AlexNet论文详解
原文地址:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
背景:
2012ILSVRC(Imagenet大规模视觉识别挑战赛)冠军。第一次有模型在lmagenet数据集上出色表现。使用大型深度卷积神经网络,真正展示了CNN优点。Alex 等人将120万个带标签的训练样本在两块 GTX 580 3GB GPU 上训练五六天,并取得了卓越成果,使得深度学习开始在各个领域大显身手,也使得 NVIDIA 显卡和 CUDA 工具逐渐碾压对手。
结构简析:
一个完整的CNN结构是由多个 1)卷积层 2)降采样层 3)激活函数层 4)(局部响应)归一化层 5)全连接层和 6)随机失活层 有序地拼接而成的。(图中flops是每秒浮点运算次数(浮点数先乘后加算一个flop)
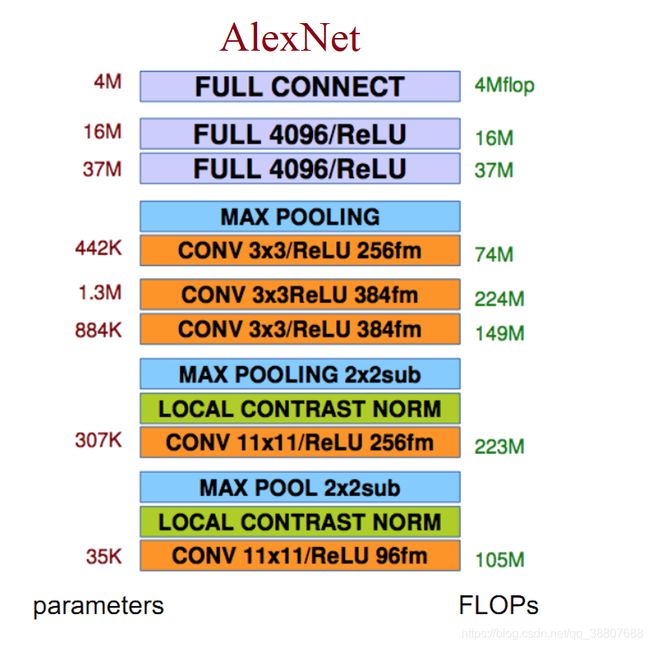
一句话描述AlexNet结构:
5个卷积层加3个全连接层
AlexNet具体结构:
- 输入尺寸:227*227像素(因为竞赛的需要)
- 卷积层:多个(因为输入尺寸的需要)
- 降采样层:多个(因为输入尺寸的需要)
- 归一化层:局部响应归一化
- 输出:1000个类别(因为竞赛的需要)
- Dropout层:随机失活层
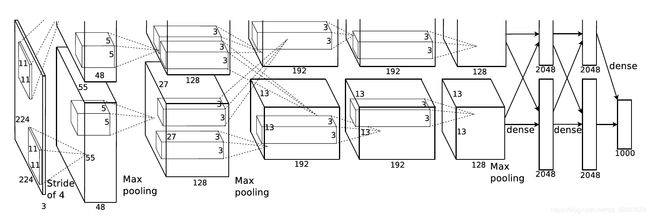
网络模块图总览:
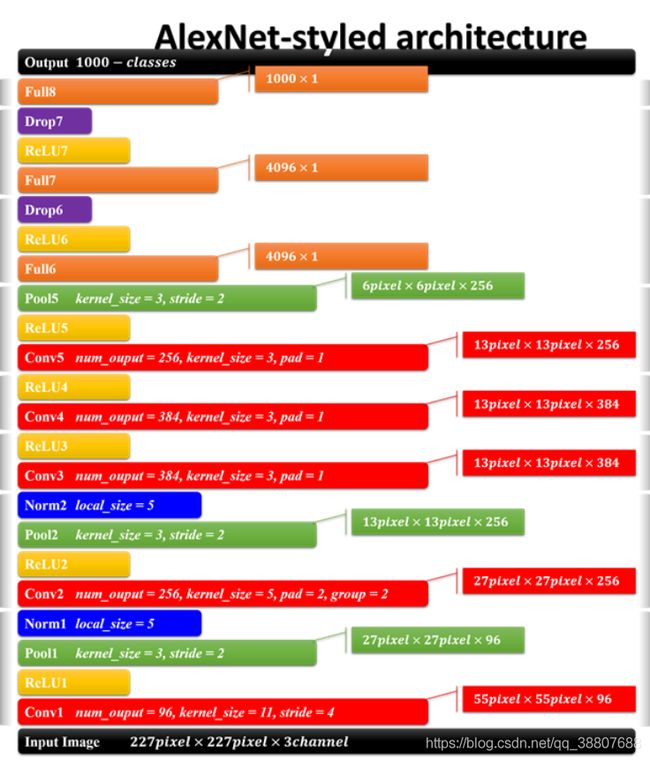
CNN的前面部分,卷积-激活函数-降采样-标准化。这个可以说是一个卷积过程的标配,CNN的结构就是这样,从宏观的角度来看,就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。模块后面部分是全连接层,全连接层就和人工神经网络的结构一样的,结点数多,连接线也多,所以这儿引出了一个dropout层。之后就是一个输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。
预处理过程:
数据处理过程:
1.对于不同尺度大小的图片,我们首先将其resize到256*256,由于全连接层的存在,网络要求输入的图像大小一致。具体实现是先将短边resize到256,然后在中间部分截取256*256作为训练数据。
2.对图像resize结束之后,然后减去RGB三个通道每个像素点在整个训练集的均值。
训练数据处理过程:
对于256*256大小的图像,首先随机截取224*224大小的图像。取镜像(水平翻转),这样可以使原始数据增加(256-224)(256-224)2=2048倍。不然在原来的训练数据上容易过拟合,我们就只能使用更小的网络。
测试图片处理方式:
抽取图像4个角和中心的224*224大小的图像以及其镜像翻转共10张图像利用softmax进行预测,对所有预测取平均作为最终的分类结果。
权重初始化方式:
我们用一个均值为0、标准差为0.01的高斯分布初始化了每一层的权重。我们用常数1初始化了第二、第四和第五个卷积层以及全连接隐层的神经元偏差。该初始化通过提供带正输入的ReLU来加速学习的初级阶段。我们在其余层用常数0初始化神经元偏差。
训练过程:
AlexNet使用了mini-batch SGD,batch的大小为128,梯度下降的算法选择了momentum,参数为0.9,加入了L2正则化,或者说权重衰减,参数为0.0005。论文中提到,这么小的权重衰减参数几乎可以说没有正则化效果,但对模型的学习非常重要。 对于所有层都使用了相等的学习率,这是在整个训练过程中手动调整的。我们遵循的启发式是,当验证误差率在当前学习率下不再降低时,就将学习率除以10。学习率初始化为0.01,在训练结束前共减小3次,。作者训练该网络时大致将这120万张图像的训练集循环了90次,在两个NVIDIA GTX 580 3GB GPU上花了五到六天。
相比前人的进步:
1.AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题。
2.成功将dropout应用于实践。随机dropout一些神经元,以避免过拟合。
3.在以前的CNN中普遍使用平均池化层average pooling, AlexNet全部使用最大池化层 max pooling, 避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。
4.提出LRN层,局部响应归一化,对局部神经元创建了竞争的机制,使得其中响应较大的值变得更大,并抑制反馈较小的。
5.使用了gpu加速神经网络的训练。
6.使用数据增强的方法缓解过拟合现象。
参数模型占GPU显存的一些问题:
几个概念:
1.消费级显卡对单精度计算有优化,服务器级显卡对双精度计算有优化;
2.一般我们使用的变量都是单精度浮点型float32,占4B大小,1B=8bit,8位
3.占显存空间的有输入内容和模型中间变量
参数的显存占用:
只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。有参数的层主要包括:卷积、全连接、batchnorm. 无参数的层:大部分激活层、池化层、droupout层
输入输出内容占用显存:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
节省显存的方法:
1.降低 batch-size;
2.下采样;
3.减少全连接层(一般只留最后一层分类用的全连接层);
总结:
一般卷积层的计算量大,全连接层的参数多。
AlexNet一共有多少个神经元,一共有多少参数?
参数个数:6000 万个(论文网络为准)
C1:2*48×11×11×3(卷积核个数/宽/高/上一层输入厚度) 34848个
C2:2*128×5×5×48(卷积核个数/宽/高/上一层输入厚度) 307200个
C3:2*192×3×3×256(卷积核个数/宽/高/上一层输入厚度) 884736个
C4:2*192×3×3×192(卷积核个数/宽/高/上一层输入厚度) 663552个
C5:2*128×3×3×192(卷积核个数/宽/高/上一层输入厚度) 442368个
R1:4096×6×6×256(卷积核个数/宽/高/上一层输入厚度) 37748736个
R2:4096×4096 16777216个
R3:4096×1000 4096000个
神经元个数:(论文网络为准)

Droupout为什么主要用在全连接层?
属于正则化技术中的一种,dropout的作用是增加网络的泛化能力,可以用在卷积层和全连接层。但是在卷积层一般不用dropout, dropout是用来防止过拟合的过多参数才会容易过拟合,卷积层参数本来就没有全连接层参数多,所以卷积层没必要, 但是是可以用的,要小心翼翼。
为什么选择了relu激活函数?
一般神经元的激活函数会选择sigmoid函数或者tanh函数,然而Alex发现在训练时间的梯度衰减方面,这些非线性饱和函数要比非线性非饱和函数慢很多。在AlexNet中用的非线性非饱和函数是f=max(0,x),即ReLU。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
双GPU运行的一点思考:
受限于GPU技术,但又想提高运行速度和提高网络运行规模,作者采用双GPU的设计模式。并且规定GPU只能在特定的层进行通信交流。作者的原意应该是想利用双GPU分担一半 的计算量,事实上也做到了,但是这里的两个子网络合并起来并不能等价于一个大网络,除非每层都有作者所谓的交互。作者的实验数据表示,two-GPU方案会比只用one-GPU跑半个上面大小网络的方案,在准确度上提高了1.7%的top-1和1.2%的top-5。当然,one-GPU的半个网络和two-GPU网络结构是不一样的,two-GPU有指标上的提升也并不奇怪。
局部响应归一化( LRN)是什么,有用吗?
LRP的由来:
神经生物学中的侧抑制概念,指被激活的神经元会抑制其周围的神经元,所以LRP想实现对神经元的局部抑制。
LPR作用原理:
建立局部竞争机制,使局部较大值得到较大的响应,至于局部的范围是多大,可以通过超参数n进行选择相邻的核,定义想要的局部大小。这种归一化操作实现了某种形式的横向抑制。
这么分析有它的道理,但是后面VGG又说没有作用?没找到合理的解释先用玄学解释。(GoogleNet就使用了LRN)(受启发与某一领域,从理论层面也能给出合理的解释,实验结果也有明显效果,但并未给出有力证明。类似于深度学习的可找到全局最优解的证明,直到最近才给出)。
交叠的池化层:
带交叠的Pooling,顾名思义这指Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用 带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用(获得了更多的感受野之间依赖关系的信息,提升了特征的丰富性)。
但也有最直接的缺点:
1.增加了计算量
2.丰富特征的同时无可避免也带来了部分特征信息的冗余。
该文章中使用到的数据增强的方法:
1.AlexNet用到的第一种数据增益的方法:是原图片大小为256*256中随机的提取224*224的图片,以及他们水平方向的映像。
2.第二种数据增益的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到的方法为PCA。(感觉这里不是很重点,具体可以参看原文)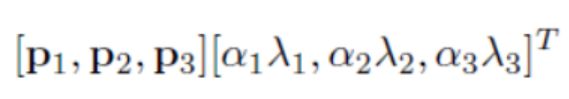
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。
用了什么优化器?
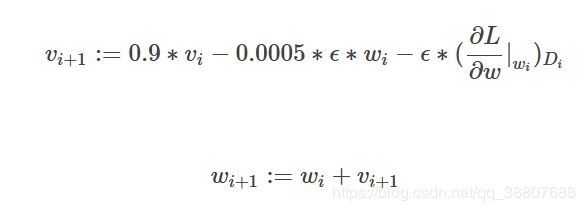
AlexNet训练采用的是SGD,每批图像大小为128,动力为0.9(SGD+momentum(0.9), weight decay)。权重衰减为0.0005(我的理解是其实就是正则化减小权值,稍许减小权重以达防止过拟合的目的)。
开始一直想不明白第三项为什么不乘0.1,最后想0.1应该算在了学习率中。
欢迎批评指正,讨论学习~
最近在github放了两份分类的代码,分别是用Tensorflow和Pytorch实现的,主要用于深度学习入门,学习Tensorflow和Pytorch搭建网络基本的操作。打算将各网络实现一下放入这两份代码中,有兴趣可以看一看,期待和大家一起维护更新。
代码地址:
Tensorflow实现分类网络
Pytorch实现分类网络