深度学习第57讲:深度强化学习与深度Q网络(DQN)
上一讲笔者和大家简单介绍了强化学习的相关概念,了解了Q-Learning算法及其简单实现实例。本节笔者将在上一讲的基础上,将强化学习回归到深度学习的主题上。
深度强化学习
强化学习+深度学习的一个结果就是形成了深度强化学习这样的新领域,本节我们先简单介绍一下深度强化学习,然后来看一下深度神经网络是如何跟强化学习算法相结合的。
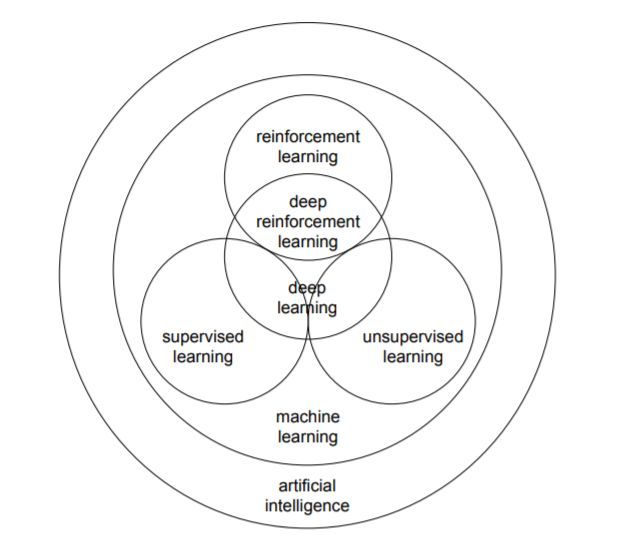
关于深度强化学习,这里有一篇非常详细的综述论文,笔者仅简单介绍一下。在这篇综述中,作者力图回答以下三个问题:1)为什么强化学习要引入深度学习?2)目前深度强化学习最前沿的进展有哪些?3)目前深度强化学习存在哪些问题以及未来可应对的解决方案。

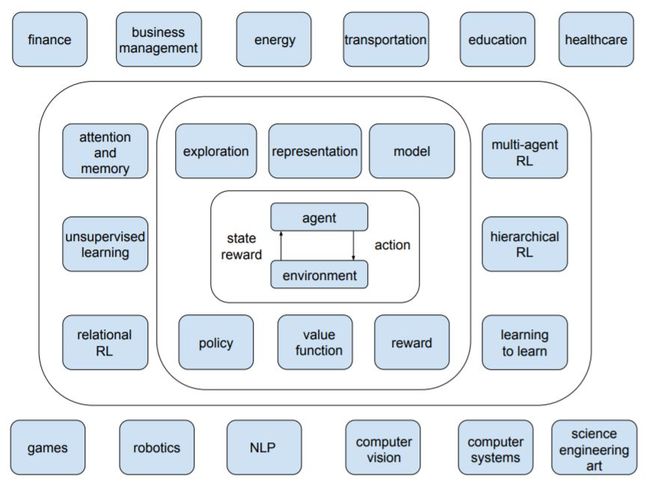
作者在论文中逐步讨论了深度强化学习的 6 个核心元素、6 个重要机制和12个主要的应用场景。6 个核心元素包括值函数 (value function)、策略 (policy)、奖赏 (reward)、模型 (model)、探索与利用 (exploration vs. exploitation)、以及表征 (representation),6 个重要机制包括注意力与存储机制 (attention and memory)、无监督学习 (unsupervised learning)、层次强化学习 (hierarchical RL)、多智能体强化学习 (multi-agent RL)、关系强化学习 (relational RL)、和元学习 (learning to learn)
,而12 个应用场景包括游戏 (games)、机器人学 (robotics)、自然语言处理 (natural language processing, NLP)、计算机视觉 (computer vision)、金融 (finance)、商务管理 (business management)、医疗 (healthcare)、教育 (education)、能源 (energy)、交通 (transportation)、计算机系统 (computer systems)、以及科学、工程和艺术 (science, engineering, and art)。可以是对深度强化学习做了非常全面和详尽的介绍。
Deep Q Network
上一讲我们简单说了下Q-Learning算法并给出了一个代码实例。这里我们再简单描述一下Q-Learning算法的整体思路。在给定状态、行为、Q值和奖励等概念的情况下,我们先初始化一个Q值的Q-Table,然后对每一个episode重复执行每一步:根据状态S来选取要执行的行为,然后观察奖励和新的状态,根据Q函数更新公式进行更新。Q-Learning算法流程可简要概述如下:
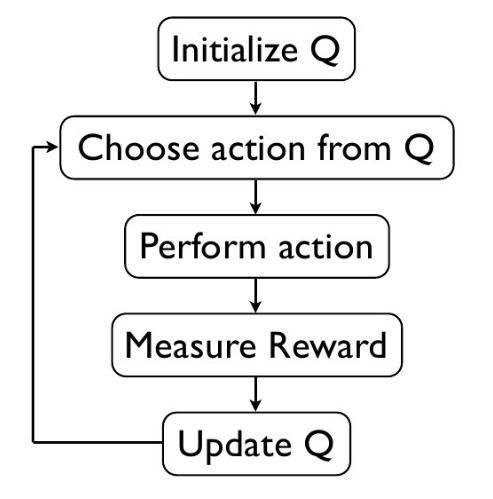
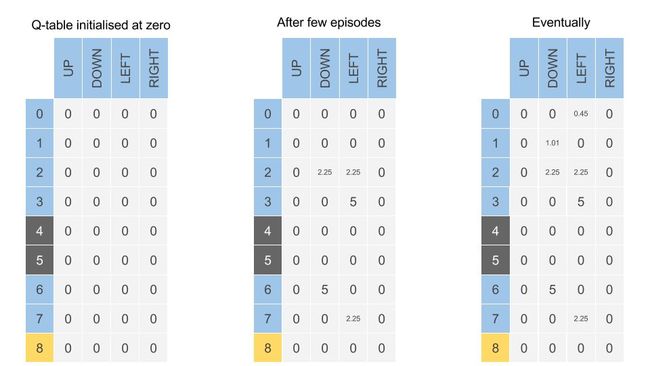
可以看到,我们在初始化Q值的时候使用了一个Q-Table来存储Q值,这样做无疑非常方便。但在问题非常复杂时,我们有无数多状态和行为时,如果还用表格还存储Q值恐怕是不行的。一是内存不够,二是在巨大表格里搜索状态会非常耗时。
所以当问题复杂到Q-Table难以表示的时候,我们就会想到用一个价值近似函数来表示Q(S, A),这个近似函数长什么样,咱们不一定清楚。带有参数的价值近似函数如下所示:
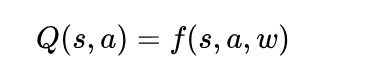
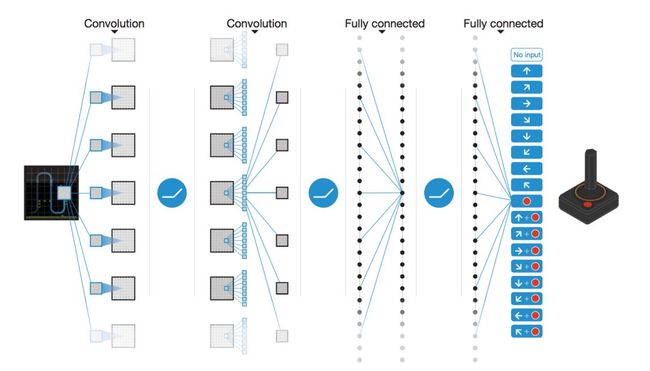
既然价值近似函数没有固定的形式,不如我们用神经网络来表示它好了。这就是强化学习与深度学习进行结合的第一步,也是最重要的一步。到这里,传统的Q-Learning算法中的Q值就成了Q网络。Q-Learning算法这种通过神经网络来表示Q(S, A)的方式,发展到现在就成了著名的深度Q网络(Deep Q Networks)。比如说下图的DQN通过卷积层和全连接层将输入转化为包含每一个动作Q值的向量。
那么下面的一个关键问题是:如何训练这样一个深度Q网络?我们前面学习了DNN、CNN、RNN等等网络,知道是通过反向传播算法来优化一个损失函数,使得神经网络的损失最小化。这里的问题在于我们目前只知道输入数据,不知道Q网络的输出标签是什么,作为一个监督学习问题,没有标签肯定是无法进行神经网络的训练的。
因而问题就变成了如何给Q网络提供训练标签。答案就在于Q-Learning算法。说了半天的神经网络与Q-Learning的结合,在这里体现出来了。在Q-Learning算法中,Q值的更新依靠是奖励值R和根据Q计算出来目标Q值,根据Q-Learning算法过程公式我们也可以看到这一点:
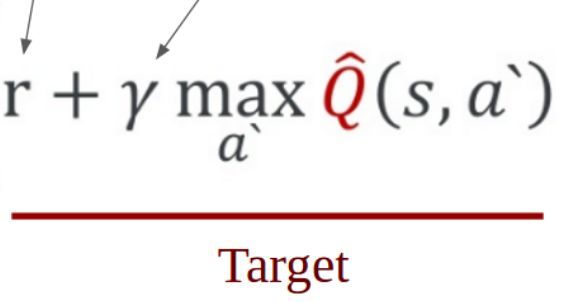
所以这里我们直接把目标Q-Learning计算得到的Q值作为神经网络的训练标签就好了,最后我们可以得到Q网络的损失函数为:

这样一来,DQN的训练数据和标签、损失函数都具体化了,接下来就是如何训练的问题了。直接按照常规神经网络的方式来训练深度Q网络得到每个状态的最优解当然可以,但实际情况要相对麻烦一点。一般来说,使用非线性函数得到近似的Q值非常不稳定,要训练使得整个网络真正达到收敛需要一些专门的技巧。其中一个重要的技巧就是Experience Replay,可以译为经验回放,简单来说,经验回放就是如何存储训练过程中的样本以及如何在训练中进行实时采样的问题。关于更细节的问题,感兴趣的朋友可以研读DQN相关的论文,笔者这里不做详细展开。

DQN的TensorFlow参考代码如下:
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/5_Deep_Q_Network
参考资料:
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
https://zhuanlan.zhihu.com/p/21421729
DEEP REINFORCEMENT LEARNING
往期精彩:
一个数据科学从业者的学习历程


长按二维码.关注机器学习实验室
