静态代码审计工具Cobra/Cobra-W/find-sec-bugs
8.4更新
cobra关键解析流程:
## cli.py
-》start
scan_engine(target_directory=target_directory, a_sid=a_sid, s_sid=s_sid, special_rules=pa.special_rules,
language=main_language, framework=main_framework, file_count=file_count, jar_count=jar_count, extension_count=len(files))
## engine.py
-》scan_engine
pool.apply_async(scan_single, args=(target_directory, single_rule), callback=store)
-》scan_single
SingleRule(target_directory, single_rule).process()
-》process
origin_results()
-》
origin_results
使用find/grep等系统工具进行匹配
7.16更新
mybatis框架中#{变量}对应JDBC中的预编译机制,不存在SQL注入漏洞,${变量}对应SQL语句拼接方式,存在SQL注入风险。
普通owasp漏洞:找敏感方法触发点;
通用软件:找pom.xml,进行解析
https://www.anquanke.com/post/id/84511
Mybatis框架下易产生SQL注入漏洞场景分析:
- 模糊查询like:
Select * from news where title like ‘%#{title}%’,
但由于这样写程序会报错,研发人员将SQL查询语句修改如下:
Select * from news where title like ‘%${title}%’,
- in之后的参数
Select * from news where id in (#{id}),
但由于这样写程序会报错,研发人员将SQL查询语句修改如下:
Select * from news where id in (${id}),
- order by之后
Select * from news where title =‘京东’ order by #{time} asc,
但由于发布时间time不是用户输入的参数,无法使用预编译。研发人员将SQL查询语句修改如下:
Select * from news where title =‘京东’ order by ${time} asc,
修改之后,程序通过预编译,但是产生了SQL语句拼接问题,极有可能引发SQL注入漏洞。
现有静态代码审计工具
之前童话师傅写过一篇Cobra静态代码审计工具的源码分析,所以先看看这个工具吧。
源码在:
https://github.com/WhaleShark-Team/cobra
后来还有Lo写的一个改版:
https://github.com/LoRexxar/Cobra-W
-
Find Security Bugs
这个只是提供给IDE的插件。其测试用例可以作为参考。 -
Fortify:不开源。
-
RIPS:只开源了PHP版本,Java的是商业版本。
参考:https://en.wikipedia.org/wiki/RIPS -
PMD:
参考:https://pmd.github.io/
https://github.com/pmd/pmd
感觉还比较新,最近一年刚出来。
不过主要是做编码规范的,不是找漏洞的那种。 -
spotbugs:
也是编码规范的。
Cobra
跟一下流程:
根据传入的target,若未提供sid,则调用get_sid()新建一个sid。(根据这里的逻辑分支可以看出,如果某次任务退出了,下次可以通过命令行提供这个sid以继续之前的任务?)
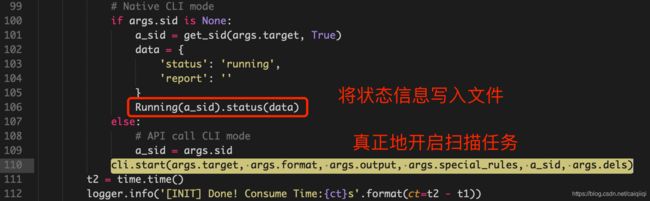
Running(a_sid).status(data)
这一句是把状态信息写入到target对应的文件中。
即便target一样,由于有随机数的存在,所以每次get_sid的结果是不一样的:

new一个Running实例,然后将状态以字典的形式传入status函数。
这里学习到了如何给正在打开的文件加锁的方式:
import fcntl
fcntl.flock(f, fcntl.LOCK_EX)
参考:https://blog.51cto.com/zhou123/1650185
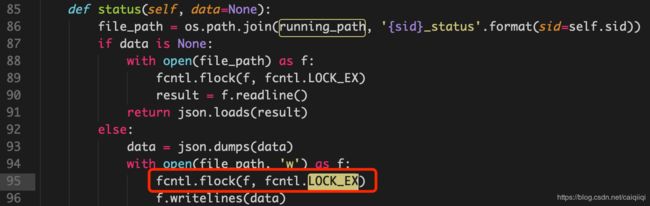
最后是关键的开启扫描任务:
cli.start(args.target, args.format, args.output, args.special_rules, a_sid, args.dels)
跟进start函数,
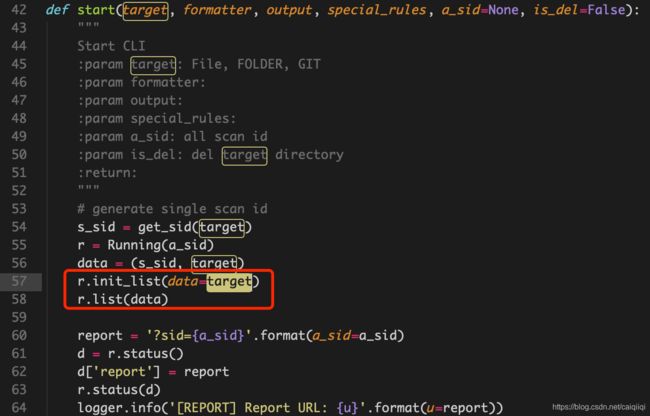
init_list主要是确定给定的target是list还是普通字符串。一般是普通字符串,于是认为总的目标数为1,初始化这个sid对应的文件,

然后list就是跟新一下刚才生成的文件。
最后几行是生成report的链接。
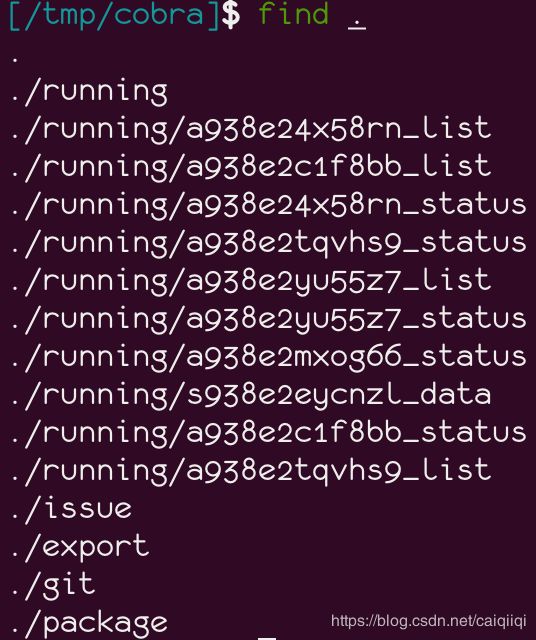
files, file_count, time_consume = Directory(target_directory).collect_files()
用于搜集这个目录下有哪些文件,多少文件,以及花费的时间。
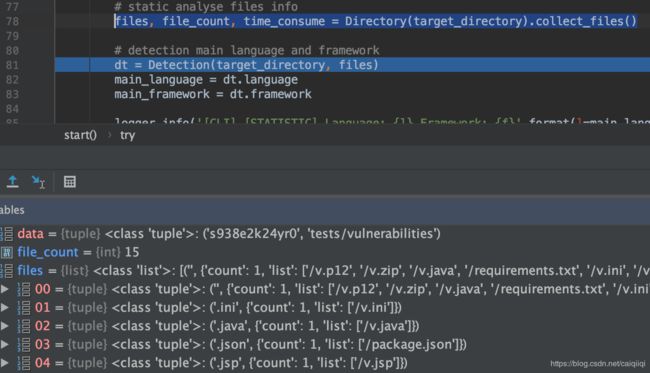
然后下面是检测(Detection):
主要是通过detection.py来完成的:
![]()

先加载了cobra下面的一个配置文件:cobra/rules/frameworks.xml,这个文件里面写了一些框架比如ThinkPHP、Jommla、CI等的特征(目录名、文件名等)。

然后是真正的扫描函数:
scan(target_directory=target_directory, a_sid=a_sid, s_sid=s_sid, special_rules=pa.special_rules,
language=main_language, framework=main_framework, file_count=file_count, extension_count=len(files))
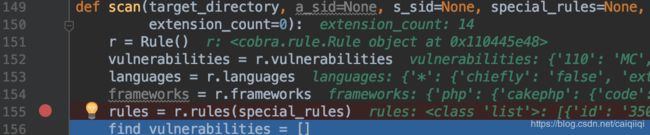
跟进去看一下,主要是载入了rules目录下的各种配置文件,包括框架特征的frameworks.xml、语言(后缀名)特征的languages.xml,以及漏洞大类vulnerabilities.xml,以及各种CVI-开头的配置文件,大概长这样:

其中以CVI-999开头的规则是按年分的CVE漏洞版本规则:
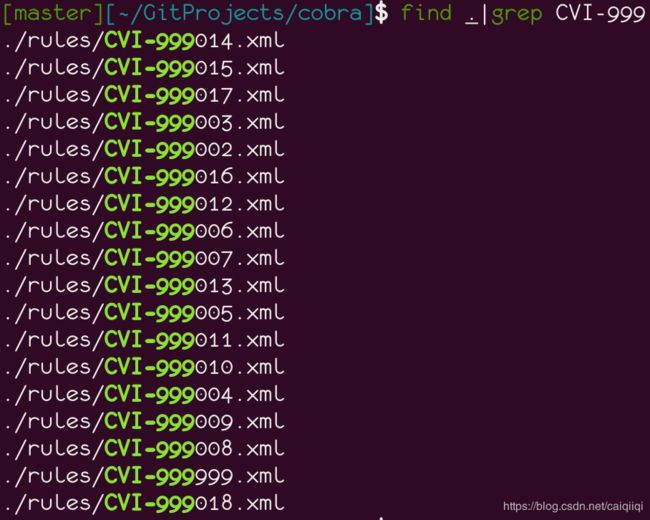
然后把扫描到的规则文件

PrettyTable
其实就是那个打印在命令行的相对好看一些的表格,不过如果不用在命令行显示,也就不需要。
WEB访问模式
当用户启动cobra时提供了host和port,cobra会启动一个WEB服务(debug为命令行参数,是否启动debug模式):

跟进:
cobra/api.py#start

学习一下Flask是怎么运行的:
from flask import Flask, request, render_template, Blueprint
q = queue.Queue()
app = Flask(__name__, static_folder='templates/asset') # 指定静态目录
def producer(task):
q.put(task)
def consumer():
while True:
task = q.get()
p = multiprocessing.Process(target=cli.start, args=task)
p.start()
p.join()
q.task_done()
参考
- 代码审计工具 Cobra 源码分析(一)
- 代码审计工具 Cobra 源码分析(二)
- 开源静态代码审计软件分析比对
- 三款自动化代码审计工具
- 甲方代码审计之道与术
- 利用Cobra实现自动化代码审计的经验分享
Cobra测试
可测试示例Java代码:
- https://github.com/JoyChou93/java-sec-code
- https://github.com/find-sec-bugs/find-sec-bugs/tree/master/findsecbugs-samples-java/src/test/java/testcode
测试一下java-sec-code的代码
命令如下:
python cobra.py -t /home/cqq/repos/java-sec-code/src/main/java/org/joychou
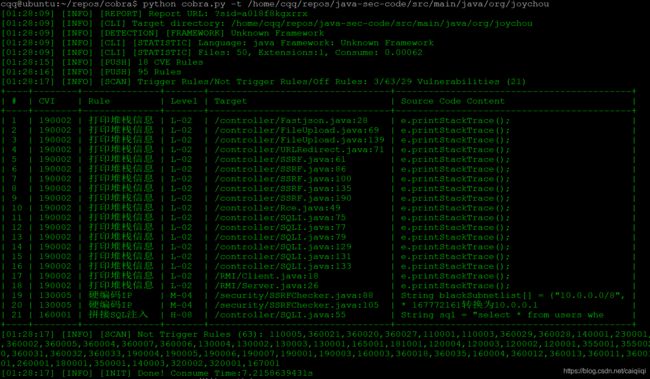
结果显示:
总共有21个漏洞,3种漏洞,还有63个规则没有触发,有29个规则关闭了。
看一下对应CVI的id的规则xml文件:
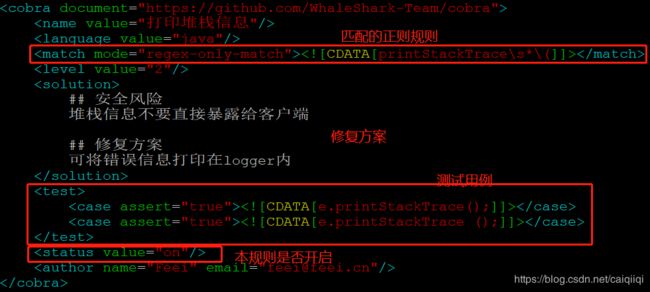
我们不关心这个堆栈打印信息,于是将开关从on修改为off之后,只显示3个规则了。

各种CVI对应的漏洞类型
CVI-11:杂/http?http
CVI-12:SSRF(目前只有php的,待加入java的);
CVI-13:一些硬编码的安全风险;
CVI-14:各种XSS;
CVI-15:无此规则;
CVI-16:SQL注入;
CVI-165:LDAP注入;
CVI-167:XXE;
CVI-17:本地文件包含;
CVI-18:RCE;
CVI-19:各种信息泄露;
CVI-20:不安全的随机数(可移除);
CVI-21:url跳转;
CVI-360:大量的webshell检测

匹配模式
在各个CVI的xml文件中可以看到有匹配模式的差别。有四种模式:
regex-only-match(不区分语言): 默认方式,如果匹配成功,则认为有漏洞;
regex-param-controllable(支持PHP/Java):正则参数可控;
function-param-controllable(仅支持PHP):函数参数可控;
find-extension(寻找某些后缀的文件):匹配到某后缀则认为有漏洞;
详见cobra/const.py:
# Match-Mode
mm_find_extension = 'find-extension'
mm_function_param_controllable = 'function-param-controllable'
mm_regex_param_controllable = 'regex-param-controllable'
mm_regex_only_match = 'regex-only-match'
match_modes = [
mm_regex_only_match,
mm_regex_param_controllable,
mm_function_param_controllable,
mm_find_extension
]
然后在匹配引擎中有具体的判断逻辑(还没看懂)
详见cobra/engine.py
在scan()这个函数中:

而判断参数是否可控,等的逻辑是在cobra/cast.py中配置的。
CAST(Cross Abstract Syntax Tree)
在这里
有grep命令:
# 看到最终还是用OS上的grep工具去匹配(怪不得Mac有点问题,可能是跟Mac自带的grep工具有关)
# -s, --no-messages,表示不显示关于不存在/不可读文件的错误信息
# -r 表示查找某目录下的所有文件
# -n 表示显示行号
# -P 表示使用的是"Perl语言兼容的"" 正则表达式
grep -rnsP "pattern" file_to_grep.java
中间会找到一些行号,然后作为参数传递给sed:
还有sed命令(找到开始行和结束行之间的代码内容):
sed -n 1,3p src/main/java/org/joychou/controller/SSRF.java

目前了解的,有抽象语法树的,也有正则的。
不过看了一下,已有的规则中,模式是抽象语法树的,主要是php。java的也有但是比较少,暂时还写不出来,先用正则的试试吧。
后来发现cobra的文档里都有:
http://cobra.feei.cn/rule_template
还可以好好看看这个具体的例子:
http://cobra.feei.cn/rule_demo
第一次匹配,

第一次匹配成功之后进行二次匹配的规则:

实测发现:
"in-function-down"比“in-current-line”范围大,
比如:
这种代码:
Request.Get(url).execute().returnContent().toString();
两种方式都可以匹配。
但是如果是这种代码:
req = Request.Get(url);
return req.execute().returnContent().toString();
就只有"in-function-down"能匹配到了。
in-file-up
比如这个例子CVI-200001.xml
第一次匹配的规则是:
<match mode="regex-only-match">match>
即先匹配到new Random或者Random.next之后,需要确认这个Random确实是java.util.Random或者scala.util.Random这个包里的Random类,于是需要第二次匹配:
<match2 block="in-file-up">match2>
其中in-file-up就表示第一条规则触发的所在行之上所在文件之内,因为这个类只有先引入才能使用,所以通过确认这个类是否被引入,来确认是否是我们关注的那个Random类。
这种方式可以用来匹配静态方法调用的情况。
注意match2可以使用多次,但是其含义并不是match + match2 + match2;而是match + match2
参考:http://blog.whiterabbitxyj.com/2018/04/19/cobra/
判断参数是否可控的逻辑在:
cast.py#is_controllable_param

Repair字段
上文说过,Cobra使用了2个字段来辅助match字段进行更好的匹配,除了match2字段,另一个就是repair字段。从用法上来说,repair字段和match2字段基本上一模一样,但是他们的作用却是完全相反。在match匹配的前提下,当match2二次匹配成功时,标记为漏洞,而repair却是二次匹配成功时,视为漏洞已被修复,不再标记为漏洞。
来源:http://blog.whiterabbitxyj.com/2018/04/19/cobra/#
杂
原来还可以只扫描某两种漏洞:
# 扫描一个文件夹代码的某两种漏洞
$ python cobra.py -t tests/vulnerabilities -r cvi-190001,cvi-190002
漏洞测试用例
- https://github.com/JoyChou93/java-sec-code
- https://github.com/find-sec-bugs/find-sec-bugs/blob/master/findsecbugs-samples-java/src/test/java/testcode
- https://github.com/threedr3am/learnjavabug
- https://cryin.github.io/blog/JAVA-Static-Code-Audit-and-Analysis/
SSRF
URLConnection/HttpURLConnection
存在漏洞的代码1
String url = request.getParameter("url");
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();//并不发起请求(只是得到一个对象)
BufferedReader in = new BufferedReader(new InputStreamReader(urlConnection.getInputStream())); //发起HTTP请求
存在漏洞的代码2
String url = request.getParameter("url");
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();//并不发起请求(只是得到一个对象)
HttpURLConnection httpUrl = (HttpURLConnection)urlConnection;
BufferedReader in = new BufferedReader(new InputStreamReader(httpUrl.getInputStream())); //发起HTTP请求
urlConnection.connect()发起DNS请求;

urlConnection.getInputStream()发起HTTP请求

urlConnection.getLastModified();发起HTTP请求

url.openStream();发起HTTP请求
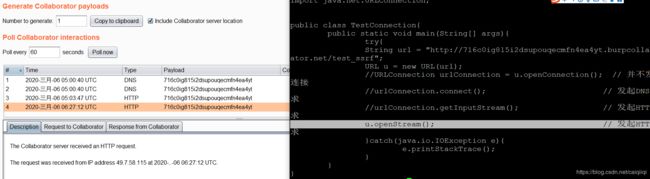
url.getContent();发起HTTP请求
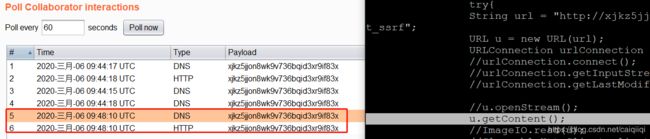
import javax.imageio.ImageIO;
ImageIO.read(u);

URL跳转
- /urlRedirect/redirect?url=http://www.baidu.com

对应代码:
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.GetMapping;
@GetMapping("/redirect")
public String redirect(@RequestParam("url") String url) {
return "redirect:" + url;
}
检测方式:
"redirect:"字符串,以及包名:org.springframework.web.bind.annotation.RequestParam
- /urlRedirect/setHeader?url=http://www.baidu.com

对应代码:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@RequestMapping("/setHeader")
@ResponseBody
public static void setHeader(HttpServletRequest request, HttpServletResponse response){
String url = request.getParameter("url");
response.setStatus(HttpServletResponse.SC_MOVED_PERMANENTLY); // 301 redirect
response.setHeader("Location", url);
}
检测方式:
.setHeader("Location"字符串
- /urlRedirect/sendRedirect?url=http://www.baidu.com
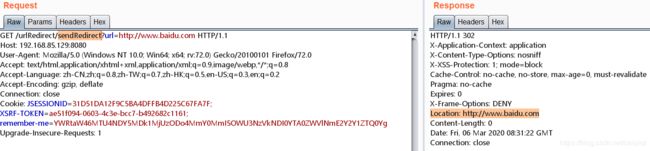
对应代码:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@RequestMapping("/sendRedirect")
@ResponseBody
public static void sendRedirect(HttpServletRequest request, HttpServletResponse response) throws IOException{
String url = request.getParameter("url");
response.sendRedirect(url); // 302 redirect
}
//TODO
通用版本规则(主要用于pom.xml?)
对于fastjson这种需要在pom.xml中查看版本的漏洞扫描方法,看看cobra是怎么扫描的:

cobra有一个专门的规则文件CVI-999999.xml
用于通过版本检测漏洞。
但是这个原理是怎样的还不清楚。
截取部分内容如下:
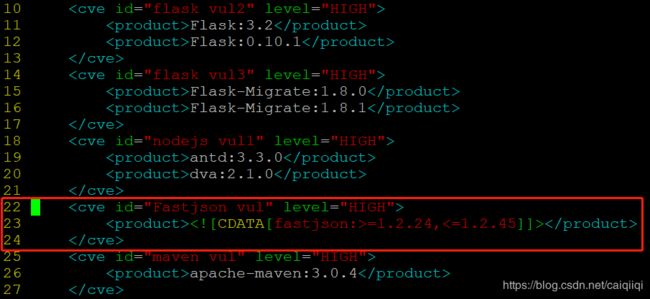
这里的意思应该是大于等于1.2.24,小于等于1.2.45之间的fastjson版本“认为存在漏洞”。
测试发现原来这个只对<= 和>=均无效。只需要指定一个版本号,然后cobra会认为低于这个版本的是存在漏洞的。
比如可以这样写规则:
<cve id="Fastjson vul" level="HIGH">
<product>product>
cve>
find-sec-bugs
The development of Find Security Bugs is supported by GoSecure since 2016. The support includes the development of new detectors and the research for new vulnerability classes.
这个工具是由GoSecure这个公司开发的,包括插件检测规则编写,和新漏洞规(规则)的研究。
这个工具不仅可以作为IDE的插件,也有命令行功能,参考:
https://github.com/find-sec-bugs/find-sec-bugs/wiki/CLI-Tutorial
其所有的漏洞类型(待删除误报较多的规则)参考:
https://find-sec-bugs.github.io/bugs.htm
中文翻译参考:
https://blog.csdn.net/zhaohonghan/article/details/88994382
居然还带解决方案!
但是扫描比较慢。
不需要的规则太多,可以修改
扫描单个jar包:
findsecbugs.bat -high C:\Java\jenkins\WEB-INF\lib\remoting-2.53.jar
生成html报告
findsecbugs.bat -progress -html -output report.htm C:\Java\jenkins\WEB-INF\lib\remoting-2.53.jar
批量扫描jar包
Linux下:
find /some/application/ -name \*.jar > libs.txt
cat libs.txt | findsecbugs.sh -xargs -progress -html -output report.htm
Windows下:
dir "C:/Some/Application/" /s /b | findstr \.jar$ > libs.txt
cat libs.txt | findsecbugs.bat -xargs -progress -html -output report.htm
看了这个工具的大致结构:

找一个序列化的检测代码
具体检测代码:
find-sec-bugs/findsecbugs-plugin/src/main/java/com/h3xstream/findsecbugs/serial/ObjectDeserializationDetector.java

可以检测类都实现了Detector接口。
看它对Velocity和Freemarker模板注入点的检测:


基本上都是两点,即敏感类的全限定名和敏感方法匹配即可。
可以借鉴其检测规则,然后加到Cobra里去。
比如对路径穿越中文件读写点的检测:
find-sec-bugs里有专门的敏感函数列表(虽然是字节码形式的)

比如路径穿越的任意文件写入可以参考:

即两个敏感类:java.io.FileWriter和java.io.FileOutputStream。
路径穿越的任意文件读取可以参考:

java/io/FileReader
java/io/FileInputStream
java/nio/file/Paths.get
java/io/File.createTempFile
javax/activation/FileDataSource
java/nio/file/Files.createTempFile
java/nio/file/Files.createTempDirectory
AST的实现:javaparser
看到cobra使用了这个php parser:https://github.com/viraptor/phply
于是找了一下有没有java parser,找到了这个:
https://github.com/javaparser/javaparser
使用这个测试代码体验了一下找出各种symbols,以及引入的包,类名,方法名等功能。

Cobra的AST模块分析
其源码在cobra/cast.py。
def functions(self)
不过这个是使用Java语言写的,不方便与Cobra集成,于是又找到了两个Python写的Java语法解析器:
https://github.com/c2nes/javalang
刚好看到这个文章抽象语法树分析寻找FastJSON的Gadgets使用到了javalang这个项目,毕竟是Python的库,比较方便整合,所以准备看一下Cobra自己用的AST的代码,然后将其改为javalang。
先看一下Cobra怎么弄的AST,然后才能修改嘛。
首先,他查找方法定义使用的是这样的命令:
grep -snrP "(?:public|protected|private|static|\s) +[\w\<\>\[\]]+\s+(\w+) *\([^\)]*\) *(?:\{?|[^;])" *
(PS:这个文件里四个函数,其中functions()用于拿到项目下所有的方法名;block_code()用于拿到代码块;is_controllable_param()用于判断方法的参数是否用于可控,这个还是蛮难的,这里只实现了PHP。经测试Java的未实现或者实现不完全; match()用于判断规则文件里的repair属性所表示的规则)
functions的大概内容是:
class CAST(object):
languages = ['java']
def __init__(self, rule, target_directory, file_path, line, code, ):
...
...
self.regex = {
'java': {
'functions': r'(?:public|protected|private|static|\s) +[\w\<\>\[\]]+\s+(\w+) *\([^\)]*\) *(?:\{?|[^;])',
'string': r"(?:[\"])(.*)(?:[\"])",
'assign_string': r"String\s{0}\s=\s\"(.*)\";",
'annotation': r"(\\\*|\/\/|\*)+"
}
}
def functions(self):
"""
get all functions in this file
:return:
"""
grep = Tool().grep
if self.language not in self.regex:
logger.info("[AST] Undefined language's functions regex {0}".format(self.language))
return False
regex_functions = self.regex[self.language]['functions']
# 以上面的self.regex中的语言的functions中的正则作为pattern去匹配待匹配的文件
# grep -snrP "(?:public|protected|private|static|\s) +[\w\<\>\[\]]+\s+(\w+) *\([^\)]*\) *(?:\{?|[^;])" <待匹配目录>
param = [grep, "-s", "-n", "-r", "-P"] + [regex_functions, self.file_path]
p = subprocess.Popen(param, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
result, error = p.communicate()
可以看出用这个匹配方式匹配到java-sec-code项目中有206出"函数定义":
77@ubuntu:~/repos/java-sec-code$ grep -snrP "(?:public|protected|private|static|\s) +[\w\<\>\[\]]+\s+(\w+) *\([^\)]*\) *(?:\{?|[^;])" *|wc -l
206
其中也有一些sql语句被认为是java源码而统计出来了:

由于是grep -rn匹配出来的,所以每一行的结果是用:符号分割的,在cobra代码中也是有:对每一行的匹配结果进行了分割,
然后使用re对这个结果再次进行匹配:
re.findall(regex_functions, line_arr[1].strip())
结果大概是这样:

不过有时候会出现解析不出来方法名的情况:

def block_code(self, block_position)
这里的block_position可取的值有四个:
- 0:up(返回当前行以上的部分代码块)
- 1:down(返回当前行以下的部分代码块)
- 2:line(返回当前行)
- 3:in-function
根据传入的值不同,函数返回相应的代码块。
这里调用了
from .pickup import File
跟进源码看一下:

这里传入了给sed的参数,比如
$ sed -n 1p pickup.py
# -*- coding: utf-8 -*-
即pickup.py文件的第一行是# -*- coding: utf-8 -*-。
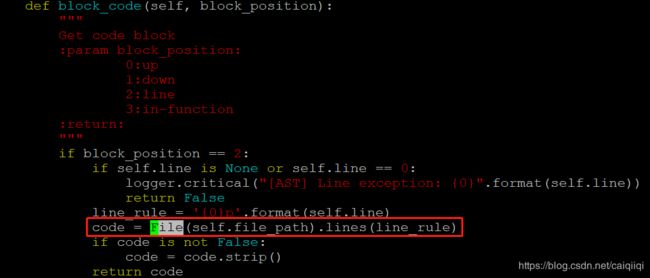
这种情况特殊只是返回单个行,下面的逻辑是返回多个行,语法大概是:
sed -n 1,3p src/main/java/org/joychou/controller/SSRF.java
前面已经分析过了。
def is_controllable_param(self)
判断参数是否用户可控,这个比较难,也是一个关键,如果这个函数的逻辑不够好,则需要自己写(用javalang)。
准备改写。
Cobra的Flask api
从cobra.py开始:
from cobra import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
sys.exit(main())
跟进cobra/__init__.py:
def main():
parser_group_server.add_argument('-H', '--host', dest='host', action='store', default=None, metavar='' , help='REST-JSON API Service Host')
parser_group_server.add_argument('-P', '--port', dest='port', action='store', default=None, metavar='' , help='REST-JSON API Service Port')
...
args = parser.parse_args()
...
# 若命令行中指定了host和port
if args.host!=None and args.port!=None:
try:
if not int(args.port) <= 65535:
logger.critical('port must be 0-65535.')
exit()
except ValueError as e:
logger.critical('port must be 0-65535')
exit()
logger.debug('[INIT] start RESTful Server...')
# 这里开始WEB
api.start(args.host, args.port, args.debug)
跟进cobra/api.py的start方法:
def start(host, port, debug):
logger.info('Start {host}:{port}'.format(host=host, port=port))
api = Blueprint("api", __name__)
resource = Api(api)
resource.add_resource(AddJob, '/api/add')
resource.add_resource(JobStatus, '/api/status')
resource.add_resource(FileUpload, '/api/upload')
resource.add_resource(ResultData, '/api/list')
resource.add_resource(ResultDetail, '/api/detail')
resource.add_resource(Search, '/api/search')
resource.add_resource(GetMemeber, '/api/members')
app.register_blueprint(api)
# consumer
threads = []
for i in range(5):
# 看具体的consumer函数
threads.append(threading.Thread(target=consumer, args=()))
# 起5个线程
for i in threads:
i.setDaemon(daemonic=True)
i.start()
try:
global running_port, running_host
running_host = host if host != '0.0.0.0' else '127.0.0.1'
running_port = port
# 启动Flask APP
app.run(debug=debug, host=host, port=int(port), threaded=True, processes=1)
起了5个线程,
consumer函数用于分派任务:
def consumer():
while True:
task = q.get()
p = multiprocessing.Process(target=cli.start, args=task)
p.start()
p.join()
q.task_done()
可以知道/api/upload这个path对应的处理类是:FileUpload,跟进:
class FileUpload(Resource):
@staticmethod
# 处理POST请求
def post():
"""
Scan by uploading compressed files
:return:
"""
# file字段当然是必须的,如果没有直接返回错误即可(错误代码?1002)
if 'file' not in request.files:
return {'code': 1002, 'result': "File can't empty!"}
file_instance = request.files['file']
if file_instance.filename == '':
return {'code': 1002, 'result': "File name can't empty!"}
if file_instance and allowed_file(file_instance.filename):
filename = secure_filename(file_instance.filename)
dst_directory = os.path.join(package_path, filename)
file_instance.save(dst_directory)
# Start scan
a_sid = get_sid(dst_directory, True)
data = {
'status': 'running',
'report': ''
}
Running(a_sid).status(data)
try:
cli.start(dst_directory, None, 'stream', None, a_sid=a_sid)
except Exception as e:
traceback.print_exc()
code, result = 1001, {'sid': a_sid}
return {'code': code, 'result': result}
else:
return {'code': 1002, 'result': "This extension can't support!"}
allowed_file内容:
def allowed_file(filename):
"""
Allowed upload file
Config Path: ./config [upload]
:param filename:
:return:
"""
config_extension = Config('upload', 'extensions').value
if config_extension == '':
logger.critical('Please set config file upload->directory')
sys.exit(0)
allowed_extensions = config_extension.split('|')
return '.' in filename and filename.rsplit('.', 1)[1] in allowed_extensions
看一下示例请求:

三种匹配模式对比
使用测试规则文件:CVI-771004.xml
<name value="URL#openStream/getContent的SSRF"/>
<language value="java"/>
<match mode="regex-only-match">match>
<match2 block="in-file-up">match2>
对于同一个规则文件的CDATA值保持不变,match的mode分别设置为:regex-only-match、
regex-only-match(不区分语言): 默认方式,如果匹配成功,则认为有漏洞;
cqq: 进入regex-only-match/regex-param-controllable逻辑
/bin/grep
-s
-n
-r
-P
--include=*.java
--exclude-dir=.svn
--exclude-dir=.cvs
--exclude-dir=.hg
--exclude-dir=.git
--exclude-dir=.bzr
\.openStream\(|\.getContent\(
/home/77/repos/java-sec-code/src/main/java/org/joychou/controller/SSRF.java
regex-param-controllable(支持PHP/Java):正则参数可控
cqq: 进入regex-only-match/regex-param-controllable逻辑
/bin/grep
-s
-n
-r
-P
--include=*.java
--exclude-dir=.svn
--exclude-dir=.cvs
--exclude-dir=.hg
--exclude-dir=.git
--exclude-dir=.bzr
\.openStream\(|\.getContent\(
/home/77/repos/java-sec-code/src/main/java/org/joychou/controller/SSRF.java
function-param-controllable(仅支持PHP):函数参数可控;
结果是正则部分变成了这样:
(?:\.openStream\(|\.getContent\()(\s*\((.*)(?:\))|\s*(.*\.)*\$.+)
确实只是匹配PHP的带$符号的变量的。无法用于java。
另外还可以看出所谓的regex-param-controllable支持Java,其实其生成的正则跟regex-only-match没有区别。
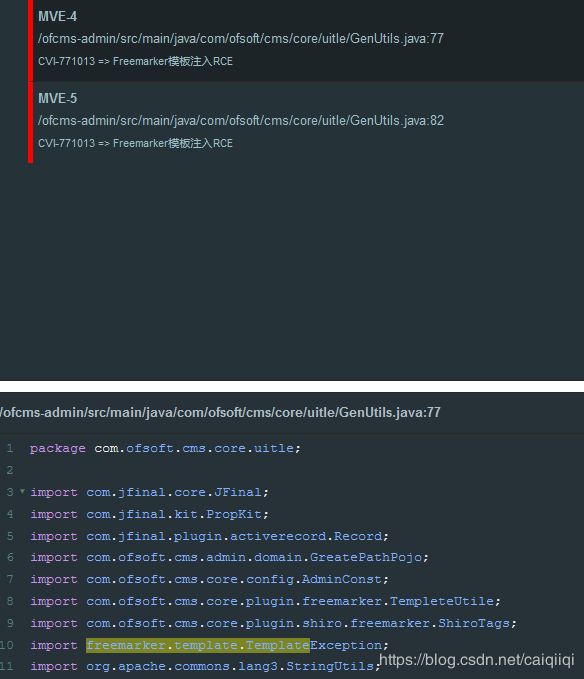
误报
通过这个规则:

导致存在这样的误报:
import中确实有:
import freemarker.template.TemplateException;
即freemarker\.template\.Template,然后后面有一个process方法:
TempleteUtile.process(gre.getTemplatePath(), params, file);
其实并不是freemarker.template.Template#process