基于Inception v3进行多标签训练
本文是基于github上开源代码multi-label-Inception-net(链接为https://github.com/BartyzalRadek/Multi-label-Inception-net)上给出的多标签训练模型进行多标签训练的实例,关于该文章的链接为:http://arxiv.org/abs/1512.00567
一.下载github开源代码
1.将所有训练图像放在一个文件夹中,并在项目根目录中创建一个包含所有可能标签的文件labels.txt。例如:
![]()

2.需要为每个图像准备正确标签的文件。命名文件

3.最终你需要将图片文件夹,标签文件夹,以及标签txt存放在同一个目录中,如下:其中images为装满图片的文件夹,labels.txt为所有的标签,model_dir文件夹里面为所有图片的标签,retrain.py为训练的脚本。
![]()
二 获取数据库
本实验采用的是南京大学开源的数据库,数据库链接为: 点击这里查看,下载后解压会出现两个压缩包,一个压缩包中含有上图所示的图片,共有2000张自然风景图,这些图片总攻有5个标签(desert,mountains,sea,sunset,trees),而每张图片都含有至少一个标签,这就是我们的训练样本,但是我们可以发现另一个名为processed压缩包里含有的是一个minl data的mat文件,这个需要使用matlab打开,打开之后可以看出其中具有三个矩阵,名字分别为bags.mat,targets.mat,class_name.mat,第一个可以直接忽略,而第二个就是每张图像所给的定义,如下,第三个class_name.mat中含有总的标签数。
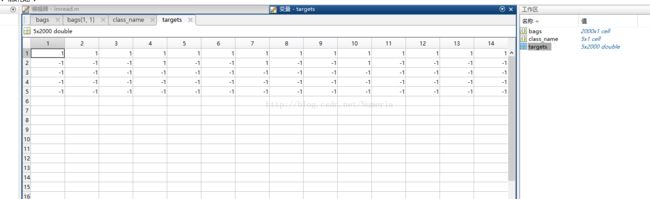
可以看出来每一列为一张图片的标签定义,1表示有,-1表示没有,例如第一张图片为[1 -1 -1 -1 -1],就表示改图片只包含第一个标签”desert“,我们现在需要将这个tagets.mat矩阵转换成txt文件。
2.1将mat文件转换成txt文件脚本
本文先通过网上所述的方法修改:
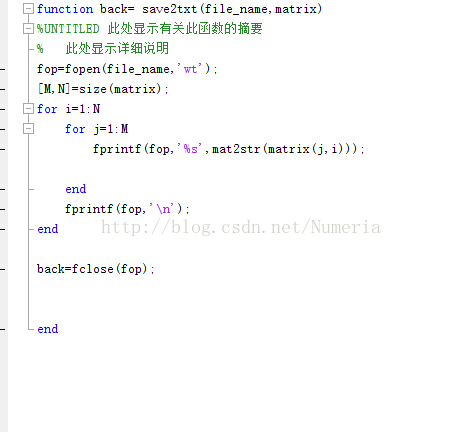
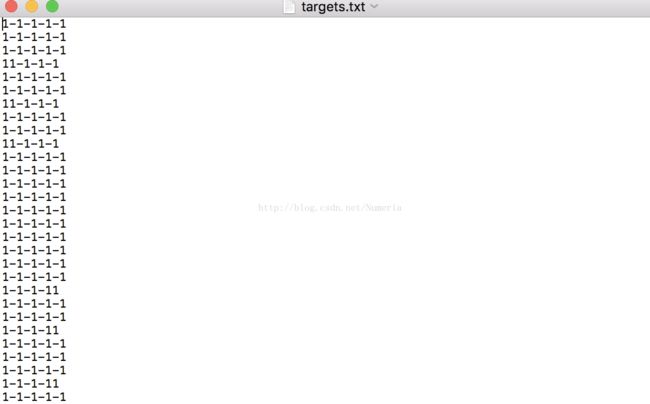
结果发现输出来的txt是乱码,后来对网上另一个mat2txt脚本进行修改最终得出了结果:下图为修改后的脚本以及最后的txt文件。
2.2txt转换成标签
我们可以看出得到的target.txt文件显示的是一系列的字符,我们需要通过这个txt文件将每一行对应与一个图像的标签,这时我们需要使用python编写的脚本:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 16 22:56:24 2017
@author: hongjun
"""
from __future__ import division
#写入文件,将msg列表中的每一个元素换行写入文件,并修改文件的名字
def text_create(name, msg):
desktop_path = '/Users/hongjun/Desktop/test/'
full_path = desktop_path + name + '.jpg.txt'
file = open(full_path,'w')
for i in range(len(msg)):
label=msg[i]
file.write(label+'\n')
file.close()
print('Done')
f=open("/Users/hongjun/Desktop/targets.txt",'r')
while 1:
lines=f.readlines()#逐行读取整个文件
n=1#n表示读入的第几行
for line in lines:
if line:
#字符字典,数字表示负号前面有多少个1,例如0就对应没有1即字符desert
total_labels={0:"desert",1:"mountains",2:"sea",3:"sunset",4:"trees"}
output_labels=[]#最终输出的列表
numbers=line.split('1')#将每行按照1进行分开
label_count=[]#每个负号前面有多少个1的列表
for i in range(len(line)):
if line[i]=="-":
count=0#表示某个特定的负号前面的1的个数
for j in range(0,i):
if line[j]=='1':
count=count+1
label_count.append(count)#与if line[i]=='-'为同一缩进
for i in range(0,5):
if i not in label_count:#如果输出的列表中不存在字典里的数字,那么就代表存在某个字符
output_labels.append(total_labels[i])
text_create(str(n),output_labels)
n=n+1
else:
break
f.close()
docker run -it \
--publish 6006:6006 \
--volume ${HOME}/image_labels_dir:/image_labels_dir \
--workdir /image_labels_dir \
tensorflow/tensorflow:1.1.0 bash
tensorboard --logdir training_summaries &如果当你运行上一条命令时出现:
这条命令行是在关闭所有正在运行的tensorboard,然后你可以再运行tensorboard --logdir training_summaries &来启动tensorboard。现在有了容器,有人训练模型,有了数据,我们可以开始训练了,下面给出训练时候要用到的参数:
python retrain.py \
--bottleneck_dir=bottlenecks \
--model_dir=model_dir \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--summaries_dir=retrain_logs \
--image_dir=images至此,训练就可以开始了。注意,一定要保证images路径是对的,否则无法进行训练,以我为例可以看到根目录下有image_labels_dir文件夹,其中含有4个主要的文件images(图片),retrain.py()(为重训练脚本),labels.txt(所有的标签),image_labels_dir(所有图像的标签),而在images文件夹下有个image文件夹,这文件夹中含有所有的图片。
root@c4fff66f82bc:/image_labels_dir# ls
bottlenecks image_labels_dir images labels.txt model_dir retrain.py retrain_logs retrained_graph.pb retrained_labels.txt
root@c4fff66f82bc:/image_labels_dir# ls
bottlenecks image_labels_dir images labels.txt model_dir retrain.py retrain_logs retrained_graph.pb retrained_labels.txt
root@c4fff66f82bc:/image_labels_dir# cd images
root@c4fff66f82bc:/image_labels_dir/images# ls
image
root@c4fff66f82bc:/image_labels_dir/images# cd image
root@c4fff66f82bc:/image_labels_dir/images/image# ls
1.jpg 1085.jpg 1171.jpg 1258.jpg 1344.jpg 1430.jpg 15四.训练时候存在的问题
本人使用的python2.7进行运行,由于tensorflow版本问题,会出现一些问题:
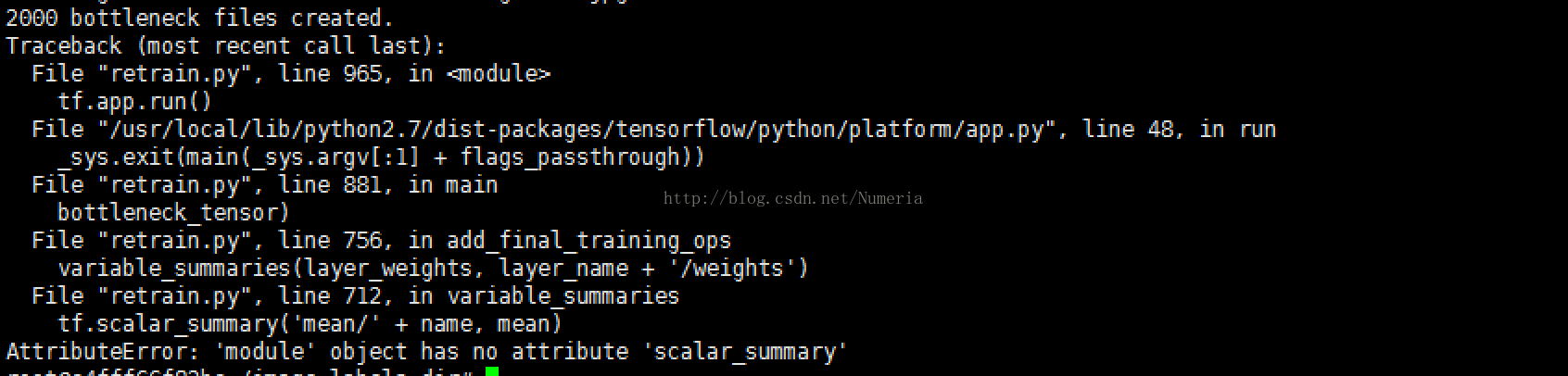
解决的方法是对retrain.py文件进行一些修改:
1报错位置:.tf.scalar_summary('batch_loss', loss)AttributeError: 'module' object has no attribute 'scalar_summary'修改为:tf.summary.scalar('batch_loss', loss)原因:新版本做了调整
2.AttributeError: 'module' object has no attribute 'histogram_summary'修改为:tf.summary.histogram
3.tf.merge_all_summaries()改为:summary_op = tf.summaries.merge_all()
4.AttributeError: 'module' object has no attribute 'SummaryWriter':tf.train.SummaryWriter改为tf.summary.FileWriter
以及另一处报错位置的修改:tf.nn.sigmoid_cross_entropy_with_logits(logits,ground_truth_input)
修改为
tf.nn.sigmoid_cross_entropy_with_logits(labels=ground_truth_input,logits=logits)五训练结果
按照上述方法,我们可以得到最终的训练结果,迭代次数为默认的4000次,我们可以得知最终的训练准确率为94.6%,测试准确率为93.8%,以及交叉熵为0.144610.
2017-06-23 03:16:08.463792: Step 3980: Train accuracy = 93.4%
2017-06-23 03:16:08.463873: Step 3980: Cross entropy = 0.152843
2017-06-23 03:16:08.514183: Step 3980: Validation accuracy = 94.6%
2017-06-23 03:16:09.090858: Step 3990: Train accuracy = 93.4%
2017-06-23 03:16:09.090932: Step 3990: Cross entropy = 0.164133
2017-06-23 03:16:09.140161: Step 3990: Validation accuracy = 95.8%
2017-06-23 03:16:09.600402: Step 3999: Train accuracy = 94.0%
2017-06-23 03:16:09.600477: Step 3999: Cross entropy = 0.144610
2017-06-23 03:16:09.650267: Step 3999: Validation accuracy = 93.8%
Final test accuracy = 94.6%
接下来我们用这个训练结果测试一下单个照片:
我们需要用到label_image.py脚本,输入的命令行为
python label_image.py images/image/400.jpg
我们可以观测到最终的输出为:
desert (score = 0.97425)
sunset (score = 0.10365)
mountains (score = 0.01996)
sea (score = 0.01231)
trees (score = 0.00555)

mountains (score = 0.82342)
desert (score = 0.60081)
sea (score = 0.05774)
trees (score = 0.01539)
sunset (score = 0.01115)