MySQL的备份恢复
mysql的备份恢复
知识要点
1.备份方式
2.mysqldump
3.如何进行备份恢复
4.xtrabackup
5.物理备份原理
6.如何进行物理备份
备份的目的
做灾难恢复:对损坏的数据进行恢复和还原
需求改变:因需求改变而需要把数据还原到改变以前
测试:测试新功能是否可用
备份需要考虑的问题
可以容忍丢失多长时间的数据;与数据量有关系
恢复数据要在多长时间内完;
恢复的时候是否需要持续提供服务;
恢复的对象,是整个库,多个表,还是单个库,单个表。
备份存在的问题
备份对生产影响很大
1、备份对IO的影响
特别是物理备份
2、备份占用网络资源
3、备份会产生锁的问题 (为了保证数据的一致性 会产生锁)
备份对象
1、数据
2、配置文件
3、代码:存储过程、存储函数、触发器,event
4、日志(如果binlog、undo、redo、慢日志、error日志单独存盘的话)
备份方式
冷备(cold backup):shutdown 无法进行各项事务
温备份(warm backup):on ,读 可以查询
热备(hot backup):on ,读写
myisam:支持冷备、支持锁表备份
原因:MyIsam没有日志,只能停机或者锁表备份
innodb:支持热备
原因:每一条语句都写带有时间点的日志,mysql可以根据日志进行redo和undo,将备份时未提交的回滚等。
还可以分为
逻辑备份–对数据行的备份:备份时间比较长,恢复时间也比较长
物理备份–对数据页的备份:备份的数据量比较大,会多储存一些信息
冷备
拿一个备库做,MySQL版本要一致
最好是shutdown时脏数据少一些–关库时间 (关库时间长,开库时间就短)
使用cp或者rsync、scp拷贝所有的东西
优点:最安全
缺点:
备份过程必须关闭数据库
不能按照单独的表或者用户等恢复
如何冷备
保证2台机器上软件版本一致,最好安装版本也一致
A:原机 B:恢复机
A:
将mysql数据库关闭
scp 拷贝到要进行恢复的机器上
启动mysql数据库
B:
注意data目录的mysql权限
启动mysql数据库
冷备举例
1.找到数据库的数据目录,将数据目录拷贝到指定机器同版本的数据库中或者本机
[root@mysql2 mysql]# cp data/* data_bak/
2.复制完以后,修改复制后的属主属组为mysql
[root@mysql2 mysql]#chown -R mysql:mysql mysql_bak/
3.开启登录就可以了
热备
mysqlhotcopy–perl脚本,主要用于myisam,备份期间锁表,已废弃
innobackupex–封装了xtrabackup工具(只备份innodb表),也能备份myisam,模拟了ibbackup
mysql逻辑备份
mysqldump:
缺点:
对于myisam表:锁定
对于innodb表,通过undo的mvcc实现一致性,期间不能进行DDL(建表 删表 改表),会导致数据不一致
备份时间长,所有的块都需要进行读取,抽取数据行,写入备份文件
恢复时间长(磁盘IO,索引创建),比如insert ,过程会产生redo、undo、SQL解析、double write、锁、binlog 等
不适用于大表、大数据库
优点:
能够实现备份+binlog——恢复到任意时间点
可以生成CSV、delimited text、XML format
有助于避免数据损坏,如果磁盘驱动器故障复制文件,文件是损坏的
mysqldump选项
登录选项
-u:用户名
-p:密码
-P:端口
-h:主机地址或者主机名
-S:socket
锁
-x:锁住所有数据库的所有表,整个备份期间加读锁
-l:给所有表加读锁,适用于myisam表
–single-transaction:适用于innodb,不锁表和行,不支持ddl
mysqldump选项-锁
-x, --lock-all-tables
Locks all tables across all databases. This is achieved
by taking a global read lock for the duration of the
whole dump. Automatically turns --single-transaction and
–lock-tables off.
保证整个数据库(所有schema)的数据具有一致性快照
-l, --lock-tables Lock all tables for read.
(Defaults to on; use --skip-lock-tables to disable.)
保证各个schema内部具有数据一致性快照,但是各个schema之间的数据不保证数据一致性
–single-transaction
Creates a consistent snapshot by dumping all tables in a
single transaction. Works ONLY for tables stored in
storage engines which support multiversioning (currently
only InnoDB does); the dump is NOT guaranteed to be
consistent for other storage engines. While a
–single-transaction dump is in process, to ensure a
valid dump file (correct table contents and binary log
position), no other connection should use the following
statements: ALTER TABLE, DROP TABLE, RENAME TABLE,
TRUNCATE TABLE, as consistent snapshot is not isolated
from them. Option automatically turns off --lock-tables.
保证各个表具有数据一致性快照,但是各个表之间的数据可能不是一致状态
–single-transaction
在单个事务中通过创建一个一致性快照来备份所有的表。目前只支持支持MVCC的存储引擎-innodb表;该选项不能保证其他引擎表的一致性,当使用–single-transaction时,要确保表内容和binlog日志的位置来保证这是一个有效的备份文件,没有其他的连接在执行以下语句:ALTER TABLE, DROP TABLE, RENAME TABLE,TRUNCATE TABLE,一致性的快照不能包含这些DDL。该选项会自动关闭–lock-tables;
-F, --flush-logs Flush logs file in server before starting dump. Note that
if you dump many databases at once (using the option
–databases= or --all-databases), the logs will be
flushed for each database dumped. The exception is when
using --lock-all-tables or --master-data: in this case
the logs will be flushed only once, corresponding to the
moment all tables are locked. So if you want your dump
and the log flush to happen at the same exact moment you
should use --lock-all-tables or --master-data with
–flush-logs.
在开始备份前执行flush logs,当使用–databases 或者–all-databases选项备份很多数据库时,对于每个数据库都会执行flush logs,除非使用了–lock-all-tables或者–master-data,只会执行一次flush logs,与所有表被锁住的时刻是一致的。所以如果你想要你的备份和日志刷新发生在高度一致的时刻你应该使用–lock-all-tables或者–master-data和–flush-logs。
mysqldump选项-输出
输出文件类型: sql、txt
-T, --tab=name Create tab-separated textfile for each table to given
path. (Create .sql and .txt files.) NOTE: This only works
if mysqldump is run on the same machine as the mysqld
server.
不使用–tab,会生成带有create和insert的纯sql文本
使用–tab,(secure_file_priv)每个表会生成create的sql文本和txt的数据文本
mysqldump: Got error: 1290: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement when executing ‘SELECT INTO OUTFILE’
举例:
备份:mysqldump -uroot -p123 --tab=/tmp/ ceshi ceshi ##需要修改配置文件,添加一行,修改如图 恢复:
恢复:
mysql -uroot -p123 ceshi mysqlimport -uroot -p123 ceshi /tmp/ceshi.txt (也要修改配置文件,修改如下) 或者 mysql> load data infile ‘/tmp/ceshi.txt’ into table ceshi; ##导入表数据,注意使用绝对 路径
或者 mysql> load data infile ‘/tmp/ceshi.txt’ into table ceshi; ##导入表数据,注意使用绝对 路径
–fields-terminated-by=name (字段分隔符,默认是tab)
Fields in the output file are terminated by the given string.
–lines-terminated-by=name (行分隔符)
Lines in the output file are terminated by the given string.
–fields-enclosed-by=name (字段引用符,每个字段都加双引号)
Fields in the output file are enclosed by the given character.
–fields-optionally-enclosed-by=name (只有char和varchar等字符字段加双引号)
Fields in the output file are optionally enclosed by the given character.
–fields-escaped-by=name (转义字符,默认是\)
Fields in the output file are escaped by the given character.
mysqldump选项
-t, --no-create-info
Don’t write table creation info. ##没有建表语句
-d, --no-data No row information. ##没有数据
-N, --no-set-names Same as --skip-set-charset.
–order-by-primary Sorts each table’s rows by primary key, or first unique
key, if such a key exists. Useful when dumping a MyISAM
table to be loaded into an InnoDB table, but will make
the dump itself take considerably longer.
-q, --quick Don’t buffer query, dump directly to stdout.
(Defaults to on; use --skip-quick to disable.)
-Q, --quote-names Quote table and column names with backticks (`).
(Defaults to on; use --skip-quote-names to disable.)
–replace Use REPLACE INTO instead of INSERT INTO.
-R, --routines Dump stored routines (functions and procedures). #备份存储过程和函数
–triggers Dump triggers for each dumped table. 备份触发器
(Defaults to on; use --skip-triggers to disable.)
-E, --events Dump events. 备份事件
-f, --force Continue even if we get an SQL error. 有错误会不会继续
–master-data[=#] This causes the binary log position and filename to be
appended to the output. If equal to 1, will print it as
a CHANGE MASTER command; if equal to 2, that command will
be prefixed with a comment symbol. This option will turn
–lock-all-tables on, unless --single-transaction is
specified too (in which case a global read lock is only
taken a short time at the beginning of the dump; don’t
forget to read about --single-transaction below). In all
cases, any action on logs will happen at the exact moment
of the dump. Option automatically turns --lock-tables
off.
该选项会在输出中追加上binlog日志的文件名和位置信息,如果设置为1,会打印change master 命令,如果设置为2,会注释掉该命令。该选项默认会打开–lock-all-tables,除非使用了–single-transaction(该种方式会在刚开始备份的时候短暂的加一个全局的读锁),总而言之,备份时的任何动作日志都会发生在高度一致的时刻。该选项会自动关闭–lock-tables。
–delete-master-logs
Delete logs on master after backup. This automatically
enables --master-data.
–include-master-host-port
Adds ‘MASTER_HOST=, MASTER_PORT=’ to ‘CHANGE MASTER TO…’ in dump produced with --dump-slave.
示例:mysqldump -uroot -p123 --master-data=2 ceshi >ceshi.sql //会以注释的形式来形成ceshi.sql
该命令执行之前需要自己检查有没有开启binlog服务,如果没有需要在配置文件中添加如下 重启mysql让其生效
重启mysql让其生效
[root@mysql-rpm ~]# cat ceshi.sql |grep -i “change master to”
– CHANGE MASTER TO MASTER_LOG_FILE=‘binlog.000004’, MASTER_LOG_POS=5725;
[root@mysql-rpm ~]#
如何进行逻辑备份
举例:经典用法
mysqldump -uroot -p123 -l -F --single-transaction ceshi>ceshi.sql
-l:锁住myisam,不锁innodb
-F:刷新binlog,恢复的时候就可以直接使用新binlog开始恢复
–single-transaction:innodb不锁表和行
数据的导出
1、select into outfile——将查询到的结果导出到一个文件中去
原始导出:select * from ceshi into outfile ‘/tmp/ceshi.txt’;
默认:字段分割是tab,行分割是回车,无字段引用符
举例:
指定转义、列分割、字符列加双引号
select * from ceshi1 into outfile ‘/tmp/ceshi1.txt’ FIELDS ESCAPED BY ‘\’ terminated by ‘,’ optionally enclosed by ‘"’; ##最后一个选项是字符列加上双引号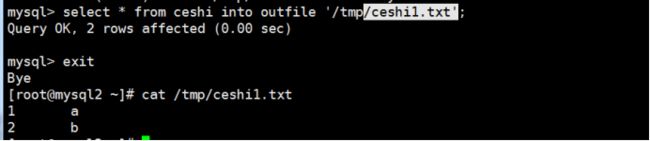 区别
区别 注意:导入导出的指定选项要一致
注意:导入导出的指定选项要一致
2、mysqldump -T
可以导出为.sql文本,也可以导出为文本文件
导出sql:# mysqldump -uroot -p123 ceshi >/tmp/ceshi.sql
原始导出文本:
举例:
指定列分割、字符列加双引号、转义、行分割
mysqldump -uroot -p123 -T /tmp/ --fields-terminated-by=, --fields-optionally-enclosed-by=" --fields-escaped-by=’’ --lines-terminated-by=\n ceshi ceshi
数据的导入
1、load data
举例:
指定转义、字段分隔符、字符串引号、行分隔符
mysql> LOAD DATA INFILE ‘/tmp/ceshi.txt’ into table ceshi.ceshi FIELDS ESCAPED BY ‘\’ terminated by ‘,’ optionally enclosed by ‘"’ lines terminated by ‘\n’;
2、mysqlimport
举例:
指定字段分隔符、字符串引号、转义、行分隔符
mysqlimport -uroot -p123 --socket=/mysql/mysql.sock --fields-terminated-by(列分隔符)=’,’ --fields-enclosed-by="(字段分隔符) --fields-escaped-by=’’(转义字符) --lines-terminated-by(行字符)=’\n’ ceshi /tmp/ceshi1.txt
物理备份工具
xtrabackup:物理备份,备份的数据页
缺点:
1、文件大
2、不总是可以跨平台、操作系统和MySQL版本
优点:
1、基于文件的物理备份
2、恢复快,不需要执行任何SQL语句,不需要构建索引,缓存数据等
3、自动完成备份鉴定
4. 备份的时候不锁innodb
物理备份恢复原理
备份所有数据页和备份期间所有的redo日志–将数据页能恢复到备份结束时刻
+binlog,将数据库恢复到对应的时间点
回滚备份结束时刻未提交的事务
innodb使用redolog保持数据的一致性
myisam使用锁保持备份的一致性
xtrabackup原理
分析备份期间日志:
开始备份,生成xtrabackup_logfile
复制ibd和ibdata1
对myisam表加读锁
复制myisam表相关文件
得到二进制日志的位置,写到xtrabackup_binlog_info
解锁表
停止备份并复制xtrabackup日志
xtrabackup安装
上传资源包 [root@mysql2 ~]# yum localinstall ./*.rpm -y ##自动解决安装顺序问题
[root@mysql2 ~]# yum localinstall ./*.rpm -y ##自动解决安装顺序问题
xtrabackup选项
innobackupex [options] BACKUP-ROOT-DIR
–user=NAME
–password=WORD
–port=PORT
–socket=SOCKET
–parallel=# On backup, this option specifies the number of threads
the xtrabackup child process should use to back up files
concurrently. The option accepts an integer argument. It is passed directly to xtrabackup’s --parallel option. See the xtrabackup documentation for details. ##并行的方式进行备份,时间短
–throttle=# This option specifies a number of I/O operations (pairs
of read+write) per second. It accepts an integer
argument. It is passed directly to xtrabackup’s
–throttle option. ##限流(限制IO操作的流量)备份,因为备份会产生海量的IO。
–no-timestamp ##没有时间戳
–databases=name This option specifies the list of databases that
innobackupex should back up. The option accepts a string
argument or path to file that contains the list of
databases to back up. The list is of the form
“databasename1[.table_name1] databasename2[.table_name2]
. . .”. If this option is not specified, all databases
containing MyISAM and InnoDB tables will be backed up.
Please make sure that --databases contains all of the
InnoDB databases and tables, so that all of the
innodb.frm files are also backed up. In case the list is
very long, this can be specified in a file, and the full
path of the file can be specified instead of the list.
(See option --tables-file.)
–incremental This option tells xtrabackup to create an incremental
backup, rather than a full one. It is passed to the
xtrabackup child process. When this option is specified,
either --incremental-lsn or --incremental-basedir can
also be given. If neither option is given, option
–incremental-basedir is passed to xtrabackup by default,set to the first timestamped backup directory in the backup base directory.
该选项会告诉xtrabackup去创建一个增备,而不是全备。通过xtrabackup的子进程实现的。当该选项被指定,需要指定–incremental-lsn 或者 --incremental-basedir,如果都没有指定,默认会以第一次备份的时间戳的备份作为基准进行增备。
全备:是数据库的所有的数据都进行备份
增备:是备份上次全备以来发生改变的数据页,基于全备,只能在全备机器上恢复。虽然数据量少,但是增备并没有减少海量的IO
–incremental-basedir=name
This option specifies the directory containing the full
backup that is the base dataset for the incremental
backup. The option accepts a string argument. It is used
with the --incremental option.//基于哪一个备份去做增备
–incremental-dir=name
This option specifies the directory where the incremental backup will be combined with the full backup to make a new full backup. The option accepts a string argument. It is used with the --incremental option.
//备份到哪个文件
innobackupex [options] BACKUP-DIR
–apply-log ##应用日志
–redo-only ##只前滚不回滚
恢复
innobackupex --copy-back [–defaults-file=MY.CNF] BACKUP-DIR ##复制恢复
时间长
innobackupex --move-back [–defaults-file=MY.CNF] BACKUP-DIR ##剪切恢复 时间短
操作物理全备与恢复
创建备份目录
mkdir /backup
备份数据库
innobackupex --user=root --password=123 /backup/
应用redo(自带回滚)
innobackupex --apply-log /backup/2017-09-09_21-27-05/
关闭数据库
拷贝my.cnf配置文件
恢复数据库
innobackupex --copy-back /backup/2017-09-09_21-27-05/
修改数据目录权限
chown -R mysql:mysql .
覆盖my.cnf配置文件
启动数据库
service mysqld start
查看端口是否启动成功
netstat -tnulp|grep 330
查看数据是否恢复
备份内容介绍
xtrabackup_info
xtrabackup_binlog_info
xtrabackup_checkpoints
增量备份
只有在还原和 binlog 接壤的地方,才会进行回滚,其他所有地方都不进行回
滚。
1、增量的含义是自上次备份以来发生改变的数据页
2、增量备份并没有降低 IO,也是全扫描
3、增量备份不是很适合 OLTP 系统
4、增量备份适合数据仓库系统
–incremental-basedir=name //指定全备位置(也可能是增量备份)
–incremental-dir=name //指定增量目录
–incremental //指定进行增量
增量需要指定在谁的基础上增量:
1、可以在全备的基础上进行增量
2、也可以在增量的基础上进行增量
增量备份
1、在谁的基础上进行增量
全备
增量
2、增量恢复的时候,只要没有和 binlog 对接,就一直使用 redo-only,不要
进行回滚,否则恢复失效
3、在和 binlog 对接的时候,最好不要加上 redo-only,实现自动回滚,如果
加上了 redo-only,也没有问题
4、增量备份适合数据仓库系统,不是很适合在线交易系统
5、设计一套带有全备和增量的备份方案,要求恢复增量不超过 2 次,尽量
降低备份的数据量、备份实现自动化
写出各个时间点的恢复方案,模拟一个删除操作,进行相应的恢复
案例
物理备份数据库 , 删除一个表 , 进行恢复 , 将表恢复回来 , 重新导入
到生产库
完全模拟一下:全备+第一次增备+第二次增备+完全备份的 prepare:
1 、备份
完全备份:
全备一般不使用时间戳目录
[root@root backup]# innobackupex --user=root --password="" /backup
应用全备:
备份完成以后,接着做一个下面的动作,因为后面会有增量,所以这个地方
需要加上 redo-only
[root@root backup]# innobackupex --apply-log --redo-only
2016-09-13_21-35-38/
全备和增备之间数据库中要有增量
第一次增备:在全备的基础上做的增量
[root@root backup]# innobackupex --user=root --password=""
–incremental --incremental-basedir=/backup/2016-09-13_21-35-38/ /backup
–incremental:接上增备的目标路径
–incremental-basedir=:接上上次备份的路径,可以是全备,也可以是增备
第二次增备:增备不能单独存在
在第一次增备的基础上做的增量
[root@root 2016-09-13_21-44-15]# innobackupex --user=root
–password="" --incremental /backup
–incremental-basedir=/backup/2016-09-13_21-44-15/
2 、 模拟故障:
误操作删除一个表,要恢复到之前的状态:
[root@localhost][test]> drop table t1;
3 、 恢复演练:
应用第一次增备:
将第一次增备的内容合并到全备中去:
[root@root 2016-09-13_21-44-15]# innobackupex --apply-log --redo-only
–incremental /backup/2016-09-13_21-35-38/
–incremental-dir=/backup/2016-09-13_21-44-15/
–incremental:接上全备的路径
–incremental-dir=:增备的位置,要把哪个增备打到全备中去
应用第二次增备:
将第二次备份合并到全备当中去:(因为后面没有增备,是最后一次备份,
可把 redo-only 去掉)
[root@root 2016-09-13_21-44-15]# innobackupex --apply-log --incremental
/backup/2016-09-13_21-35-38/
–incremental-dir=/backup/2016-09-13_21-48-56/
注意:增备期间的redo不能单独应用,因为增备时的redo是基于增备本身的,而增备本身只是作为备份自上次改变的数据页,并不具备应用的条件。
得到如下结果;
[root@root backup]# cat 2016-09-13_21-35-38/xtrabackup_checkpoints
backup_type = log-applied
from_lsn = 0
to_lsn = 1517492
last_lsn = 1517492
compact = 0
recover_binlog_info = 0
[root@root backup]#
现在两次增备的内容已经应用到全备中
4 、关闭数据库,删除数据库(删除的时候,不要删除 binlog )
[root@root ~# service mysqld stop
[root@root backup2]# cd /usr/local/MySQL/data/
[root@root data]# mkdir binlogbak
[root@root data]# mv MySQLserver.* binlogbak/
[root@root data]# rm -f *
[root@root data]# rm -rf MySQL/ performance_schema/ test/
[root@root data]# ls
binlogbak
[root@root data]#
5 、恢复数据库
把 binlog 复制出来,不要拷贝到数据库目录下去了,因为做 copy-back 的时
候也会复制,非常慢
[root@root backup]# mv binlogbak/ /backup_binlog/
将备份目录下的所有内容拷贝到数据库目录:
[root@root backup]# innobackupex --copy-back /backup/
[root@root backup]# mv /backup_binlog/ /usr/local/MySQL/data
授予 MySQL 属主属组:
[root@root MySQL]# chown -R mysql:MySQL .
重启数据库:
[root@root MySQL]# MySQLd_safe --defaults-file=/etc/my.cnf &
找到 binlog 恢复的起止点:
[root@root data]# cd backup_binlog/
Binlog 的起点:
[root@root 2016-09-13_21-35-38]# cat xtrabackup_binlog_info
MySQLserver.000003 472
[root@root 2016-09-13_21-35-38]#
Binlog 的终点:
[root@root backup_binlog]# MySQLbinlog -vv
MySQLserver.000006|grep -i “drop table t1” -C 20
-C 20:截取上下 20 行,找到 at 后面的位置
[root@root backup_binlog]# MySQLbinlog --start-position=120
–stop-position=564 MySQLserver.000003 > a.sql
跑 跑 binlog :
[root@root backup_binlog]# cat a.SQL |mysql
6 、恢复过程中要监控
[root@localhost][test]> show processlist;
7 、查看数据有没有恢复回来:
[root@localhost][test]> select * from t1;
±-----+
| id |
±-----+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
±-----+
9 rows in set (0.00 sec)
[root@localhost][test]>
演练
1、将xtrabackup工具备份的过程分析总结成原理
2、将xtrabackup工具redo应用的过程分析及恢复总结成原理
3、将每个举例及案例的内容做一遍,熟练掌握mysqldump和xtrabackup工具的全备增备及恢复。
4、去官方文档中找一种单表快速恢复的方法
提示tablespace
5、设计一个基于一周周期的备份方案,要求增备不少于2次,全备1次,自动化完成,考虑因素:备份之间的间隔时间,输入故障时间点能完成该工具的异机自动化备份恢复,然后再输入binlog的起点和终点完成整个备份恢复单表。