MyDLNote - Network: [18ECCV] Image Inpainting for Irregular Holes Using Partial Convolutions
Image Inpainting for Irregular Holes Using Partial Convolutions
我的博客尽可能提取文章内的主要传达的信息,既不是完全翻译,也不简单粗略。论文的motivation和网络设计细节,将是我写这些博客关注的重点。
先说下这个文章。概念很新,算是开创性工作。但也存在一些问题,这些问题在文章《Image Inpainting with Learnable Bidirectional Attention Maps》提出并改进。也可以参考我的博客:
MyDLNote - Inpainting: Image Inpainting with Learnable Bidirectional Attention Maps
目录
Image Inpainting for Irregular Holes Using Partial Convolutions
Abstract
Introduction
Approach
Partial Convolutional Layer
Network Architecture and Implementation
Loss Functions
Abstract
Existing deep learning based image inpainting methods use a standard convolutional network over the corrupted image, using convolutional filter responses conditioned on both valid pixels as well as the substitute values in the masked holes (typically the mean value). This often leads to artifacts such as color discrepancy and blurriness. Postprocessing is usually used to reduce such artifacts, but are expensive and may fail. We propose the use of partial convolutions, where the convolution is masked and renormalized to be conditioned on only valid pixels. We further include a mechanism to automatically generate an updated mask for the next layer as part of the forward pass. Our model outperforms other methods for irregular masks. We show qualitative and quantitative comparisons with other methods to validate our approach.
标准卷积的方法:修复时,卷积遍历整个图像。卷积的输出是对有效像素和mask空洞中的替换值来计算的,但后者是不应该用来包括进来。这样需要加入后处理,但通常是耗时或无效的。
本文的Pcovn,1)卷积是经过mask的,2)renormalize则只考虑有效像素,3)自动生成下一层的更新mask,作为前向传递的一部分。
Introduction
Previous deep learning approaches have focused on rectangular regions located around the center of the image, and often rely on expensive post-processing. The goal of this work is to propose a model for image inpainting that operates robustly on irregular hole patterns (see Fig. 1), and produces semantically meaningful predictions that incorporate smoothly with the rest of the image without the need for any additional post-processing or blending operation.
本文的目的:不规则空洞修复; 不借助后处理或blending操作,产生语义上有意义的预测。
To properly handle irregular masks, we propose the use of a Partial Convolutional Layer, comprising a masked and re-normalized convolution operation followed by a mask-update step. The concept of a masked and re-normalized convolution is also referred to as segmentation-aware convolutions in [Segmentation-aware convolutional networks using local attention masks] for the image segmentation task, however they did not make modifications to the input mask.
不规则空洞修复手段:为了正确处理不规则掩码,我们建议使用部分卷积层,它包括掩码和重新归一化卷积操作,然后是 mask 更新步骤。在 [Segmentation-aware convolutional networks using local attention masks] 中,对于图像分割任务,掩码和重新归一化卷积的概念也被称为分割感知卷积,但是它们没有对输入掩码进行修改。
Our use of partial convolutions is such that given a binary mask our convolutional results depend only on the non-hole regions at every layer. Our main extension is the automatic mask update step, which removes any masking where the partial convolution was able to operate on an unmasked value. Given sufficient layers of successive updates, even the largest masked holes will eventually shrink away, leaving only valid responses in the feature map. The partial convolutional layer ultimately makes our model agnostic to placeholder hole values.
部分卷积策略:我们使用的部分卷积是这样的,给定一个二进制mask,我们的卷积结果只依赖于每一层的非空洞区域。我们的主要扩展是自动mask更新步骤,它删除了部分卷积能够对未masked值进行操作的任何mask。如果有足够的连续更新层,即使最大的掩蔽漏洞最终也会消失,只在功能图中留下有效的响应。部分卷积层最终使我们的模型不受占位符空洞值的影响。
Approach
Partial Convolutional Layer
我的理解:partial convolution layer = partial convolution + mask update
partial convolution:
We refer to our partial convolution operation and mask update function jointly as the Partial Convolutional Layer. Let W be the convolution filter weights for the convolution filter and b is the corresponding bias. X are the feature values (pixels values) for the current convolution (sliding) window and M is the corresponding binary mask. The partial convolution at every location, similarly defined in [Segmentation-aware convolutional networks using local attention masks], is expressed as:

where  denotes element-wise multiplication, and 1 has same shape as M but with all the elements being 1. As can be seen, output values depend only on the unmasked inputs. The scaling factor sum(1)/sum(M) applies appropriate scaling to adjust for the varying amount of valid (unmasked) inputs.
denotes element-wise multiplication, and 1 has same shape as M but with all the elements being 1. As can be seen, output values depend only on the unmasked inputs. The scaling factor sum(1)/sum(M) applies appropriate scaling to adjust for the varying amount of valid (unmasked) inputs.
先给出 partial convolution 的定义。
比例因子sum(1)/sum(M)用来调整适当的比例对有效 (unmasked) 输入的变化量。
输出只取决于输入的非 masked 区域。
mask update:
After each partial convolution operation, we then update our mask as follows: if the convolution was able to condition its output on at least one valid input value, then we mark that location to be valid. This is expressed as:

and can easily be implemented in any deep learning framework as part of the forward pass.
mask更新准则:如果卷积能够将它的输出条件设置为至少一个有效的输入值,那么我们将该位置标记为有效。
可以应用于任何深度学习网络的前馈网络当中。
Network Architecture and Implementation
Network Design. We design a UNet-like architecture similar to the one used in [pix2pix], replacing all convolutional layers with partial convolutional layers and using nearest neighbor up-sampling in the decoding stage. The skip links will concatenate two feature maps and two masks respectively, acting as the feature and mask inputs for the next partial convolution layer. The last partial convolution layer’s input will contain the concatenation of the original input image with hole and original mask, making it possible for the model to copy non-hole pixels. Network details are found in the supplementary file.
Partial Convolution as Padding. We use the partial convolution with appropriate masking at image boundaries in lieu of typical padding . This ensures that the inpainted content at the image border will not be affected by invalid values outside of the image – which can be interpreted as another hole.
本文采用的网络是 pix2pix,其中所有的卷积换为 PConv,最后一层的输入将通道相加输入图像和初始 mask(就是一个残差式结构)。
传统的 padding 是直接在 feature map 边缘补 0。而本文则把边缘也当做是空洞,用 PConv 去学习并补充。
Loss Functions
perpixel losses
![]()
perceptual loss

style-loss
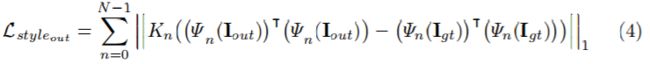
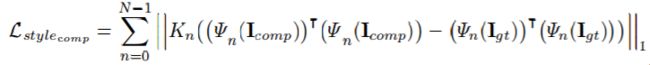
total variation (TV) loss

Removing Checkerboard Artifacts and Fish Scale Artifacts:
Perceptual loss is known to generate checkerboard artifacts. Johnson et al. suggests to ameliorate the problem by using the total variation (TV) loss. We found this not to be the case for our model. Figure 3(b) shows the result of the model trained by removing ![]() and
and ![]() from
from ![]() . For our model, the additional style loss term is necessary. However, not all the loss weighting schemes for the style loss will generate plausible results. Figure 3(f) shows the result of the model trained with a small style loss weight. Compared to the result of the model trained with full
. For our model, the additional style loss term is necessary. However, not all the loss weighting schemes for the style loss will generate plausible results. Figure 3(f) shows the result of the model trained with a small style loss weight. Compared to the result of the model trained with full ![]() in Figure 3(g), it has many fish scale artifacts. However, perceptual loss is also important; grid-shaped artifacts are less prominent in the results with full
in Figure 3(g), it has many fish scale artifacts. However, perceptual loss is also important; grid-shaped artifacts are less prominent in the results with full ![]() (Figure 3(k)) than the results without perceptual loss (Figure 3(j)). We hope this discussion will be useful to readers interested in employing VGG-based high level losses.
(Figure 3(k)) than the results without perceptual loss (Figure 3(j)). We hope this discussion will be useful to readers interested in employing VGG-based high level losses.
![MyDLNote - Network: [18ECCV] Image Inpainting for Irregular Holes Using Partial Convolutions_第1张图片](http://img.e-com-net.com/image/info8/0d566e15f2fb4eaabb492627219d8f53.jpg)