java高并发之Zookeeper
Zookeeper
zookeeper是开源的分布式的协调服务框架,是apache Hadoop的子件,适用于绝大部分分布式集群的管理。
分布式的业务操作会引发如下几个关键问题:
死锁:至少有一个线程占用的资源,但是不占用cpu。
活锁:所有线程都没有把持资源,但是线程却是不断地调用占用CPU。
需要引入一个管理节点。
为了防止入口的单点问题,需要引入管理节点的集群。
需要在管理阶段中选举出一个主节点。
需要确定一套选举算法。
主节点和从节点之间要保证数据的一致。
Zookeeper的单机版安装
zookeeper可以安装在linux下,也可以安装在Windows中,但是官网声明了在Windows中zookeeper不保证稳定性。
1.关闭Linux的防火墙
临时关闭:service iptables stop
永久关闭:chkconfig iptables off
2.下载安装jdk,zookeeper一般要求jdk为1.6以上
3.下载zookeeper安装包tar
4.解压安装包:tar -zxvf zookeeper-x.x.x.tar.gz
5.进入zookeeper的安装目录的conf目录:cd zookeeper-x.x.x/conf
6.将zoo_sample.cfg复制为zoo.cfg:cp zoo_sample.cfg zoo.cfg
7.zookeeper在启动的时候会自动加载zoo.cfg,从里面读取配置信息,需要修改zoo.cfg,将其中的dataDir指定为你要存放的数据路径,要求此路径是存在的,没有需要创建目录。
8.进入zookeeper-x.x.x/bin目录,启动服务端: sh zkServer.sh start
9.启动客户端:sh zkCli.sh
注意:
zookeeper返回started不代表启动成功,可以通过jps或者是sh zkServer.sh status来查看是否启动成功。如果使用的是jps,查看是否有quorumPeerMain。如果使用的是status命令,查看是否有Mode:standalone.
当zookeeper启动之后,在bin目录下会出现zookeeper.out文件,记录zookeeper的启动过程的日志文件。
zookeeper的特点
1.本身是一个树状结构:Znode树。
2.每一个节点称之为znode节点。
3.根节点是/
4.zookeeper的所有操作都必须以根节点为基准进行计算
5.每一个znode节点都必须存储数据
6.任意一个持久节点都可以有子节点
7.任意一个系欸但那的路径都是唯一的
8.znode树是维系在内存中:目的是为了快速查询
9.zookeeper不适合存储海量数据:
维系在内存中,如果存储大量数据会耗费内存。
不是一个存储框架而是一个服务协调框架
10.zookeeper会为每一次事务(除了读取以为的所有操作都是事务)分配一个全局的事务id:Zxid
zookeeper的命令
1.create /node1 “hello zookeeper” 在根节点下创建子节点node1并赋值为hello zookeeper
2.set /node1 “hi” 将node1的数据更新为 hi
3.get /node1 获取node1的数据
4.ls / 查看根节点下的所有子节点
5.delete /node1 删除子节点node1,要求node1节点中没有子节点
6.rmr /node1 删除node1及其子节点
7.quit退出
8.create -e /node1 " 表示在根目录下创建临时节点node1
9.create -s /node1 " 表示在根目录下创建持久顺序节点 node100000000X
10.create -e -s node1 " 表示在根目录下创建临时顺序节点 node100000000X
zookeeper的节点类型
1.持久节点
2.临时节点:在客户端退出之后就自动删除
3.持久顺序节点
4.临时顺序节点
zookeeper的节点信息
1.cZxid 全局分配的创建的事务id
创建这个节点是zookeeper的第n个操作,定义好之后就不变了
2.ctime 创建时间
3.mZxid 修改的事务id
记录自己本身修改
4.mtime 修改时间
5.pZxid 表示子节点的变化的事务id
记录直接子节点的创建或者删除
6.cversion 记录子节点变化次数
7.dataVersion 数据版本
记录当前节点的数据的变化次数
8.aclVersion acl版本
记录当前节点的acl变化次数
9.ephemeralOwner
如果当前节点不是临时节点,那么这个属性的值为0;如果是临时节点,那么这个属性的值记录的是当前临时节点的session id。
10.dataLength 数据长度
实际上是字节个数
11.numChildren 子节点个数
zookeeper的api操作(java实现)
连接操作
@Test
public void connect() throws IOException, InterruptedException{
CountDownLatch cdl = new CountDownLatch(1);
// connectString - 连接地址+端口号
// sessionTimeout - 会话超时时间 - 表示连接超时时间,单位默认为毫秒
// watcher - 监控者 - 监控连接状态
// Zookeeper本身是一个非阻塞式连接
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181", 5000, new Watcher() {
// 监控连接状态
public void process(WatchedEvent event) {
if(event.getState() == KeeperState.SyncConnected){
System.out.println("连接成功~~~");
}
cdl.countDown();
}
});
cdl.await();
}
创建节点
@Test
public void create() throws KeeperException, InterruptedException {
// path - 节点路径
// data - 数据
// acl - acl策略
// createMode - 节点类型
// 返回值表示节点的实际路径
String str = zk.create("/node01", "hello,zookeeper".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
System.out.println(str);
}
删除节点
@Test
public void delete() throws InterruptedException, KeeperException {
// path - 节点路径
// version - 数据版本
// 在删除节点的时候回比较指定的数据版本和节点的实际数据版本是否一致
// 如果一致则删除,如果不一致则放弃该操作
// zk.delete("/node04", 0);
// -1表示强制执行
zk.delete("/node04", -1);
}
更新数据
@Test
public void set() throws KeeperException, InterruptedException{
// path - 节点路径
//data - 数据
// version - 数据版本
// 返回节点信息
Stat s = zk.setData("/node02", "hi,zk".getBytes(), -1);
System.out.println(s);
}
获取数据
@Test
public void get() throws KeeperException, InterruptedException, UnsupportedEncodingException {
// path - 节点路径
// watch - 监控
// stat - 节点信息
Stat s = new Stat();
byte[] data = zk.getData("/node01", null, s );
System.out.println(new String(data, "utf-8"));
}
判断节点是否存在
@Test
public void exist() throws KeeperException, InterruptedException{
// path - 节点路径
// watch - 监控者
// 返回的节点的信息
Stat s = zk.exists("/node07", null);
System.out.println(s);
}
获取子节点
@Test
public void getChidren() throws KeeperException, InterruptedException {
// path - 节点路径
// watch - 监控者
// 返回子节点的路径
List<String> nodes = zk.getChildren("/" ,null);
for (String p : nodes) {
System.out.println(p);
}
}
监听节点数据变化
@Test
public void dataChanged() throws KeeperException, InterruptedException {
CountDownLatch cdl = new CountDownLatch(1);
// 获取的是监听之前的数据
// 获取数据和监听变化实际上是两个线程
byte[] data = zk.getData("/node01", new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == EventType.NodeDataChanged)
System.out.println("节点数据发生变化~~~");
cdl.countDown();
}
}, null);
cdl.await();
System.out.println(new String(data));
}
监听子节点变化
@Test
public void childChanged() throws KeeperException, InterruptedException {
CountDownLatch cdl = new CountDownLatch(1);
zk.getChildren("/node01", new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == EventType.NodeChildrenChanged)
System.out.println("子节点产生变化~~~");
cdl.countDown();
}
});
cdl.await();
}
监听节点变化
@Test
public void nodeChanged() throws KeeperException, InterruptedException {
CountDownLatch cdl = new CountDownLatch(1);
zk.exists("/node06", new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == EventType.NodeCreated)
System.out.println("这个节点被创建~~~");
else if (event.getType() == EventType.NodeDeleted)
System.out.println("这个节点被删除~~~");
cdl.countDown();
}
});
cdl.await();
}
zookeeper的集群安装
1. 关闭防火墙
2. 安装jdk
3. 下载Zookeeper的安装包
4. 解压Zookeeper的安装包
5. 进入Zookeeper的安装目录中conf目录
6. 将zoo_sample.cfg复制为zoo.cfg
7. 编辑zoo.cfg,修改dataDir属性:
dataDir=/home/software/zookeeper-3.4.8/tmp
server.1=127.0.0.1:2888:3888 # 1是编号,要求每一个节点的编号是数字且不重复;
server.2=127.0.0.2:2888:3888 #2888,3888是端口号,只要不和已经占用的端口号冲突即可
server.3=127.0.0.3:2888:3888
8. 创建存储数据的目录
9. 进入数据存储目录
10. 编辑文件myid, 将当前机器的编号写到myid中
11. 将配置好的Zookeeper的安装目录拷到其他集群主机中:scp -r zookeeper-3.4.8 127.0.0.2:/home/software/
根据指定的编号修改对应的myid
在Zookeeper集群中,单独启动一台主机是不对外提供服务的
Zookeeper在使用过程中,会进行选举,选举出主节点-leader,其他的节点就会成为从节点-follower
zookeeper的选举
第一阶段:数据恢复阶段
会从数据目录(dataDir)中恢复数据
第二阶段:选举阶段
1.所有的节点都会推荐自己当leader并且发送自己的选举信息(最大事务id:pZxid,编号:myid,逻辑时钟值)
2.选举原则:先比较最大事务id,谁的事务id大谁就胜出;如果最大事务id一样,则比较myid,谁的myid大谁就胜出。
3.选举出的leader的胜出要满足过半性:即要比至少一半的节点大
4.如果在集群中新加入一个节点,节点的事务id比leader 的事务id大,新的节点也不会成为新的leader,只要选定了一个leader,那么后续节点的事务id和myid无论是多少,一律都是follower。
5.如果leader宕机,集群中会自动选举一个新的leader。
如果超一半的服务器宕机,那么此时zookeeper不再对外提供服务—zookeeper的过半性。
节点的状态
looking 选举状态
follower 追随者
leader 领导者
observer 观察者
Zookeeper的投票是ZAB协议。ZAB是2PC协议的基础上来进行的延伸。
2PC:将节点分为了协调者和参与者。当来一个请求的时候,协调者是将请求分发给每一个参与者,如果所有的参与者决定执行这个请求,那么协调者就真正提交操作,有参与者执行,参与者在执行完成之后返回Ack表示执行成功。如果协调者将请求分发给每一个参与者之后,有一个或者多个参与者不同意执行或者是没有返回消息,那么将这个操作回滚,不执行 — 一票否决
在Zookeeper中,接收一个请求之后,leader会将请求分发给每一个节点,由所有的节点投票确定是否执行这个请求 — 如果有超过一半的节点同意执行这个请求,那么这个时候leader才会决定执行这个操作。
过半性:
1. 选举leader的要满足过半性
2. 请求操作也要满足过半性
3.过半集群才能对外提供服务 — 防止脑裂 — 脑裂:集群中产生2个及以上的leader — 一般将集群节点设置为奇数
观察者
执行操作,但是不参与选举和投票。
21个节点 14个观察者 6个follower以及1个leader
如果12个观察者宕机,依然对外提供服务
4个follower宕机,不对外提供服务
观察者不参加投票,所以就不影响集群的运行状态(一般适用网络不稳定的情况)
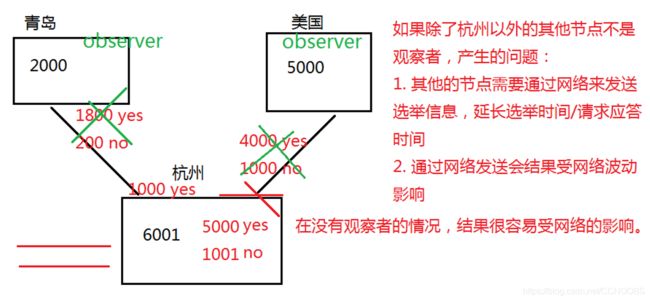
找到要设置为观察者的主机,编辑zoo.cfg,添加:peerType=observer,再在要设置的主机之后添加observer标记。
例如:server.3=127.0.0.3:2888:3888:observer,然后重新启动这一个节点