python多进程与进程间通信:fork()方法和multiprocess实例
目录
fork()方法(windows不可用)
跨平台multiprocessing
进程池Pool
进程间通信
Queue
pipe()
Manager
注意事项
参考资料
考虑到现在电脑一般都有双核甚至四核的CPU,故可设计算法并行的方法,通过python编程实现并行运算,从而加快处理的速度。虽然没有GPU进行图像算法的并行运算,但是能利用好双核CPU应该也是大有帮助吧!
fork()方法(windows不可用)
对于Linux/Unix/MacOS系统,可以用fork()方法创建子进程。如果你是这些系统,或macbook电脑,就学习fork()方法即可。
由于没有实践过,这部分可参考廖雪峰老师网站,但是网上的资料都比较简练,需要深入了解实践的话还需要多研究一下。
由于Windows没有fork调用,上面的代码在Windows上无法运行。由于Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的。有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,在上述例子里,先fork()好了子进程,遇到if...else...语句后,父进程处理了第一个语句(if),打印相应内容;接着else:则由子进程来处理。(常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。)
关于fork()方法,需要注意的几个关键点:
1、子进程与父进程的复制关系:
子进程拥有父进程的所有内存的精确副本。当使用fork给进程分叉时,它会创建一个自己的副本。在多线程环境中,fork意味着执行的线程是重复的,但是可以分开。因此,有的学者认为fork很像生物里克隆的概念。子进程克隆了父进程。获取了父进程的数据和代码。
子进程退出必须使用os.exit(0),否则子进程将返回到父进程中。
2、相互独立关系
父进程和子进程的执行是相互独立的。fork操作为子进程创建了一个单独的地址空间。子进程从操作系统接收一个新的进程号PID号(PID,进程标识符)。
3、fork()的返回值:
fork的返回值决定当前正在进行的是哪一个进程:0表示在子进程中,正值表示在父进程中,-1表示出错了。
跨平台multiprocessing
虽然windows不支持fork方法,但是鉴于python的跨平台特性,windows也是有办法的——multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象。

下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')运行结果:
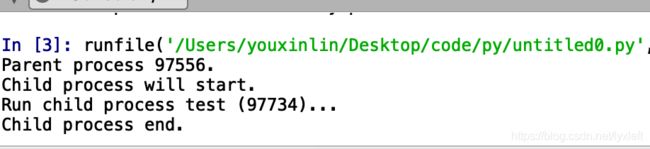
创建子进程时,用process函数,传入参数为:一个要执行的方法、函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步,是针对每一个进程单独起作用的,这个和setdaemon不同。
进程池Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程。先看下源码:
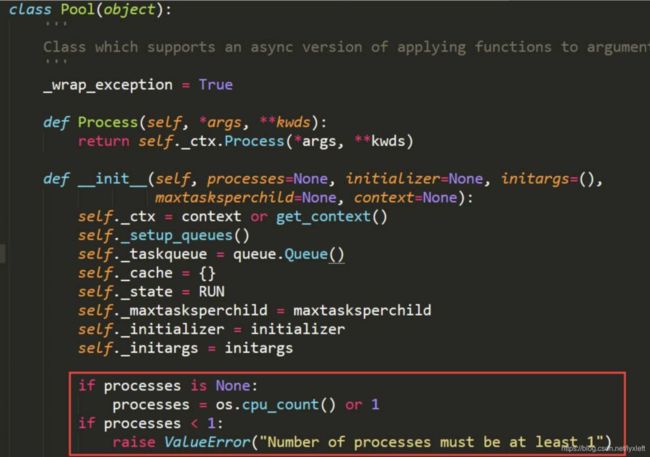
processes参数代表了进程池数目,默认是cpu核数。多进程的启动方法是apply_async()。

func是我们要启动的函数,args和kwds是可变参数。其他的不重要。。
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
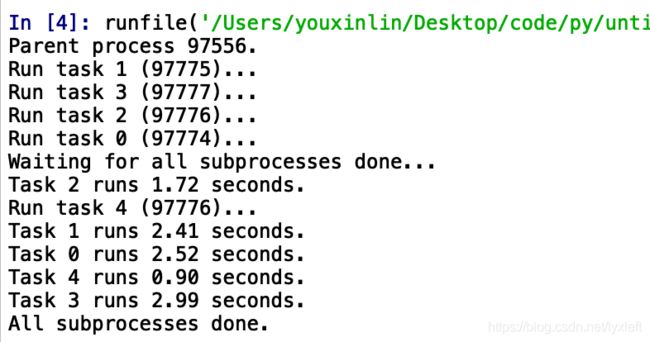
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
Queue
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所有,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
多进程中,对于一个变量,每个进程都是复制了一份,所以每个进程之间修改数据互不影响。 Queue()方法相当于第三方,把进程A的数据序列化后传给进程B反序列化得到数据。并不是一个共享的变量。而是实现了数据的传递。
pipe()
类似于socket 一端发送,一端接收,实现通信。
from multiprocessing import Process,Pipe
def f(conn):
conn.send([5,'hello'])
conn.close()
if __name__ =='__main__':
parent_conn,child_conn = Pipe()
p = Process(target=f,args=(child_conn,))
p.start()
print(parent_conn.recv())
p.join()或用pipe()实现双方相互通信:
def f(conn):
conn.send([5,'hello']) #发送数据
print(conn.recv()) #接收数据
conn.close()
if __name__ =='__main__':
parent_conn,child_conn = Pipe()
p = Process(target=f,args=(child_conn,))
p.start()
print(parent_conn.recv()) #接收数据
parent_conn.send("hehe你好") #发送数据
p.join()Manager
个人认为manager是最简单易懂的方法,自己也是用它来方便地实现并行计算。
由manager()返回的manager对象控制一个包含Python对象的服务器进程,并允许其他进程使用代理来操作它们。
由manager()返回的管理器将支持类型列表、命令、名称空间、锁、RLock、信号量、BoundedSemaphore、Condition、Event、Barrier、Queue、Value和Array。在基本的一些编程案例中,其实只是需要上述类型的基本数据的传递、互通,所以用manager很方便。下面是我的一个例子:
import numpy as np
import multiprocessing
import time
def funca(mylist):
time.sleep(2)
mylist.append(666.6)
def funcb(mylist):
time.sleep(2)
mylist.append(66.6)
if __name__ == "__main__":
samples = [1,2,3]
tic = time.time()
funca(samples)
funcb(samples)
toc = time.time()
print('pass time = ',toc-tic)这个结果显示大约要4s(每个函数人为设置了2s的delay)。
现在要通过双进程方法,来修改samples这个list:
import numpy as np
import multiprocessing
import time
def funca(mylist):
time.sleep(2)
mylist.append(666.6)
def funcb(mylist):
time.sleep(2)
mylist.append(66.6)
if __name__ == "__main__":
samples = [1,2,3]
with multiprocessing.Manager() as MG: #重命名#
mylist = MG.list(samples) #主进程与子进程共享这个List
tic = time.time()
p1=multiprocessing.Process(target=funca,args=(mylist,) ) #创建新进程1
p2=multiprocessing.Process(target=funcb,args=(mylist,) ) #创建新进程2
p1.start()
p2.start()
p1.join()
p2.join()
p1.terminate()
p2.terminate()
toc = time.time()
print('pass time = ',toc-tic)
print(mylist)此时可以看到,运行时间变为2s左右。 即实现了对一个全局变量(或外部变量)的并行修改。在一些算法中会应用到此点。
注意事项
创建process时,args是我们要传入函数的参数,类型为数组!如果只有一个参数i,也要写成(i,),少了逗号会报错。
进程工作完后最好terminate()一下,否则可能一直在后台运行,电脑掉电很快。
参考资料
1、廖雪峰老师官方网站
2、http://www.cnblogs.com/qing-chen/p/7688343.html、https://blog.csdn.net/JackLiu16/article/details/82598298等,网上有许多实例。但原理还是要自己去挖一挖。
