Hadoop
- Hadoop时Apache提供的一套开源的、可靠的、可伸缩(扩展)的、用于分布式存储和计算的框架。
- Hadoop模块:
-
Hadoop Common:基本模块,用于支持其他模块
-
Hadoop Distributed Filesytem:分布式存储框架
-
Hadoop Yarn:任务调度和集群资源管理
-
Hadoop MapReduce:分布式计算
-
Hadoop Ozone:对象存储
-
Hadoop submarine:机器学习引擎
-
-
HDFS
-
概述:
-
HDFS中,存储数据的时候会将数据进行切块,每一个块称之为Block
-
HDFS中,主要包含2个重要的进程:NameNode和DataNode
-
NameNode用于管理节点和记录元数据(metadata)
-
DataNode是用于存储数据
-
-
HDFS会对数据自动进行备份,称之为副本(replication)。如果不指定,默认情况下副本数量为3(额外复制两次,加上原来的数据构成3个副本)
-
HDFS仿照Linux设计了一套文件存储系统
-
-
特点:
- 能够存储超大文件 - 分布式 + 切块
- 能够快速的应对和检测故障 - 心跳
- 高可用 - 副本 + 双NameNode
- 能够动态扩展在廉价机器上 - 横向扩展
- 不支持低延迟响应
- 不建议存储小文件 - 每一个小文件会对应一条元数据,大量小文件则会产生大量元数据,元数据多了就会导致元数据的查询效率也变慢
- 简化的一致性模型 - 允许一次写入多次读取
- 不支持事务
-
Block
-
在HDFS中,数据都是以Block为单位进行存储的
-
默认情况下,Block的大小是128M,通过dfs.blocksize来调节大小
-
如果一个文件不足一个Block大小,则这个文件整体作为一个Block存储,并且Block的大小和文件大小是一致的
-
会给每一个Block一个编号,称之为BlockID,通过BlockID,能够确定Block的顺序
-
同一个Block的不同副本一定是在不同节点上,但是不同Block的副本可能在一个节点上
-
Block的意义:为了能够存储超大文件,为了进行快速备份
-
-
NameNode
-
NameNode是HDFS的核心节点,用于管理DataNode以及存储元数据
-
元数据主要包含:文件的存储路径,文件权限,文件大小以及块的大小,BlockID,Block的存储节点,副本数量
-
NameNode会将元数据存储在内存以及磁盘中,存储在内存中的目的是为了快速查询,存储在磁盘中的目的是为了崩溃恢复
-
元数据的存储路径由hadoop.tmp.dir来决定
-
元数据的存储文件:edits:记录写操作的文件,fsimage:映像文件。记录元数据,但是这个文件中的元数据和内存中的元数据并不是同步到,fsimage中的元数据往往是落后于内存中的元数据
-
NameNode在接收到写操作的时候,先将这个操作记录到edits_inprogress文件中,如果记录成功,则更改内存中的元数据,内存中的元数据更改成功之后会给客户端返回成功信号。这样设计的目的是为了保证操作的可靠 - 只要记录成功了,这个操作就一定会执行
-
当fsimage进行更新的时候,将edits文件中的操作一一取出重新执行到fsimage中。此时edits_inprogress文件会滚动成edits文件,同时生成一个新的edits_inprogress用于记录新的操作
- fsimage更新/edits滚动的触发条件:
- 空间:当edits文件达到指定大小(默认是64M,这个大小可以通过fs.checkpoint.size --- core-site.xml来调节)的时候,会触发edits文件的滚动
- 时间:当距离上次滚动间隔指定时间(默认是3600s,这个时间可以通过fs.checkpoint.period来调节)之后,会触发edits文件的滚动
- 重启:当NameNode重启的时候,会触发edits文件的滚动
- 强制:通过hadoop dfsadmin -rollEdits命令来强制edits文件滚动
-
DataNode会通过心跳机制来向NameNode注册管理 - DataNode会定时的发送心跳信息给NameNode
-
DataNode会每隔3s给NameNode发送一次心跳 - 心跳是通过RPC机制发送
- 心跳信息:
- 当前DataNode中的Block信息
- 当前DataNode的状态(预服役、服役、预退役)
-
NameNode如果在10min没有收到DataNode的心跳,则认为这个DataNode已经lost,会将这个节点上的数据备份放到其他节点上保证整个集群中的副本数量
- NameNode重新启动之后,进行fsimage文件的更新/edits文件的滚动,将fsimage文件中的内容加载到内存中,等待DataNode的心跳,如果在指定的时间内没有等到心跳,则认为这个DataNode已经丢失需要对应处理;如果等到了心跳,那么NameNode对DataNode的数据进行校验,校验DataNode中的数据和元数据的记录是否一致,如果校验失败,则会试图恢复这个数据- 这个过程称之为安全模式(safe mode)。恢复之后,会再次校验,如果校验成功则自动退出安全模式并且对外提供服务;如果校验失败则重新恢复重新校验
-
在安全模式中,HDFS集群只对外提供读服务
-
也正因为有安全模式的校验问题,所以要求副本数量不能多于节点数量
-
如果在合理的时间内,集群没有自动退出安全模式,那么可能就已经产生了数据丢失并且这个数据不可恢复
-
强制退出安全模式:hadoop dfsadmin -safemode leave
-
-
副本放置策略
- 第一个副本:
- 如果是集群内部上传,谁上传第一个副本就在谁身上
- 如果是集群外部上传,则第一个副本会放在相对空闲的节点上
- 第二个副本:
- 在Hadoop2.7之前,第二个副本是放在和第一个副本不同机架的节点上
- 从Hadoop2.7开始,第二个副本是放在和第一个副本相同机架的节点上
- 第三个副本:
- 在Hadoop2.7之前,第三个副本是放在和第二个副本相同机架的节点上
- 从Hadoop2.7开始,第三个副本是放在和第二个副本不同机架的节点上
-
更多副本:谁闲放在谁身上
- 第一个副本:
-
机架感知策略
-
所谓的机架不是物理机架而是逻辑机架,本质上就是一个映射
-
可以将不同物理机架的节点映射到同一个逻辑机架上
-
实际过程中会将同一个物理机架上的节点去映射到同一个逻辑机架上
-
-
DataNode
-
存储Block
-
DataNode会给NameNode发送心跳
-
存储Block的路径也是由hadoop.tmp.dir属性来指定
-
-
SecondaryNameNode
-
SecondaryNameNode并不是NameNode的备份,这个节点的作用辅助NameNode完成edits文件的滚动
-
在完全分布式中,一旦出现SecondaryNameNode,则edits文件的滚动是在SecondaryNameNode上进行;如果没有SecondaryNameNode,则edits文件的滚动由NameNode自己完成
-
在HDFS集群中,只能采取NameNode+SecondaryNameNode结构或者是双NameNode结构。因为SecondaryNameNode的作用可以被NameNode取代,但是NameNode作为核心节点如果只有1个容易出现单点故障,所以实际过程中往往会舍弃SecondaryNameNode采用双NameNode结构来构成NameNode的HA
-
-
回收站机制
-
HDFS中的回收站机制默认是不开启的
-
-
DFS目录
- dfs目录是在NameNode格式化的出现的
- in_use.lock用于标记当前节点已经开启了对应进程
- HDFS在第一次启动的时候,1min之后会自动进行一次edits文件的滚动
- 在HDFS中,会对每一次的写操作分配一个全局递增的编号,编号称之为事务id - txid
- 在HDFS中,将开始记录日志和结束记录日志看作是一个写操作 - 每一个edits文件的开头和结尾都是OP_START_LOG_SEGMENT和OP_END_LOG_SEGMENT
- 上传文件:
- OP_ADD:在HDFS上创建一个文件名_.COPYING_文件
- OP_ALLOCATE_BLOCK_ID:分配BlockID
- OP_SET_GENSTAMP_V2:设置时间戳编号
- OP_ADD_BLOCK:给文件添加块 - 上传数据
- OP_CLOSE:关流/关闭文件
- OP_RENAME_OLD:重命名
- 文件在上传完成之后不能修改
- md5文件是为了防止fsimage文件被篡改的,对fsimage文件进行校验的
- VERSION:
- clusterID - 集群编号。在NameNode格式化的时候自动计算产生的,也就意味着NameNode每格式化一次,clusterID就会重新计算。NameNode会将clusterID分发给每一个DataNode,DataNode也只接收一次。NameNode和DataNode之间的每一次通信都会携带这个clusterID
- blockpoolID:块池编号
- 联邦HDFS:
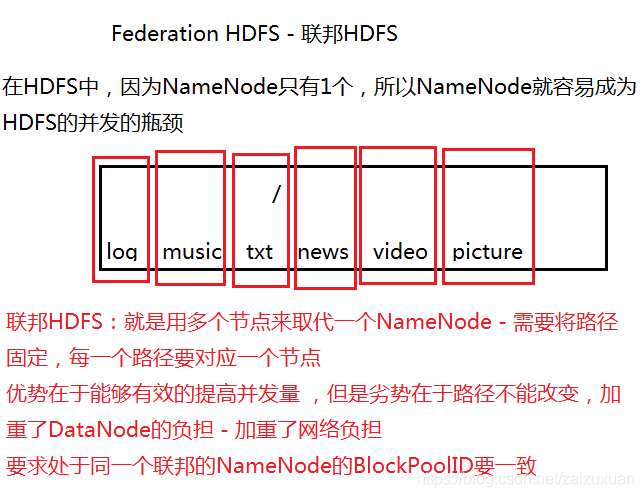
- 流程
- 读取流程/下载
- 客户端发起RPC请求到NameNode
- NameNode收到请求之后会校验这个文件是否存在
- 如果文件存在,NameNode给客户端一个信号
- 客户端就会向NameNode要第一个Block的地址
- NameNode在收到请求之后会读取元数据,然后将第一个Block的地址放入队列中返回给客户端
- 客户端收到队列之后从中选择一个较近的节点来读取第一个Block,读取完成之后,会对这个Block进行checksum的验证;如果校验失败,客户端会给NameNode一个信号然后重新选取地址重新读取;如果校验成功,则客户端会向NameNode要第二个Block的地址,重复4.5.6过程
- 客户端读取完成所有的Block之后,会给NameNode一个结束信号。 NameNode在收到信号之后会关闭文件
- 写入流程/上传
- 客户端发起RPC请求到NameNode
- NameNode在接收到请求之后会进行校验:
- 校验指定路径是否存在
- 校验写入路径是否有权限
- 校验指定路径中是否有同名文件
- 如果校验失败,则抛出异常;如果校验成功,记录元数据,NameNode会给客户端一个信号
- 客户端在收到信号之后会向NameNode要第一个Block的存储位置
- NameNode在收到请求之后,会等待DataNode的心跳,选取DataNode的地址放入队列中返回给客户端。默认情况下,NameNode会选择3个地址
- 客户端收到队列中取出3个地址,从这些地址中选择一个较近(拓扑距离短)的节点写入第一个Block的第一个副本
- 第一个副本所在节点会通过pipeline(管道,实际上就是NIO中的Channel)将第二个副本写到其他节点上,第二个副本所在的节点再写第三个副本
- 写完之后,第三个副本所在的节点会给第二个副本所在的节点返回ack,第二个副本所在的节点收到ack之后会给第一个副本所在的节点返回ack,第一个副本所在的节点再给客户端返回ack
- 写完第一个Block之后,客户端会和NameNode要第二个Block的存储位置,然后重复5.6.7.8过程
- 当写完所有的Block之后,客户端会给NameNode一个结束信号,NameNode就会关闭文件/关流,文件关闭之后,这个文件就不可修改
- 删除流程:
- 客户端发起RPC请求到NameNode
- NameNode在收到请求之后,会将这个请求记录到edits文件中,然后更新内存中的元数据,内存更新成功之后会客户端返回一个ack信号,此时这个文件对应的Block依然存储在DataNode
- 在NameNode收到DataNode的心跳的时候,NameNode就会检查Block信息,会给DataNode进行心跳相应,要求删除对应的Block。DataNode在收到心跳相应之后才会真正删除Block
- 读取流程/下载
-
- MapReduce
- 概述
-
MapReduce是Hadoop提供的一套用于进行分布式计算的框架
-
将计算过程拆分为2个阶段:Map(映射)阶段和Reduce(规约)阶段
-
MapReduce在对文件进行计算的时候,会将文件进行切片,切片和切块不一样,每一个切片对应MapTask,默认情况下,每一个MapTask在拿到切片之后会进行按行读取按行处理
-
-
组件:
-
序列化:
- 在MapReduce中,要求数据能够被序列化
- MapReduce的序列化机制默认采用的AVRO
- MapReduce对AVRO的序列化机制进行了封装,提供了更简便的序列化形式 - 实现接口Writable
- 分区-Partition
- 分区的作用是将数据进行分类
- 有无分区并不影响Map和Reduce的执行逻辑
- 分区默认是从0开始依次递增的
- 在MapReduce中,每一个分区要对应一个ReduceTask,默认情况下只有1个分区,也就只有1个ReduceTask,只产生一个结果文件
- 排序:
- 在MapReduce中,自动对键进行排序
- 要求键所对应的类必须实现Comparable接口,但是考虑到键需要序列化,所以一般实现的WritableComparable
- 在排序过程中,如果compareTo方法的返回值为0,则MapReduce会认为这两个键是同一个,则将这两个键的值放到一组,相当于去重过程
- 合并-Combine
- 大多数情况下,MapTask的数量要远远多于ReduceTask的数量,导致计算压力几乎全部落在了ReduceTask上,ReduceTask的计算效率就成为整个MapReduce的瓶颈
- 合并的逻辑和Reducer的逻辑是一样的 - 只需要在Driver中添加job.setCombinerClass(Reducer.class);
- 合并的特点:减少数据总量但是不改变计算结果
- 如果进行汇总、获取最值、去重之类操作可以使用Combiner,但是例如求平均之类的操作不能使用Combiner
-
-
- 细节:
- 数据本地化策略
- 当JobTracker收到MR程序的时候,会访问NameNode获取文件信息。文件信息包含文件大小以及块信息
- JobTracker对这个文件进行切片处理。注意:切片是逻辑切分不是物理切分。切片数量决定了MapTask的数量。默认情况下,Split和Block是等大的
- JobTracker会将划分出来的MapTask分配到TaskTracker上执行
- 因为MapTask在执行过程中需要读取数据,而数据在DataNode上,所以将DataNode和TaskTracker部署在相同的节点上以减少跨集群的网络传输
- 为了减少网络资源的消耗,在分配任务的时候会考虑Block的位置。哪个节点上有要处理的数据,将任务分配给哪个节点,这个过程称之为数据本地化
- 切片产生过程:
- 如果文件为空,则整个文件作为一个切片处理
- 在MapReduce中,文件要区分可切或者不可切,例如绝大部分的压缩文件就是不可切的
- 如果文件不可切,则整个文件作为一个切片处理
- 如果需要减小splitsize,需要调小maxsize;如果需要调大splitsize,需要调大minsize
- 在计算切片的时候,需要考虑切片阈值 - SPLIT_SLOP = 1.1
- MR执行流程
- 准备阶段:
- 检查输入和输出路径
- 计算切片数量
- 如果有必要,设置缓存存根
- 将jar包和配置上传到HDFS上
- 将任务提交给JobTracker,并且可以选择是否监控这个任务
- 执行阶段:
- JobTracker收到Job任务之后,会将这个任务进行拆分,拆分成MapTask和ReduceTask。MapTask的数量由切片决定;ReduceTask的数量由分区数量决定
- JobTracker在拆分完成任务之后,会等待TaskTracker的心跳,然后给TaskTracker分配任务。分配任务的时候,MapTask尽量满足数据本地化策略,ReduceTask无法满足数据本地化,所以ReduceTask在分配的时候是考虑节点的空闲
- TaskTracker通过心跳领取任务,领取到任务之后,会去对应节点上下载jar包,这一步体现的思想是逻辑移动数据固定
- TaskTracker会在本节点上开启JVM子进程执行MapTask或者ReduceTask。注意:每一个MapTask或者ReduceTask的执行都会开启一次JVM子进程
- 准备阶段:
- 数据本地化策略
- 细节:
-
- Shuffle
- Map端的Shuffle
- map方法在处理完成数据之后会将结果写出到MapTask自带的缓冲区中 - 每一个MapTask自带一个缓冲区 - MapOutputCollector
- 数据在缓冲区中进行分区、排序,如果指定了Combiner,那么数据在缓冲区中还会进行combine。注意:在缓冲区中的排序是将完全无序的数据整理成有序数据,采取的是快速排序
- 缓冲区是维系在内存中,默认是100M
- 当缓冲区的使用达到一定限度(溢写阈值:0.8)的时候,会将缓冲区中的数据溢写(spill)到磁盘上,map方法后续产生的结果会继续写到缓冲区中
- 每一次溢写都会产生一个新的溢写文件 - 单个溢写文件中的数据是分区且有序的,所有的溢写文件之间是局部有序的
- 在map方法完成之后,将所有的溢写文件进行合并(merge),将所有的溢写文件合并成一个结果文件(final out),在merge过程中,数据会再次进行分区排序 - final out是整体分区且有序的。merge过程中的排序是将局部有序变成整体有序,所以采用的是归并排序
- 如果map方法执行完成之后,缓冲区中依然有数据,则会直接合并到最后的final out中
- 在merge过程中,如果spill文件个数>=3并且指定了Combiner,则在merge的时候会再进行一次combine
- 注意问题:
- spill过程不一定产生
- 默认情况下,溢写文件的大小不一定是80M,考虑序列化因素
- 缓冲区本质上是一个环形的字节数组,设置为环形的目的是为了避免寻址,能够重复利用缓冲区
- 阈值的作用是为了减少写入的阻塞
- Reduce端的Shuffle
- ReduceTask启动多个fetch线程去MapTask处抓取对应分区的数据
- ReduceTask将从每一个MapTask上抓取过来的数据存储在一个本地文件中
- 将抓取来数据进行一次merge,合并成一个大文件,在merge过程中,会再次进行排序,采用的是归并排序
- merge完成之后,ReduceTask会再将相同的键对应的值放到一个迭代器中,这个过程称之为分组(group)
- 分组完成之后,每一个键对应一个迭代器,每一个键调用一次reduce方法
- 注意问题:
- ReduceTask的启动阈值:0.05 - 当5%的MapTask结束,就会启动ReduceTask去抓取数据
- fetch线程通过HTTP请求获取数据
- fetch线程的数量默认为5
- merge因子:10 - 每10个小文件合并成1个大文件
- Shuffle的调优
- 减少溢写次数:
- 增大缓冲区,实际过程中缓冲区的大小一般是在250~400M之间
- 增大缓冲区阈值,同时增加了写入阻塞的风险 - 不建议
- 增加Combine的过程
- 可以考虑将Map的结果文件进行压缩,这个方案是在网络资源和CPU资源之间的取舍
- 增加fetch线程的数量
- 增大merge因子,会增加底层计算的复杂度 - 不建议
- 减小ReduceTask的启动阈值,增加了ReduceTask的阻塞风险 - 不建议
- 减少溢写次数:
- Map端的Shuffle
- Shuffle
- InputFromat
- 概述
- InputFormat中定义了2个抽象方法:
- getSplits用于产生切片
- createRecordReader产生输入流读取切片
- InputFormat会把结果给到MapTask
-
- 实际过程中,如果需要自定义输入格式类,一般不是直接继承InputFormat而是继承它的子类FileInputFormat,这个子类中已经覆盖了getSplits方法,而只需要考虑如何读取数据即可
- 如果没有指定输入格式,那么默认使用的TextInputFormat。除了第一个切片对应的MapTask意外,其余的MapTask都是从当前切片的第二行开始读取到下一个切片的第一个行
- 多源输入下,允许输入不同格式的文件,但是文件格式可以不同Mapper类也可以不一样,但是最后交给Reducer处理的时候要一样
- InputFormat中定义了2个抽象方法:
- 概述
- 其它细节
- 数据倾斜
- 数据本身就有倾斜特性,即日常生活中所产生的数据本身就是不均等的
- 实际过程中,绝大部分的数据倾斜都会产生在Reduce端
- Map端产生倾斜的条件:多源输入、文件不可切且文件大小不均 - Map端的倾斜一旦产生无法解决 - 如果真的要解决,在特定条件下可以考虑缓存存根问题
- Reduce端的倾斜的本质是因为数据的倾斜性,但是直观原因是因为对数据进行了分类 - 分类规则往往是不可变的,所以在实际过程中往往考虑的是使用两阶段聚合 - 数据先打散后聚合
- 小文件
- 小文件的危害:
- 存储:大量小文件会产生大量的元数据,就导致内存被大量占用
- 计算:大量小文件就产生大量的切片,大量切片则意味着有大量的MapTask,会导致服务器的执行效率变低甚至会导致服务器崩溃
- 针对小文件的处理手段常见的有2种:合并和压缩
- Hadoop提供了一种原生的合并手段:Hadoop Archive,将多个小文件打成一个har包
- 小文件的危害:
- 数据倾斜
- 概述
- Yarn
- 概述:
- 产生原因:
- 内因:Hadoop1.0中,JobTracker既要负责任务调度和监控还要负责集群的资源管理,任务比较多,就导致任务量增多的时候效率成倍下降甚至崩溃、
- 外因:随着Hadoop以及分布式的发展,产生了越来越多的计算框架,这些框架之间的资源分配容易产生冲突,所以需要提供一套统一的资源分配的框架
- YARN - Yet Another Resource Negotiator--- 迄今另一个资源调度器
- Yarn负责资源管理和任务调度
- ResourceManager:资源管理
- ApplicationMaster:任务管理
- NodeManager:执行任务
- 产生原因:
- Job的执行流程
- 客户端将Job提交给ResourceManager
- ResourceManager在收到Job任务之后会等待NodeManager的心跳
- 在ResourceManager收到NodeManager的心跳之后会将Job交给这个NodeManager,同时在这个NodeManager上开启一个ApplicationMaster,将Job分配给这个ApplicationMaster - 在Yarn中,每一个Job任务会对应一个单独的ApplicationMaster
- ApplicationMaster收到Job之后会对这个Job进行划分,划分好之后会向ResourceManager请求执行资源。请求的资源数量要考虑副本数量。例如,如果一个任务划分成5个MapTask以及2个ReduceTask,那么默认情况下在申请资源的时候会申请17份资源,但是注意ResourceManager会只返回7份资源
- ResourceManager收到请求之后会将资源封装成Container对象发送给ApplicationMaster
- ApplicationMaster收到Container之后会对资源进行二次分配,分配给具体的子任务
- ApplicationMaster会将子任务分发给NodeManager执行,并且会监控这些任务的执行情况。每一个ApplicationMaster只监控自己的任务,不监控其他的ApplicationMaster的任务
- 当子任务执行失败的时候,这个子任务所占用的资源也会被释放。ApplicationMaster在监控到这个任务失败的时候会试图重启这个子任务,在重启之前,ApplicationMaster会向ResourceManager重新为这个子任务来申请资源
- 注意:
- 在Yarn体系结构中,ResourceManager管理ApplicationMaster,ApplicationMaster管理子任务
- 默认情况下,每份资源中包含1G内存一个1个CPU核,即允许每一个子任务占用1G内存以及1个CPU核
- 概述: