时,使用卷积神经网络是更好的。卷积自编码器的编码器部分由卷积层和MaxPooling层构成,MaxPooling负责空域下采样。而解码器由卷积层和上采样层构成。50个epoch后,损失val_loss: 0.1018。
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
decoded_imgs = autoencoder.predict(x_test)
UpSampling2D
上采样,扩大矩阵,可以用于复原图像等。

keras.layers.convolutional.UpSampling2D(size=(2, 2), data_format=None)
将数据的行和列分别重复size[0]和size[1]次
4. 使用自动编码器进行图像去噪
我们把训练样本用噪声污染,然后使解码器解码出干净的照片,以获得去噪自动编码器。首先我们把原图片加入高斯噪声,然后把像素值clip到0~1。
ps:去噪自编码器(denoisingautoencoder, DAE)是一类 接受损坏数据作为输入,并 训练来预测 原始未被损坏数据 作为输出的自编码器。
#去噪 自编码器
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.) #[0.,1.]
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x=Convolution2D(32,(3,3),activation='relu',padding='same')(input_img)
x=MaxPooling2D(pool_size=(2,2),padding='same')(x)
x=Convolution2D(32,(3,3),activation='relu',padding='same')(x)
encoded=MaxPooling2D(pool_size=(2,2),padding='same')(x)
x=Convolution2D(32,(3,3),activation='relu',padding='same')(encoded)
x=UpSampling2D(size=(2,2))(x)
x=Convolution2D(32,(3,3),activation='relu',padding='same')(x)
x=UpSampling2D((2,2))(x)
decoded=Convolution2D(1,(3,3),activation='sigmoid',padding='same')(x)
autoencoder=Model(inputs=input_img,outputs=decoded)
autoencoder.compile(optimizer='adam',loss='binary_crossentropy')
autoencoder.summary()
# 打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train_noisy, x_train, epochs=10, batch_size=256,
shuffle=True, validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='autoencoder', write_graph=False)])
decoded_imgs = autoencoder.predict(x_test_noisy)
plt.figure(figsize=(30,6)) #设置 figure大小
n=10
for i in range(n):
ax=plt.subplot(3,n,i+1) # m表示是图排成m行,n表示图排成n列,p是指你现在要把曲线画到figure中哪个图上
plt.imshow(x_test[i].reshape(28,28))
plt.gray() #只有黑白两色,没有中间的渐进色
ax.get_xaxis().set_visible(False) # X 轴不可见
ax.get_yaxis().set_visible(False) # y 轴不可见
ax=plt.subplot(3,n,i+1+n)
plt.imshow(x_test_noisy[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax=plt.subplot(3,n,i+1+2*n)
plt.imshow(decoded_imgs[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()