2019MIT深度学习基础课程:简介以及TensorFlow案例概要
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Lex Fridman
编译:ronghuaiyang
2019的MIT的最新深度学习教程,内容包括神经网络解决计算机视觉、自然语言处理、游戏、自动驾驶、机器人等领域问题的基础知识。来一睹为快吧!

麻省理工学院深度学习系列课程(6.S091, 6.S093, 6.S094)。讲座视频和教程对所有人开放。
作为麻省理工学院深度学习系列讲座和GitHub教程的一部分,我们将介绍使用神经网络解决计算机视觉、自然语言处理、游戏、自动驾驶、机器人等领域问题的基础知识。
这篇博客文章提供了7个体系结构范例的深度学习概述,每个范例都有TensorFlow教程的链接。
深度学习是表征学习:从数据中自动形成有用的表征。我们如何表现世界,可以让复杂的东西在我们人类和我们建立的机器学习模型看来都很简单。
关于前者,我最喜欢的例子是1543年哥白尼发表的《日心说》(heliocentric model),它将太阳置于“宇宙”的中心,而不是之前的《地心说》(geocentric model)中把地球置于中心的观点。在最好的情况下,深度学习可以让我们自动完成这一步,从特征工程中去掉哥白尼(也就是我们所说的人类专家):
在高层次上,神经网络要么是编码器,要么是解码器,要么是两者的组合:
编码器在原始数据中查找模式,以形成紧凑、有用的表示形式。
解码器从这些表示生成高分辨率数据。生成的数据要么是新的示例,要么是描述性知识。
其余的则是一些聪明的方法,它们可以帮助我们有效地处理视觉信息、语言、音频(第1-6条),甚至可以在一个基于这些信息和偶尔奖励的世界中采取行动(第7条)。这是宏观视图:
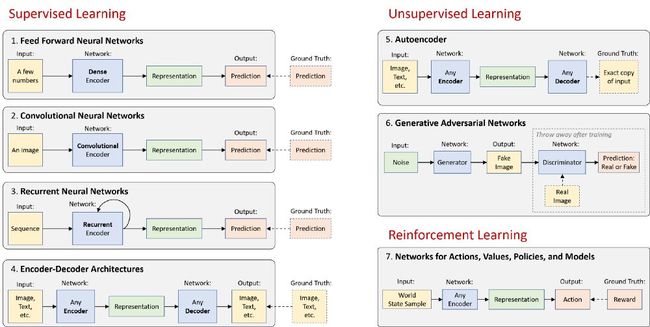
在下面的部分中,我将简要描述这7个体系结构范例,并提供每个范例的演示性TensorFlow教程的链接。参见最后的“超越基础”部分,该部分讨论了深度学习的一些令人兴奋的领域,这些领域并不完全属于这七个类别。
1. 前馈神经网络(FFNNs)

FFNNs的历史可以追溯到20世纪40年代,它只是没有任何循环的网络。数据以单次传递的方式从输入传递到输出,而没有以前的任何“状态内存”。从技术上讲,深度学习中的大多数网络都可以被认为是FFNNs,但通常“FFNN”指的是其最简单的变体:紧密连接的多层感知器(MLP)。
稠密编码器用于将输入上已经很紧凑的一组数字映射到预测:分类(离散)或回归(连续)。
TensorFlow教程:请参阅我们的Deep Learning Basics Tutorial第1部分,它是一个将FFNNs用于波士顿房价预测的回归问题的示例:
2. 卷积神经网络 (CNNs)

CNNs(又名ConvNets)是一种前馈神经网络,它使用一种空间不变的技巧有效地学习图像中的局部模式,这种方法在图像中最为常见。空间不变性是指图像左上角的猫耳与图像右下角的猫耳具有相同的特征。CNNs跨空间共享权重,使猫耳等模式的检测更加高效。
它们不是只使用紧密连接的层,而是使用卷积层(卷积编码器)。这些网络用于图像分类、目标检测、视频动作识别以及任何在结构上具有一定空间不变性的数据(如语音音频)。
TensorFlow教程:参见Deep Learning Basics Tutorial第2部分,这是一个用于对MNIST数据集中的手写数字进行分类的CNNs示例,带有一个漂亮的梦幻般的扭曲,其中我们在生成的高分辨率上测试分类器,从数据集外部变形手写数字:
3. 循环神经网络 (RNNs)

RNN是具有循环的网络,因此具有“状态内存”。它们可以即时展开,成为权重共享的前馈网络。正如CNNs在“空间”上共享权重一样,RNNs在“时间”上共享权重。这使得它们能够处理并有效地表示顺序数据中的模式。
已经开发了许多RNNs模块的变体,包括LSTMs和GRUs,以帮助学习更长的序列中的模式。应用包括自然语言建模、语音识别、语音生成等。
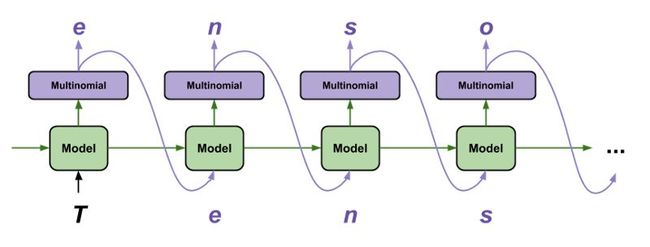
TensorFlow教程:循环神经网络的训练是很有挑战性的,但同时也允许我们对序列数据进行一些有趣和强大的建模。关于使用TensorFlow生成文本的教程是我最喜欢的教程之一,因为它用很少的几行代码就完成了一些了不起的事情:在字符的基础上生成合理的文本:
4. Encoder-Decoder结构

前3节中介绍的FFNNs、CNNs和RNNs只是分别使用密集编码器、卷积编码器或循环编码器进行预测的网络。这些编码器可以组合或切换,这取决于我们试图形成的有用表示的原始数据类型。“Encoder-Decoder”架构是一种更高层次的概念,它构建在编码步骤之上,通过对压缩表示的上采样,通过解码步骤生成高维输出,而不是进行预测。
请注意,编码器和解码器可以是非常不同的彼此。例如,图像字幕网络可能有卷积编码器(用于图像输入)和循环解码器(用于自然语言输出)。应用包括语义分割、机器翻译等。
TensorFlow教程:看一下我们在 Driving Scene segmentation上的教程,展示了一个最先进的自动驾驶车辆感知问题分割网络:
5. 自动编码器
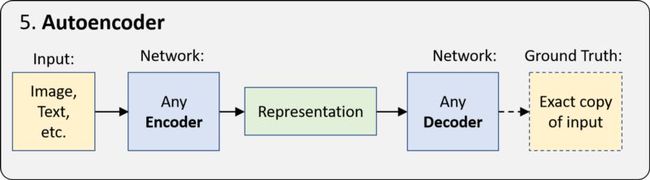
自动编码器是一种更简单的“无监督学习”形式,采用encoder-decoder体系结构,并学习生成输入数据的精确副本。由于编码的表示比输入数据小得多,网络被迫学习如何形成最有意义的表示。
由于ground truth数据来自输入数据,所以不需要人工操作。换句话说,它是自我监督的。它的应用包括无监督嵌入、图像去噪等。但最重要的是,它的“表示学习”的基本思想是下一节生成模型和所有深度学习的核心。
TensorFlow教程:您可以在TensorFlow Keras教程中探索自动编码器对MNIST数据集(1)去噪输入数据和(2)嵌入形成的能力。
6. 生成对抗网络(GANs)
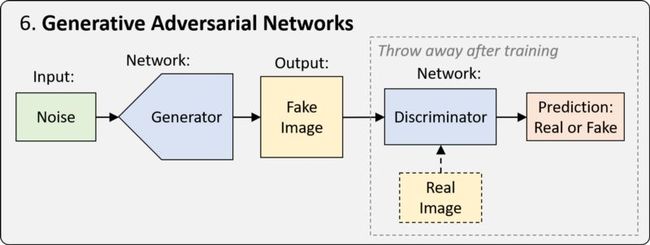
GANs是一种用于训练网络的框架,这种网络经过优化,可以从特定的表示中生成新的现实样本。在最简单的形式下,训练过程涉及两个网络。其中一个网络称为“生成器”,它生成新的数据实例,试图欺骗另一个网络“判别器”,后者将图像分为真图像和假图像。
在过去的几年中,GANs被提出了许多变体和改进,包括从特定类生成图像的能力、从一个域映射到另一个域的能力,以及生成图像的真实性的惊人提高。参见关于Deep Learning State of the Art的讲座,该讲座涉及并描述了GANs的快速发展。例如,看一看BigGAN从单一种类(蝇木耳)中产生的三个样本(arXiv论文):


TensorFlow教程:参见conditional GANs和DCGANs中的教程,了解GANs早期变体的示例。随着课程的进展,我们将在GitHub上发布GANs中最先进的教程。
7. 深度强化学习 (Deep RL)
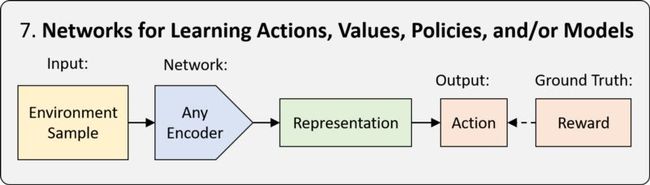
强化学习(RL)是一个框架,用来教一个主体如何在世界上以一种最大化回报的方式行动。当学习由神经网络完成时,我们称之为深度强化学习(Deep Reinforcement learning, Deep RL)。RL框架有三种类型:基于策略的、基于值的和基于模型的。区别在于神经网络的任务是学习。参见麻省理工学院课程6的Introduction to Deep RL讲座。查询更多详情。Deep RL允许我们在需要做出一系列决策的模拟或现实环境中应用神经网络。这包括游戏、机器人、神经结构搜索等等。
教程:我们的DeepTraffic环境提供了一个教程和代码示例,用于在浏览器中快速探索、训练和评估Deep RL代理,我们将很快发布TensorFlow教程,用于GitHub上支持gpu的训练:

基础之外
在深度学习中有几个重要的概念并不是由上面的架构直接表示的。例如Variational Autoencoders (VAE)、LSTM/GRU或Neural Turing Machine上下文中的"记忆"概念、Capsule Networks、注意力的概念、迁移学习的概念、元学习,以及RL中基于模型、基于值、基于策略的方法和行为批评方法的区别。最后,许多深度学习系统将这些体系结构以复杂的方式组合起来,共同从多模态数据中学习,或者共同学习解决多个任务。这些概念在本课程的其他课程中都有涉及,更多的概念将在接下来的课程中介绍:



就我个人而言,正如我在评论中所说的,能有机会在麻省理工学院任教,我感到很荣幸,能成为人工智能和TensorFlow社区的一员,我感到很兴奋。感谢大家在过去几年的支持和讨论。这是一次奇妙的旅行。如果你对我在以后的课程中应该涉及的主题有任何建议,请告诉我(在Twitter或LinkedIn)。
 —
END—
—
END—
英文原文:https://medium.com/tensorflow/mit-deep-learning-basics-introduction-and-overview-with-tensorflow-355bcd26baf0

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!