在Ubuntu18.04系统中配置完全分布式Hadoop集群
前言:我自己比较喜欢使用Ubuntu,因此就使用它来配置Hadoop集群。我用VMware创建了三个虚拟机将其作为Hadoop的三个节点。因为我自己在看博客的时候,踩了很多坑,有一些博客会有错误的地方,或者说的不够详细,让人不知如何操作,因此我会说的尽量详细。因此可能废话比较多,但绝对保证能正确安装,其实本文也适用于多台公网上的服务器配置集群。
如果在配置好之后启动时出现了问题,可以去Hadoop安装文件夹的logs目录下查看对应的日志文件,在其中找到ERROR行看看是什么原因,能帮助解决问题。
因为Hadoop不同版本的配置有一些不同,因此一定要找对应版本的博客来看,否则可能会出现一些问题。这篇文章中,我使用的版本是Hadoop3.2.0。
在我的安装中参考了一篇Hadoop2的,因为Hadoop2和Hadoop3对Datanode的设置文件不同,还是意外解决的这个问题。
Hadoop2在slaves中指定那些节点作为Datanode,而在Hadoop3中,在workers文件中指定那些节点作为Datanode节点。Hadoop2和Hadoop3在配置时貌似就只有这一个不同。
另外Linux的版本不同,后面在一些配置上也会有一些小的差别,不过基本都是一样的。
有的情况下虚拟机需要完全关闭防火墙才可,我的莫名其妙不需要关闭,可能虚拟机默认设置为关闭
我写完发现官方文档贼好用,网址如下,英文差不多的去看官方文档吧!
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
参考文章和资源网站
0、下面这篇博客必须要看,是讲用scp命令在不同计算机之间拷贝文件的,会用的话后面会很省事
scp 跨机远程拷贝
1、Hadoop下载地址。Hadoop和Java可以在windows下载对应版本安装包后托入虚拟机,也可以使用wget在Ubuntu命令行中下载软件包。如果不能从Windows拖入虚拟机,可以安装VMware Tools工具解决,也可以使用Xtfp5等文件传输软件从Windows传到虚拟机上。还有许多其他各种方法,喜欢就好
http://archive.apache.org/dist/hadoop/core/
如果上面那个速度太慢,用下面这个
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
2、Java下载地址,进去之后注册一下可以下载任意版本的JAVA,最好使用1.8之后的版本。
https://www.oracle.com/java/technologies/javase-downloads.html
3、第一个是知乎的一个专栏,讲的完全正确,但有些简单。看这篇可以理解后面的一些操作。
https://zhuanlan.zhihu.com/p/77938773
4、这个是CSDN上的一篇,比较详细,也基本上正确,就是流程有些乱。
Linux从零搭建Hadoop集群(CentOS7+hadoop 3.2.0+JDK1.8完全分布式集群)
5、这篇对于Hadoop要配置的文件都给出了简单的解释,但是hdfs-site.xml的配置不太对。后面会说这个问题。
https://my.oschina.net/blueyuquan/blog/1811442
6、这篇也挺好的,跟前两篇的差别在于Hadoop配置文件写的稍微有一点差别。就是这篇中提到要配置静态ip地址
https://www.zybuluo.com/DFFuture/note/626899
7、这一篇顶呱呱,主要是主机名和ssh配置那一段写的比较好,简洁易懂
https://blog.csdn.net/wangkai_123456/article/details/87185339
参考上述博客和我自己写的绝对能配置成功,不用再去看其他的博客了,上面的博客缺点在于太不详细,但每一个又有它好的一个地方。因此,我写了这个超级详细 (一堆废话 )的版本
一、集群配置介绍
在我的配置当中把Hadoop1作为主节点,其他两个节点作为从节点。总体配置如下,也就是说如果集群配置成功,打开集群后,在三个计算机上与逆行jps命令,应该会在不同的机器上显示相应的进程,如果没有显示,说明配置有问题。当然可以采用各种各种各样的配置,只要开心就好
| 主机名 | IP地址 | 配置到该主机的进程 |
|---|---|---|
| hadoop1 | 192.168.152.130 | ResourceManager, DataNode, NodeManager, NameNode,SencodaryNameNode |
| hadoop2 | 192.168.152.128 | DataNode, NodeManager |
| hadoop3 | 192.168.152.131 | DataNode, NodeManager |
二、将服务器主机名与ip地址一一对应(映射)
如果喜欢在后续步骤一直用ip地址而不用主机名的话,也可以掠过这一步,因为这一步就是为了用主机名代替ip地址省些事
主机名不是用户名,主机名是指某局域网内主机的名字,用户名是进Linux时的那个登录名。
如下图,在linux的命令行中,@前面的csbo是用户名,@后面的hadoop1是主机名。
![]()
用hostname命令查看虚拟机的主机名,如下
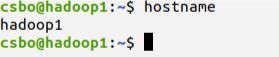
这一步我们要做的是给每一个虚拟机一个确定的主机名,并将它们与各自的ip地址一一对应。默认主机名是ubuntu,三台虚拟机都一样,因此需要修改。主机名可以随意命名,只要三台虚拟机的不同就行。但为了方便好记,我将三个虚拟机的主机名分别修改为hadoop1、hadoop2、hadoop3。
**后面的所有操作都是指我自己的主机名,你在配置时可以取任何喜欢的主机名并使用 **
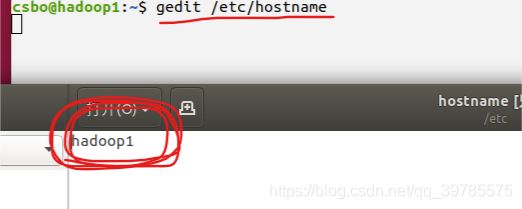
通过修改/etc/hostname文件来修改主机名。用gedit打开该文件后,里面就一个名字,改掉并保存就行了(有vim的话也可以用vim)。命令是:gedit /etc/hostname.
配置好主机名之后一定要将虚拟机的ip改为静态ip或者做ip绑定,让每一台服务器都有确定不变的的ip。大多数博客没有提到这一点,但是这一点很重要。不然后面虚拟机ip地址一变集群就运行不成了,配置静态ip跟系统的版本,VMware的设置(NAT还是桥接)都有关,因此不写了,网上一大堆博客,总能找到一个可以配置成功的。如果可以接收虚拟机不能访问外网,只在虚拟机局域网内部互相通信,那几乎每篇博客的方法都可以做到
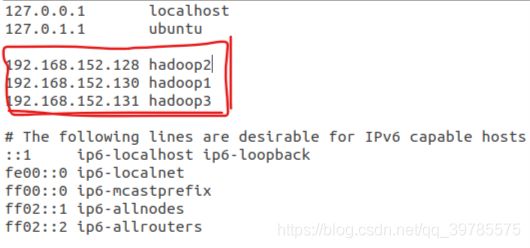
更改完主机名之后,通过修改/etc/hosts文件来将主机名与ip地址一一映射,每一个虚拟机都要修改这个文件,并且内容一样,之所以这样做是要让每一个服务器都知道其他服务器的名字和ip地址。在/etc/hosts文件中加入三个”ip地址 主机名“对。主机名对应的ip地址就是它所在的虚拟机的ip地址,用ifconfig命令可以得到。用gedit /etc/hosts打开该文件并修改文件。
![]()
在打开的文件中加入类似下面三行内容(ip和主机名都是你自己的):
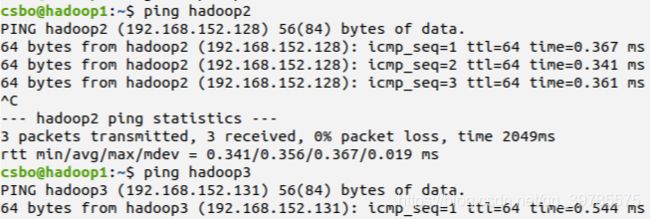
到此为至,这一步完成了。用ping命令试一下主机名和ip地址的映射是否成功,在某一台机器上ping另外两台机器的主机名,ping通说明配置成功。如下:
三、配置SSH,使主机之间互相可以通过SSH免密码访问
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的SSH是无密码登陆的。
以下两步操作在每一个虚拟机上都要做,这里以在hadoop1为例操作
- 通过
ssh-keygen -t rsa命令在hadoop1上生成一对公私密钥,输入命令之后一路回车直到结束。图片中划红线的即为密钥的保存地址。也即如果生成密钥时一直点回车按默认配置,那么然后在当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)。

- 用
ssh-copy-id命令向其他服务器分发公钥,下面分别向hadoop1(自己发给自己)、hadoop2、hadoop3分发公钥。



然后在hadoop2和hadoop3上面做同样的操作即可。上述操作在所有生成和分发密钥的方法当中似乎时最简单的?
然后测试SSH配置是否成功,在hadoop1上用SSH hadoop2或者SSH hadoop3可以免密登录到hadoop2或者hadoop3这两台虚拟机上,并对这两台虚拟机进行操作。说明SSH配置成功。如下:在hadoop1上登陆到了hadoop3,在hadoop1上对hadoop3做的任何操作和在hadoop3上做的操作完全一样。通过exit命令退出回到hadoop1。这三台服务器之间可以同国ssh任意的互相操作。

上面这步完成之后可能有的虚拟机需要关闭防火墙,如果是云服务器,那一定是要设置好对应的安全组规则。
四、安装Java、Hadooop-3.2.0并配置环境变量
JAVA和Hadoop的下载链接已经在上面给出了,可以使用上面的任何一种方法把安装包弄到虚拟机上。在每一台虚拟机都要安装JAVA和Hadoop-3.2.0并且配置它们的环境变量,方便的办法是在hadoop1上安装配置好Java,用scp命令将Java安装目录和复制到其他虚拟机上,在其他虚拟机配置Java环境变量。然后在把Hadoop做完所有配置后,把Hadoop安装目录传到其他其他虚拟机上,在其他虚拟机上配置Hadoop的环境变量。我参考的很多博客都是这种做法。因为我想把前四个步骤和Hadoop配置文件这步分开,因此我就用笨办法在每一台虚拟机分别做配置了Java和Hadoop。在每一台机器上Java和Hadoop的安装目录不必相同,想放在那都可以。
下面我以在hadoop1安装Java和Hadoop配置环境变量为例操作,其他虚拟机的操作与此相同。
下载好的Hadoop和Java压缩包如下:

在我的计算机上,我将Java解压到/usr/lib/jvm目录下面,你的自己选个喜欢的,一般都是放在根目录的local下面
可以将Java移动到要解压的文件夹,然后解压,也可以在桌面上打开终端,直接解压到自己设定的目录(Hadoop同理也有这样两种做法),在我的计算机上,我将Java解压到/usr/lib/jvm目录下面。
方式一:如果是已经将Java移动到要解压的目录,就在命令行进入该目录,用下属命令解压(Java包名称是你自己的):
移动文件夹或安装包可以使用mv命令也可以手动
cd /usr/lib/jvm
tar -zxvf jdk-8u241-linux-x64.tar.gz

方式二:直接在压缩包所在的位置解压到指定目录,因为我把压缩包放在Desktop,所以就在Desktop解压了。
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/lib/jvm
-C参数制定了要解压的目录
![]()
我将Hadoop解压到/usr/local目录下,Hadoop压缩包在桌面上,因此使用方式二那样的命令:
tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local
Hadoop解压完成后,将访问使用Hadoop-3.2.0目录的权限给当前用户,不然只能在root用户权限下操作不是很操蛋。用下属命令给当前用户权限,这一点很重要,但是没几个博客提到
chown -R 用户名 目录
例如我可以这样设置: chown -R csbo /usr/local/hadoop-3.2.0
将Hadoop和Java解压完之后,就该配置环境变量了,这里选择通过~/.bashrc文件来配置环境变量。用gedit打开该文件并修改:gedit ~/.bashrc
![]()
在末尾添加以下内容:
#set oracle jdk environment
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_241 ## 这里要注意目录要换成自己解压的jdk 目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
#export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop environment
export HADOOP_HOME=/usr/local/hadoop-3.2.0 #这里是你自己的hadoop目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin

用source ~/.bashrc命令使配置立刻生效
![]()
然后用java -version和hadoop version两条命令来检测是否配置成功。如下,说明配置成功
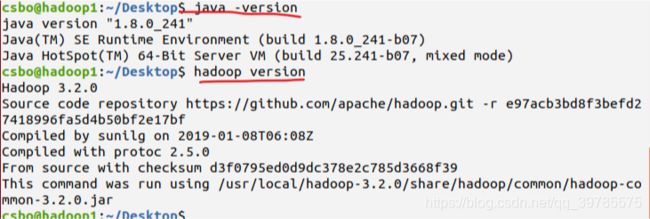
现在hadoop1上的java和Hadoop都安装配置好了,在其他虚拟机同样作上述操作就好了。
五、配置集群分布式环境
上面的四个步骤配置好之后就不需要改动了,第五步是修改Hadoop安装目录下的一些配置文件,这个是想怎么改就怎么改,对一个配置不满意,重新改配置,然后对集群做一个格式化就能按照新的配置运行。
要注意的是每一个虚拟机上的Hadoop都需要做下面的这几步操作,我仅在hadoop1上修改这些文件,其他文件修改同理,每一个虚拟机上这些配置文件的修改内容完全一样(也可以不一样,一样更方便),在一个虚拟机修改好之后其他虚拟机直接复制粘贴就行了。要修改的这些文件都在Hadoop安装目录的/etc/hadoop文件夹下面
- 首先进入Hadoop的安装目录里(我的是/usr/local/hadoop-3.2.0),用
mkdir tmp命令创建一个tmp空目录,后面的配置会用到。 - 然后进入Hadoop安装目录下的/etc/hadoop目录里(我的是/usr/local/hadoop-3.2.0/etc/hadoop,后面的/etc/hadoop目录都是指这个目录),修改其中的六个文件,分别是:workers、hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。可以看到该目录下的文件如下:Hadoop官方对这些文件里的参数做有详细的解释。
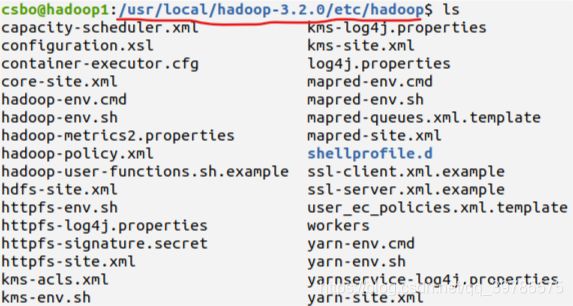
- 首先在/etc/hadoop目录里创建一个workers文件(Hadoop3不是slaves),因为这个原本是没有的。然后在文件中分行写入一些主机名。这个文件的作用是指定那些主机作为Datanode节点。因此这个文件内的主机名,都会被当作Datanode节点。在我的设置中主节点也当作Datanode节点。
如下:

- 修改hadoop-env.sh文件,在其中配置JAVA_HOME,使得Hadoop集群,可以找到Java在哪。 在其中加入如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_241
# 就是JDK的目录配置进去,一定是自己jdk目录的绝对路径

5. 修改core-site.xml。主要是通过修改这个文件指定Namenode的位置在那台主机上。在/etc/hadoop目录下用gedit core-site.xml命令打开core-site.xml文件。将原来的
<configuration>
</configuration>
替换为下面这个:
<configuration>
<property>
<!-- 这个地方指定了namenode所在的节点,这里制定为hadoop1主机,你自己决定你的namenode位置 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<!-- 这个地方指定HDFS保存数据块、元信息和日志的目录 -->
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.2.0/tmp/tmph</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>

从上面的配置可以看出来,这些配置文件都是通过key-value形式来配置Hadoop。
在这里解释一下,一共需要配置三个目录。这里的hadoop.tmp.dir和hdfs-site.xml中的dfs.namenode.name.dir和dfs.datanode.data.dir,这三个目录在我自己的配置中都是指定为前面创建的tmp目录下的子目录,事实上这三个目录配置在哪里都行,我把它们都配置在Hadoop安装目录里面了,方便查找和管理。一定要注意dfs.namenode.name.dir和dfs.datanode.data.dir这两个配置的目录一定要不同,否则当namenode进程运行起来之后会锁住该目录,主节点上的datanode进程就运行不起来了。
- 修改hdfs-site.xml文件,用
gedit hdfs-site.xml打开文件,将原来的
<configuration>
</configuration>
替换为下面这个:
<configuration>
<!--namenode产生的临时文件保存地址,这两个目录位置,自己决定在哪里,不必跟我的一样-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.2.0/tmp/tmpn</value>
</property>
<!--datanode产生的临时文件保存地址,切记要与上面这个要不同,我把他俩分别设置为tmpn和tmpd-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.2.0/tmp/tmpd</value>
</property>
<!--数据块的冗余度(副本),默认:3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
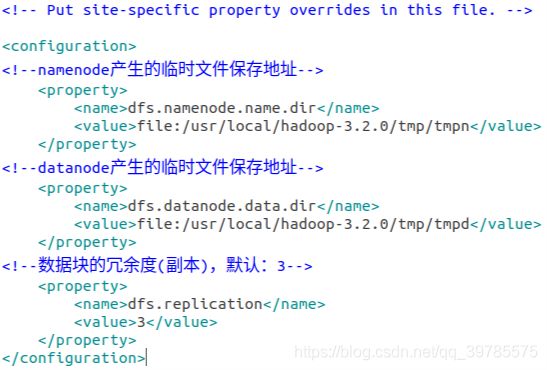
7. 修改mapred-site.xml,用gedit mapred-site.xml打开,将原来的
<configuration>
</configuration>
替换为下面这个:
<configuration>
<!--MapReduce运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

- 修改yarn-site.xml,用
gedit yarn-site.xml命令打开该文件,将原来的
<configuration>
</configuration>
替换为下面这个:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--ResourceManager的地址,也喜欢指定到那个机器就指定到那个机器-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!--MapReduce运行的方式是:shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
</configuration>

上面这个8个步骤,将hadoop1的Hadoop配置好了,把其他主机上的Hadoop都按照上述步骤配置一边,所有文件的内容都跟1到8这几个步骤中的一样。如果会用scp命令就不必这么麻烦了。
六、启动并检测集群是否配置成功
在设定的Namenode节点上,用hdfs namenode -format命令把集群格式化。
格式化完成之后在主节点使用start-all.sh命令启动集群,根据我对集群的配置,在集群启动后,主节点上用jps命令可以看到主节点上有如下进程在运行:
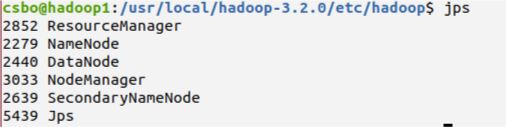
在Datanode从节点上运行jps命令能看到有如下进程在运行:

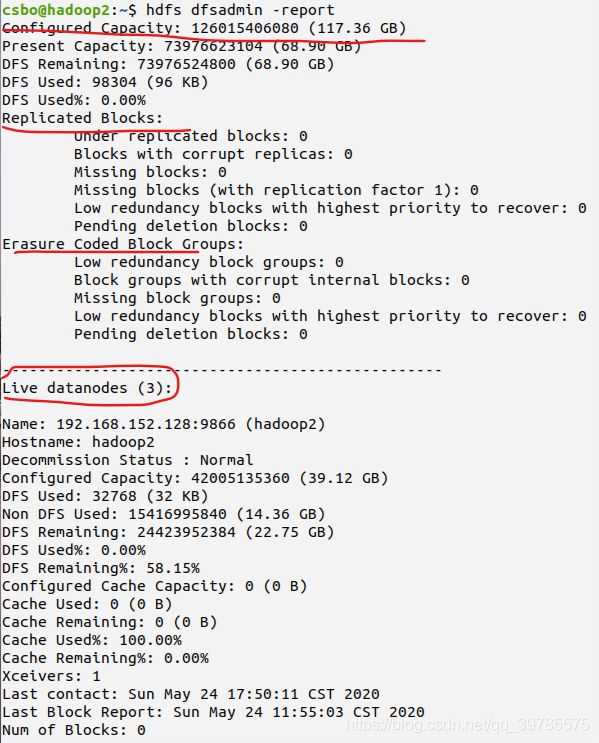
在集群启动后还可以在任意一个节点使用hdfs dfsadmin -report命令来检测集群是否配置成功。如出现下面得内容说明集群配置成功(结果很长,我没有截完):
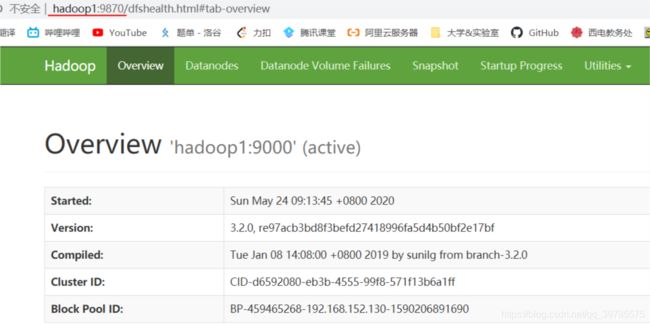
在Hadoop集群启动之后还可以通过在浏览器输入Nmaenode所在的主机名:9870或者Namenode所在的主机ip:9870来查看hdfs的运行情况。比如我可以在浏览器输入hadoop1:9870或者192.168.152.130:9870来查看集群的hdfs分布式系统的情况
同理用resourcemanager所在的主机名:8088或者resourcemanager所在的主机ip:8088,可以看到MapReduce框架的资源调度管理中心节点软件resourcemanager提供的Web监控页面。在我的配置中,Namenode和resourcemanager都在hadoop1上。
最后,如果要重新格式化集群,要先删除Hadoop安装目录下logs目录里面的内容和前面指定的三个目录(hadoop.tmp.dir和hdfs-site.xml中的dfs.namenode.name.dir和dfs.datanode.data.dir)。
终于写完了,先写这么多吧,如果有问题可以评论,我尽量及时回复。