数据结构笔记(持续更新)
因为最近上网课,不得不重新回到C++的怀抱,就顺便整理一下笔记内容,希望方便自己复习的同时也能方便觉得无法理解的同伴们,笔芯(以及我其实不是鸽子,咕)
教材使用的是清华大学出版社的严蔚敏先生编写的《数据结构(C语言版)》,会按照章节整理,但是肯定不是按照目录顺序,因为觉得总分的学习顺序不太合适,一切以例子优先,会插入一些曾经遇到过的编程题方便大家理解(当然我本人竞赛很菜,但是大佬们的代码都有写出来,我可以放链接)
不出意外的话是每周更新2-3次
以上
第一章 绪论
首先,先接触一个词,算法,望文生义一下,这就是让运算变容易的方法。举个例子,就像是从1加到100,可以一个一个加,也可以分组做加法(1+100)+(2+99)+(3+98)+……,这样运算就变得容易了。
最容易想到的算法就是排序问题,比如冒泡排序、快速排序、选择排序、插入排序等等(我就曾经学过这几个)
我们正常的排序就是人眼比较大小,但是电脑没有眼睛,所以正常比较就只能一个一个比较大小(或者直接sort函数)
简单介绍一个排序,其他的欢迎大家自己探索:
冒泡排序
思想很简单,就是依次比较相邻数据的大小,按照规定的大小顺序排序。从大到小或者从小到大排序都可以,全看怎么写了。
#include
using namespace std;
int main()
{
int a[12]={2,8,1,34,45,4,19,67,78,9,5,23};
int temp=0;
for(int i=0;i<(sizeof(a)/sizeof(a[0]));i++)
{
for(int j=(sizeof(a)/sizeof(a[0]));j>0;j--)
{
if(a[j] 输出:
1
2
4
5
8
9
19
23
34
45
67
78
Process returned 0 (0x0) execution time : 0.375 s
Press any key to continue.
找一个中间变量temp,比较两个数的大小,在第一个循环里第,12个和第11个比较大小,如果第12个比第11个小,就把第12个数给临时变量,再把第11个数给第12个数,最后把临时变量给第11个数,这就完成了交换。
2,8,1,34,45,4,19,67,78,9,5,23
先看5和23,5<23,所以顺序不变;再比较9和5,9>5,所以交换两个数的位置,数列变成2,8,1,34,45,4,19,67,78,5,9,23;然后是5和78比较,以此类推。如果需要从大到小输出,可以:1.逆序输出;2.在第二个for循环内改变if条件。
所谓程序就是算法加上数据结构,那么数据结构是什么?
本章基本上是名词介绍,会在后面遇到的时候再提,这样有例子方便理解。
第二章 线性表
本章主要是抽象的概念,比如:线性表的N中存储结构。本来不想在这里展开,也准备跳过,但是考虑到方便理解,在这里提一下。数据存储的时候是什么样子呢?
对于单个数据来说,每个数据可以认为是住在一间小房间里的,他的室友是一个标志位置的指针,对于一堆数据而言就像是小区的住户,他们有自己独特的地址:住在哪个小区,哪栋楼,哪一层,哪一间都是规定好的,如果我们没有规定,那么他自己也有规则。所以我们在找数据的时候就像快递小哥哥,拿着地址找到数据的位置。指针可以理解成地址,储存数据时还会顺便存储一下地址,方便我们找到一家之后又去找下一家拿数据。
第三章 栈和队列
前面讲了那么多都不如直接看这里emmmm
首先,明确栈和队列是两种东西,区别在于栈是后进先出(LIFO),队列是先进先出(FIFO)。
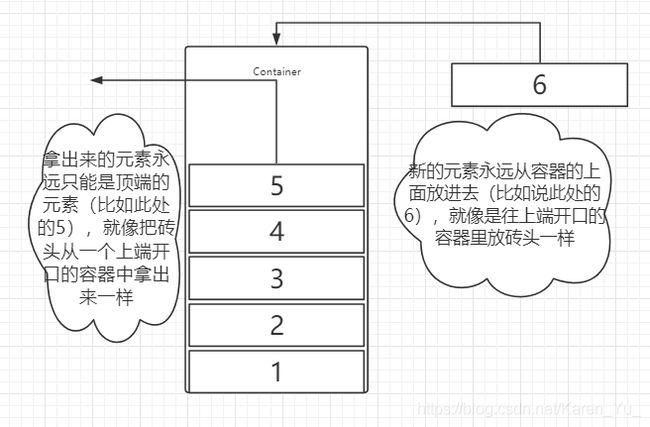
图例(栈)

图例(队列)
然后这里放一个曾经用过的网站,如果自己不想写栈或者队列,C++也提供了可供我们选择使用的容器和使用方法,不过似乎现在被墙了?大家翻翻吧,不翻也无所谓emmmm。
http://www.cplusplus.com/
最常见的或者说最简单的栈的运用就是判断是否是回文。比如“asdffdsa”就属于回文,有点轴对称的意思,大家意会一下,不过多解释了。
我们先看一下,如果不用栈怎么解决这个问题。
首先,回文,就是说这个字符串是对称的,那么理所当然,这个字符串的正序和倒序是完全一样的,所以,最直接的思路就是将字符串倒置,然后比较是否与原字符串一致。代码如下:
#include
#include
using namespace std;
int main()
{
string str1,str2;
str1="abxjdldshss";
//str1="zealaez";
str2=str1;
reverse(str1.begin(), str1.end());
if(str1==str2)
cout<<"YES\n";
else
cout<<"No\n";
return 0;
} 输出:
No
#include
#include
using namespace std;
int main()
{
string str1,str2;
//str1="abxjdldshss";
str1="zealaez";
str2=str1;
reverse(str1.begin(), str1.end());
if(str1==str2)
cout<<"YES\n";
else
cout<<"No\n";
return 0;
} 输出:
YES
正经题目:
Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same backward as forward.
Example 1:
Input: 121
Output: true
Example 2:
Input: -121
Output: false
Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome.
Example 3:
Input: 10
Output: false
Explanation: Reads 01 from right to left. Therefore it is not a palindrome.
Follow up:
Coud you solve it without converting the integer to a string?
题目来源:https://leetcode.com/problems/palindrome-number/
解析:https://www.cnblogs.com/jiading/p/10425425.html
回文字符串判定解析:https://blog.csdn.net/nancynancylu/article/details/79568225
使用容器判断(这里就简单写了,如果需要输入或者有什么别的需求改一下就OK了)
#include
#include
using namespace std;
int main()
{
stack mystack;
for (int i='a';i<'f';i++)
mystack.push(i);
char a[]={'e','d','c','b','a'};
while(!mystack.empty())
{
for(int i=0;i<5;i++)
{
if(mystack.top()==a[i])
{
mystack.pop();
continue;
}
else if(!mystack.top()==a[i])
{
mystack.pop();
cout<<"false\n";
break;
}
}
cout<<"true\n";
}
return 0;
} 输出:
true
有关结构体的补充
简单来说就是自己定义的数据类型。
#include
using namespace std;
struct now
{
string a;
int year,month,day;
};//定义结构体
int main()
{
now date={"K_Y",2020,3,18};
cout< 输出:
K_Y
2020
3
18
2020/3/18
更多内容看这里http://c.biancheng.net/view/1407.html
最近另一门课刚好用的是MATLAB,老师也敲好讲到结构数组,故也在此补充一下(内容由老师提供的讲义截取,我本省也不太记得这里了,顺便复习一下):
单元和结构
可将不同类型数据用花括号合成一个单元数组(Cell Array):
>> a=[1,2,3;4,5,6];b='hello';c=[];d=int32([1+2i -i]);
>> A={a,b;c,d}
A =
[2x3 double] 'hello'
[] [1x2 int32]
用圆括号引用单元数组返回单元数组,花括号引用单元数组返回单元数组的元素:
>> a=A(1,:) % a是1x2的单元数组
a =
[2x3 double] 'hello'
>> a=A(1,1) % a是1x1的单元数组(以矩阵为元素)
a =
[2x3 double]
>> b=a{1} % b是a的第一个元素,即矩阵
b =
1 2 3
4 5 6
>> a=A{1,1} % a是2x3的矩阵
a =
1 2 3
4 5 6
>> A{1,1}(2,:) % A{1,1}是一个矩阵,故可以用圆括号引用其元素
ans =
4 5 6
相应地可用下面两种方式修改单元值:
>> A(1,2)={[0;1;2]}; A{2,2}=[0.1 -2 3i 0]
A =
[2x3 double] [3x1 double]
[] [1x4 double]
用cell创建空单元数组:
>> A=cell(2,3)
A =
[] [] []
[] [] []
可将不同类型数据合成一个结构(Struct),它的每个成员称为域(Field),这与C语言中的Struct是一样的。下面生成有三个域(name、ID、score)的结构:
>> student=struct('name','Zhang San','ID',3,'score',90)
student =
name: 'Zhang San'
ID: 3
score: 90
当域的取值是单元数组(Cell Array)时生成相同维度的结构数组(Struct Array):
>> student=struct('name',{'A','B';'C','D'},'ID',{1,2;3,4},'score',{91,80;90,73})
student =
2x2 struct array with fields:
name
ID
score
用.引用域:
>> student(2,1).name
ans =
C
可用rmfield删除域:
>> student1=rmfield(student,'ID')
student1 =
2x2 struct array with fields:
name
score
结构也可作为单元数组的元素:
>> a=[1 2;3 4];b='hello';c=[];A={a b;c student}
A =
[2x2 double] 'hello'
[] [2x2 struct]
单元数组也可作为结构的域:
>> a=[1 2;3 4];b='hello';c=[];d=[1+2i -i];A={a b;c d};
>> sc.name='struct with cell'; sc.c=A
sc =
name: 'struct with cell'
c: {2x2 cell}
好像还有一个火车进站问题,但是我找不到之前做题的网站了,找到之后贴到这里。
破案了,是Poj的题目,蛊惑大家都去Poj刷题啊(自己的名字跟大佬挂在一起的难得的机会,而且AC很爽)
题目链接:
http://poj.org/problem?id=1363
解析:
http://www.voidcn.com/article/p-hzvlvyxj-bsc.html
https://blog.csdn.net/blue_skyrim/article/details/47862095
好啦,栈的举例到此为止,接下来就是一些基本的操作。
除了上面提到的#include
栈:http://data.biancheng.net/view/169.html
顺序栈:http://data.biancheng.net/view/170.html
链栈:http://data.biancheng.net/view/171.html




以上为书本内容,书上还有其他举例,比如检查括号,走迷宫之类的,但是我觉得搜索还是放在图论那里比较合适。还有就是汉诺塔,我记得原来写的时候还去4399上快乐的玩了一会。感兴趣可以在http://so2.4399.com/search/search.php?k=%BA%BA%C5%B5%CB%FE上挑一个长得好看的,自己玩玩,然后试着理解游戏逻辑,要求输出每步的步骤,三个柱子可以用123或者ABC代替,写出步骤比如(A->B)这样,这个游戏妙就妙在每次只能拿一个(就是最顶端的那个)。
(2020/4/2补充)刚刚看到一个讲汉诺塔递归特别清楚的博客,附上链接https://blog.csdn.net/qq_41705423/article/details/82025409
还有一个JAVA的构造,因为个人没学过JAVA,所以我也没看太明白,先Mark一下https://www.cnblogs.com/mcomco/p/10108694.html
和栈类似,栈有栈顶,队列有队头和队尾,有点类似某种小时候用的铅笔:

例子暂时想不出来,先空着。
//cplusplus举例
#include // std::cout
#include // std::queue
//这个网站似乎不喜欢命名空间
int main ()
{
std::queue myqueue;//基本上和栈的构造没区别
//因为是已经内置好的存储器,如果自己写要严格遵守先进后出
myqueue.push(77);
myqueue.push(16);//入队
myqueue.front() -= myqueue.back(); // 77-16=61//队头减队尾
std::cout << "myqueue.front() is now " << myqueue.front() << '\n';
return 0;
} 输出:
myqueue.front() is now 61
好啦,例子来了,POJ 2259http://poj.org/problem?id=2259
题解:https://blog.csdn.net/zproud/article/details/80516994
有关题目的理解,先看一下样例输入和样例输出:
样例输入——
2//队列数量为2
3 101 102 103//队伍1的情况,队里有3个人
3 201 202 203//队伍2的情况,队里有3个人
ENQUEUE 101//在队列中输入101,应该放在队伍1,而且在队首,要是弹出应该第一个出去
ENQUEUE 201
ENQUEUE 102
ENQUEUE 202
ENQUEUE 103
ENQUEUE 203
DEQUEUE//队首出队
DEQUEUE//队首出队
DEQUEUE//队首出队
DEQUEUE//队首出队
DEQUEUE//队首出队
DEQUEUE//队首出队
STOP
样例输出——
Scenario #1//编号
101
102
103
201
202
203
刚刚试一下为了方便理解,可以另外举一个例子:
输入: 输出:
2
3 1 2 3
3 11 12 13 Scenario #1
ENQUEUE 1 1
ENQUEUE 11 1
ENQUEUE 1 1
ENQUEUE 12 1
ENQUEUE 1 1
ENQUEUE 13 11
ENQUEUE 1 12
ENQUEUE 11 13
ENQUEUE 1 11
DEQUEUE
DEQUEUE 队伍1和队伍2可以理解成标签?按照标签将
DEQUEUE 元素分类存放,然后按照顺序出队
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
STOP



优先队列:
POJ2010http://poj.org/problem?id=2010(最近POJ不知道为什么总要挂VPN才能进)
题目:
Moo University - Financial Aid
| Time Limit: 1000MS | Memory Limit: 30000K | |
| Total Submissions: 14471 | Accepted: 4300 |
Description
Bessie noted that although humans have many universities they can attend, cows have none. To remedy this problem, she and her fellow cows formed a new university called The University of Wisconsin-Farmside,"Moo U" for short.
Not wishing to admit dumber-than-average cows, the founders created an incredibly precise admission exam called the Cow Scholastic Aptitude Test (CSAT) that yields scores in the range 1..2,000,000,000.
Moo U is very expensive to attend; not all calves can afford it.In fact, most calves need some sort of financial aid (0 <= aid <=100,000). The government does not provide scholarships to calves,so all the money must come from the university's limited fund (whose total money is F, 0 <= F <= 2,000,000,000).
Worse still, Moo U only has classrooms for an odd number N (1 <= N <= 19,999) of the C (N <= C <= 100,000) calves who have applied.Bessie wants to admit exactly N calves in order to maximize educational opportunity. She still wants the median CSAT score of the admitted calves to be as high as possible.
Recall that the median of a set of integers whose size is odd is the middle value when they are sorted. For example, the median of the set {3, 8, 9, 7, 5} is 7, as there are exactly two values above 7 and exactly two values below it.
Given the score and required financial aid for each calf that applies, the total number of calves to accept, and the total amount of money Bessie has for financial aid, determine the maximum median score Bessie can obtain by carefully admitting an optimal set of calves.
Input
* Line 1: Three space-separated integers N, C, and F
* Lines 2..C+1: Two space-separated integers per line. The first is the calf's CSAT score; the second integer is the required amount of financial aid the calf needs
Output
* Line 1: A single integer, the maximum median score that Bessie can achieve. If there is insufficient money to admit N calves,output -1.
Sample Input
3 5 70
30 25
50 21
20 20
5 18
35 30
Sample Output
35
Hint
Sample output:If Bessie accepts the calves with CSAT scores of 5, 35, and 50, the median is 35. The total financial aid required is 18 + 30 + 21 = 69 <= 70.
Source
USACO 2004 March Green
题解:https://www.cnblogs.com/UniqueColor/p/4771541.html
第四章 串
基本上就是字符串,我记得有关字符串的就是查找啊、找子串啊这种好像曾经做过一个是先规定一个单词,然后输入脸滚键盘输入一堆字符,然后判断是否含有这个单词。最无脑不计较时间复杂度和空间复杂度的方法就是按照单词的顺序依次查找,比方说,我要找apple,那我就先找a,然后判断a的下一位是不是p,不是的话再继续找p。
代码如下(好傻的写法,不要介意):
#include
using namespace std;
int main()
{
string st=("appusbyinuixapplebeonmiajuzgnglappleamoeuinocpix");
char a[48];
strcpy(a,st.c_str());
for (int i=0;i<48;i++)
{
if(a[i]=='a'&&a[i+1]=='p'&&a[i+2]=='p'&&a[i+3]=='l'&&a[i+4]=='e')
{
cout< 输出:
13
32
好了,这不是重点,重点是KMP算法。
如果不是上面那种情况,我们拿到的是两个字符串,然后我们要判断是否有包含关系,最基本的解题思路就是,找两个小箭头,先都指向连个字符串的首位字符,判断是否相等,如果相等,那么,两个小箭头,再向右移一位,判断是否相等:

(图源B站数据结构课程https://www.bilibili.com/video/BV1db411Y7Lm?p=12)
如果相等,继续上述操作,不相等,则i回溯到第二位,j回溯到第一位再进行比较,以此类推,如图:

最大的问题在于确定next,比如有写的很好的博客
https://blog.csdn.net/dark_cy/article/details/88698736
还有知乎相关https://zhuanlan.zhihu.com/p/83334559(动图方便理解)
我简单谈谈自己的看法(反正我们这门课开卷哈哈哈)
暴力求解无非就是两个字符串分别对应一个循环,两个循环来来回回查找,问题最大的在于回溯指针的问题,所以只要简化回溯过程就可以达到目的。
在匹配字符串的时候,当然有两个字符串,其中一个长一点的(或者一样长的其中一个,因为判断是否为子串至少字符串的长度得不比子串短)称为文本串,另一个需要匹配的称为模式串。暴力求解即依次比较模式串和文本串中字符是否相等,相等继续比较,不相等则,模式串退回第一位,文本串退回本次比较中的第二位再比较这两个指针对应的字符。
但是其实模式串的指针可以不退回第一位。
因为进过匹配,指针之前经过的部分都确定是与文本串的指针之前走过的部分是一样的。(在不谈怎么写的情况下,个人觉得这个的图片做的最通俗易懂https://www.sohu.com/a/336648975_453160)
而KMP算法的核心就在于每次匹配时,给字符串重新标号的过程,其中模式串的指针不再需要回溯了。我最初的理解误区在于没想到模式串是已知的(当然得是已知的,要找东西当然得知道自己在找什么才有用)。
图源:https://www.zhihu.com/question/21923021

简单解释一下最大匹配数的问题。
子字符串 a b a b a b z a b a b a b a第一位 a,没人跟他重复,所以标0,第二位是b,a和b显然不匹配(一样),也标0。
第三位是a,这时候就和第一位匹配(重复)了,标1.
第四位是b,这时,有ab和ab,两位匹配,标2
第五位是a,有a(第一位)b(第二位)a(第三位)和 a(第三位)b(第四位)a(第五位)三位重复,所以标3。
第六位是b,此时有a(1)b(2)a(3)b(4)和a(3)b(4)a(5)b(6)四位重复,标4。
求next[](图源https://blog.csdn.net/qq_37969433/article/details/82947411)

第五章 数组和广义表
第六章 树和二叉树
先写这个!关于树的遍历(这是我不太熟悉的部分,我甚至想直接跳过这里去写图论emmmm)
一些概念:根结点,叶子结点,度,深度,完全二叉树,满二叉树。理解即可。https://blog.csdn.net/bingfeilongxin/article/details/88422192
https://blog.csdn.net/weixin_41931540/article/details/88957425
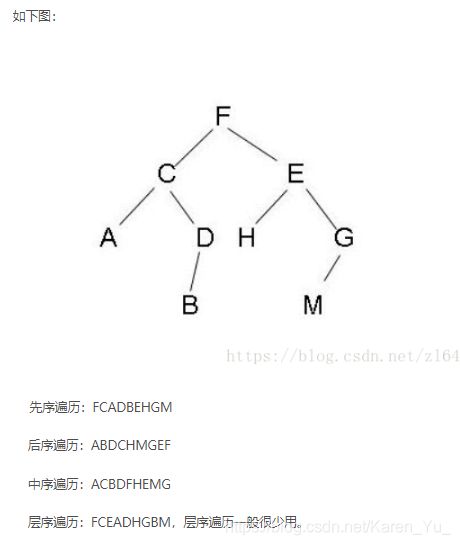
(1)先序遍历:先访问根节点,再访问左子树,最后访问右子树。
(2) 后序遍历:先左子树,再右子树,最后根节点。
(3)中序遍历:先左子树,再根节点,最后右子树。
图源https://blog.csdn.net/zl6481033/article/details/81009388
老师在上课的时候提到了用递归做,参考之前在栈那里补充的汉诺塔,思想类似,就是:找到最后一步,再往后退一步,看一下倒数第二步长什么样子,有点类似于逆推(要想得到X,要先有Y,要想先有Y,要有条件W……),就是套娃思想。
然后我在自己操作的时候,又卡在结构体那里了(主要是指针)。
有关结构体可以看一眼这个https://www.cnblogs.com/lanhaicode/p/10312032.html
#include
using namespace std;
typedef struct test
{
int num;
int add;
}teacher;
/*个人理解,test和teacher都是这个结构体的名字,只不过有点类似于test是这个结构体的大名,有名有姓,
是单独称呼后面的名字(显得亲密),还是叫全名(即:struct 某某某,比较正式)都没有问题。
但是teacher在这里类似于这个结构体的外号,我们都知道孙悟空可以叫弼马温,
但是没人叫他孙弼马温的道理。*/
int main()
{
//test la={20,1};
//struct test la={20,1};
//teacher la={20,1};
/*以上三个句子效果一致,输出的都是20*/
cout< 在构造二叉树的时候也用的结构体,方便把数据和指针放一起:
typedef struct BiTNode{
TElemType data;//数据域
struct BiTNode *lchild,*rchild;//左右孩子指针
}BiTNode,*BiTree;
来源:
https://blog.csdn.net/bingfeilongxin/article/details/88422192注意在这里不能直接写作
typedef struct BiTNode{
TElemType data;//数据域
BiTNode *lchild,*rchild;//左右孩子指针
}BiTNode,*BiTree;因为BiNode在花括号内还没有声明。
当然,这种写法并不是必须的(不一定要用typedef,也不一定要取别名)
还看到有用类写的,但是类太麻烦了,子子孙孙私有公有的。
用递归写树的遍历看起来就真跟套娃一样emmmm
有关树的遍历,补充一题:
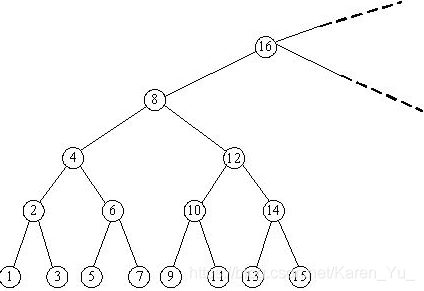
题目:http://http//poj.org/problem?id=2309
大体意思就是输入一个数,然后输出如果以这个数为他所在子树的根结点,那么他管辖的那些个叶子上标号的最小值和最大值是什么?,比如,如果是4,那么最小就是1,最大就是7。
题解:https://www.cnblogs.com/oimonster/p/4349107.html
https://www.xuebuyuan.com/2107080.html
//《数据结构编程实验》P244页。解法很巧妙。
#include
using namespace std;
int lowbit(int x){
return x & -x;
}
int main()
{
int n,x;
cin>>n;
while (n--){
cin>>x;
cout< 大概就讲讲二叉树红黑树霍夫曼树叭(曾经开始划水就是因为树emmmm学不会)
原来其实树我做的挺少的,刚看到深度优先和广度优先遍历的时候还以为是图论emmmm,果然曾经背锅图论让我中毒太深了orz

广度优先有点类似水滴滴到水面上,涟漪依次向外扩张(图源https://baike.baidu.com/item/ripples/397071)
深度优先类似于正常人走迷宫,先一条路走到黑,不行再退回去。
介绍:https://www.jianshu.com/p/bff70b786bb6(搜索)
python:https://blog.csdn.net/best_od/article/details/86314577
C++:https://www.cnblogs.com/jayinnn/p/9559415.html
红黑树算是一种弱平衡二叉树,https://blog.csdn.net/isunbin/article/details/81707606
在平衡二叉树旋转的时候可以理解为将多余的部分和根结点连接,断掉原本连着的线,然后转个圈。(为了看懂代码,还要求掌握链表和结构体,结构体上面有很多链接,链表:https://www.cnblogs.com/lanhaicode/p/10304567.html)
刚刚看到POJ2010可能是红黑树?等我下次看看。(好的,感觉不像)
个人理解红黑树似乎是为了查找/排序服务的,有点像二分的样子,相当于手动给数据分类排序,方便查找时按照既定的规律找到需要的数据。
POJ3481:http://poj.org/problem?id=3481
题解:https://blog.csdn.net/weixin_34355715/article/details/94616857
https://www.bbsmax.com/A/kjdwwK7rdN/
据说set是自带的红黑树,那么就……完美,直接带入好了(说到这个,我们学长好像之前一直不给我们用STL,天天逼着我们手动写,自闭),好像更多是分类成平衡树,不过这个无所谓。
Sample Input Sample Output
2//开始执行操作2,队伍中没人,输出0 0
1 20 14//把20放在14号位 20
1 30 3//把30放在3号位 30
2//执行操作2,输出优先级高的——20 10
1 10 99//把10放在99号位 0
3//输出优先级低的——30
2//输出优先级高的——10
2//队伍空了,输出0
0//停止
霍夫曼树:https://www.iteye.com/blog/cake513-1184529
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。(百度百科)
这样听起来很像最短路径问题,比如Floyd和Dijkstra,这是之前常用的解决最短路径的算法,记忆里都是用邻接矩阵?而且每次做这种题的时候我都满脑子贪心啊,动态规划啊这种想法,总觉得最短路径就是贪心emmmm
POJ3253http://poj.org/problem?id=3253
题解:https://blog.csdn.net/qq_40421671/article/details/83274031
(可以简单理解为锯木头,每锯一次木头都要支付一定的钱。)
Hint
He wants to cut a board of length 21 into pieces of lengths 8, 5, and 8.
The original board measures 8+5+8=21. The first cut will cost 21, and should be used to cut the board into pieces measuring 13 and 8. The second cut will cost 13, and should be used to cut the 13 into 8 and 5. This would cost 21+13=34. If the 21 was cut into 16 and 5 instead, the second cut would cost 16 for a total of 37 (which is more than 34).
话说,这道题我有别的想法,按照道理,这道题可以先把长度加起来,再排序,除了最长的一块木板,再把其他长度加一遍,让我去试一下。
WA了……看起来不能偷懒……好像POJ不支持万能头文件……会CE,知道问题在哪里了,是我想太简单了……看题解看题解。
第七章 图
Dijkstra's algorithm - 迪杰斯特拉算法
先看例题,然后再看介绍。
POJ3255题目:http://poj.org/problem?id=3255
样例输入:
4 4//N R,起点在1,终点在N,有R条双向路径
1 2 100//1到2或2到1的长度是100
2 4 200
2 3 250
3 4 100
样例输出:
450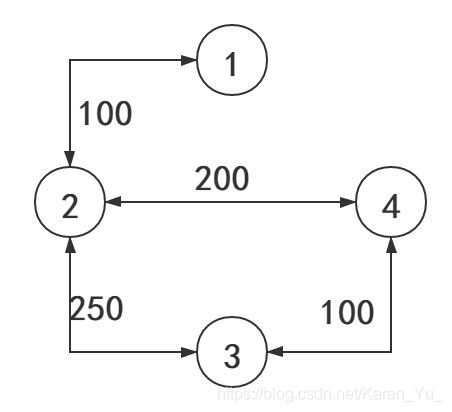
题解:https://blog.csdn.net/weixin_44756457/article/details/98455499
https://blog.csdn.net/hcx11333/article/details/81271519
说是求次短路,但其实也就是求最短路的变形。
算法:https://blog.csdn.net/swustzhaoxingda/article/details/84318570
https://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html
明确:1.图的顶点依次加入集合
2.每次加入的顶点都只记录从源点到该顶点的最短路径(比如从A到B有两条路,一条从A直接到B,路径长度为6,一条从A先到C,路径长度为3,然后由C到B,路径长度为2;则此时,从A到B的最短路径为A->C->B,那么我们就记这一条为最短路径,再添加顶点进来的时候,也是加到这条路径后面,图片参考如下,图源)
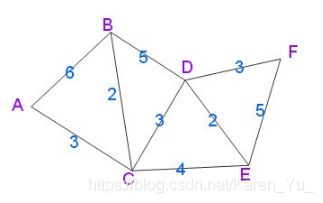
3.加入的顺序由源点直接到各顶点的距离决定(直接意味着不用经过其他顶点,所以先处理的是C的原因就是由A到BCDEF顶点的距离中最近的就是C)
Floyd-Warshall算法
(题外话,突然想起来之前我一直管这俩叫迪士尼算法和弗洛伊德算法?)
POJ1125题目:http://poj.org/problem?id=1125
题解两种方法均可(D&F):https://blog.csdn.net/zzc2227372/article/details/84604319
DFS和BFS
在理解这两个算法之前要先明确邻接矩阵和邻接表
邻接矩阵https://blog.csdn.net/zzc2227372/article/details/84604319
邻接表https://www.cnblogs.com/icode-girl/p/5273209.html
其实本质上我个人认为邻接表和邻接矩阵区别不大,只是因为邻接矩阵比较稀疏时,用邻接表比较方便。
广度优先搜索(breadth-first search,BFS)
题目POJ3278:http://poj.org/problem?id=3278
题解:https://blog.csdn.net/sinat_22659021/article/details/41902811
一开始我看了半天都觉得不像BFS,后来才发现估计是以前做的都是二维或者三维的,乍一碰到一维的我总觉得是贪心。(我做题就是万物都像贪心,叹气)
下面这道题好像曾经做过,一开始布置的是二维的BFS,然后一碰到三维的,我又懵了,完完全全思维僵化,或者可以理解为当时就是没有理解所以在移动那里套板子,怎么都想不起来在x和y后面加一个z的移动。
POJ2251:http://poj.org/problem?id=2251
/*代码引用自:
https://www.cnblogs.com/litaotao/p/3592462.html*/
#include
#include
#include
#include
using namespace std;
typedef struct
{
int x,y,z;
int n;
}Point;//结构体,x,y,z三个方向移动
int dir[6][3]={-1,0,0,1,0,0,0,-1,0,0,1,0,0,0,-1,0,0,1};
//六行三列的二维数组,六种移动方式,x/y/z分别前进或者后退,如下:
/* x y z
-1 0 0
1 0 0
0 -1 0
0 1 0
0 0 -1
0 0 1
*/
char map[31][31][31];//题目限定了每一层地图的长宽不超过30,此为记录地图的数组
int l,r,c,ans,flag[31][31][31];
//标记矩阵flag
int Judge(int x,int y,int z)//判断,没跑出圈,或者理解为确定迷宫边界
{
if(x>=0 && x=0 && y=0 && z q;//STL中的队列 Point是前面结构体的“绰号”
Point p0,p1,p2;
memset(flag,0,sizeof(flag));//特别常用的初始化函数,每次用到数组基本上都写这个初始化
p0.x=x;p0.y=y;p0.z=z;p0.n=0;//xyz和n都是结构体里的元素
flag[x][y][z]=1;
q.push(p0);
while(!q.empty())
{
p1=q.front();q.pop();
for(int i=0;i<6;i++)
{
int temp1=p1.x+dir[i][0];
int temp2=p1.y+dir[i][1];
int temp3=p1.z+dir[i][2];//开始探路,各方向都可以走
if(Judge(temp1,temp2,temp3) && !flag[temp1][temp2][temp3] && map[temp1][temp2][temp3]!='#')
//这里是每次都不一样的部分,这里的意思是:1.没走出迷宫;2.没标记过;3.没走到石头上
{
if(map[temp1][temp2][temp3]=='E'){
ans=p1.n+1;return;//找到出口啦!
}
p2.x=temp1;p2.y=temp2;p2.z=temp3;p2.n=p1.n+1;//n计时
flag[temp1][temp2][temp3]=1;//走过了,标记
q.push(p2);
}
}
}
}
int main(){
//freopen("input.txt","r",stdin);<-这里应该是原作者测试的部分,不过我还是不习惯用emmmm
int i,j,k,si,sj,sk;
while(~scanf("%d%d%d",&l,&r,&c))
{
if(l==0 && r==0 && c==0) break;
//结束条件
for(i=0;i 关于算法:https://www.cnblogs.com/cs-whut/p/11147348.html
https://blog.csdn.net/raphealguo/article/details/7523411
(虽然,但是,其实基本上就是套板子的题型)