redis的五种基础数据结构API及拓展数据结构(拓展数据结构本质还是五种基础数据结构)
本文简单介绍下redis的五种基础数据结构,以及基于这五种数据结构拓展出的其它数据结构。
一.redis支持的五种基础数据结构为:String、Hash Table、Linked List、Set、Set,对redis来说所有的键K都是字符串类型。
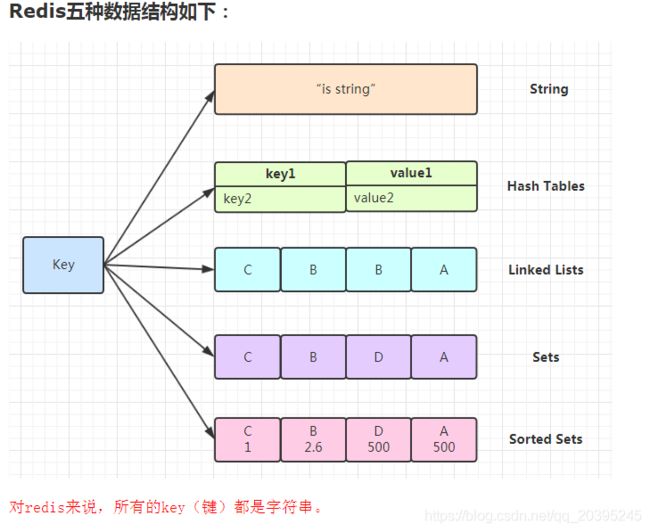
也有的将这五种数据结构根据存储方式不同又进行了拆分:
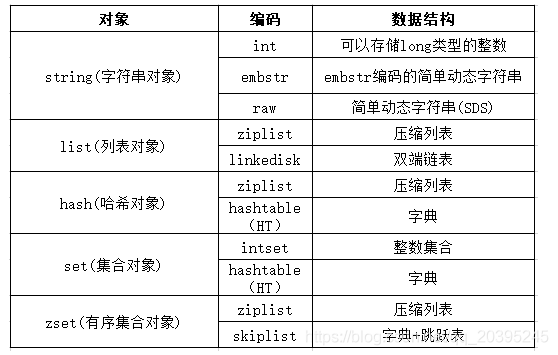
这里不进行深入探析,只对以下五种大类的数据结构进行简单API使用和常用场景的介绍。
(1)String
String是最基础的数据类型,也是应用最广泛的数据类型。String类型是二进制安全的,所以redis 的 string 可以包含任何数据,可以是字符串(简单的字符串、复杂的字符串(xml、json)、数字(整数、浮点数)、二进制(图片、音频、视频)),但最大不能超过512M。
String类型对应的API操作有:get 、 set 、 del 、 incr、 decr 、incrby 等。
192.168.147.134:6379> set k1 hello #设置键k1值hello
OK
192.168.147.134:6379> get k1 #获取键k1的值
"hello"
192.168.147.134:6379> del k1 #删除键k1的数据,返回1表明成功0失败
(integer) 1
192.168.147.134:6379> get k1 #获取键k1的值,不存在则返回(nil)
(nil)
192.168.147.134:6379> set counter 1 #设置键counter值为数值型
OK
192.168.147.134:6379> incr counter #键counter的值自增,返回自增后结果
(integer) 2
192.168.147.134:6379> get counter #获取键counter当前的值
"2"
192.168.147.134:6379> incrby counter 100 #设置键counter值增加100,返回增加后结果
(integer) 102
192.168.147.134:6379> decr counter #设置键counter值自减,返回自减后结果
(integer) 101
192.168.147.134:6379>
常见应用场景:
1.缓存功能: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,绝大多数请求通过redis完成读取,由于redis具有支撑高并发特性所以可以大大降低mysql的读写压力;
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。例如视频播放数或进度可以使用redis作为计数组件;
3.session共享:在分布式进行负载均衡时,因为用户信息分布在不同的服务器上所以常常需要重新登录,这样显然不符合用户的使用习惯,因此可以使用redis对session进行缓存共享,将用户信息在redis中进行集中管理,只要保证高可用和拓展性就可以让用户信息每次从redis中获取保证各个服务器之间共享session。
(2)Hash Table
在redis中哈希类型是指键本身又是一种键值对结构,如 value={{field1,value1},......fieldN,valueN}}
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
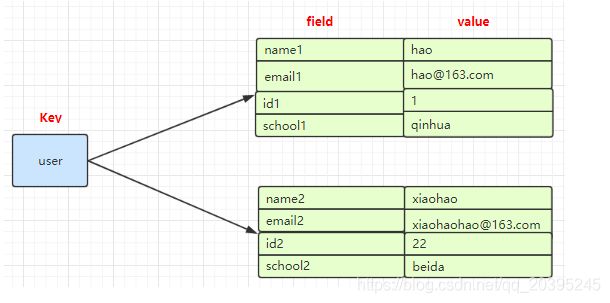
#设置一个hash表对象键为boy,类似一个json对象。设置name,description,age属性
192.168.147.134:6379> HMSET boy name "tom" description "a boy" age 10 #设置键boy的内容
OK
192.168.147.134:6379> HGETALL boy #获取在哈希表中指定boy的所有字段和值
1) "name"
2) "tom"
3) "description"
4) "a boy"
5) "age"
6) "10"
#修改hash表对象键boy的name属性值
192.168.147.134:6379> HSET boy name xiaoming
(integer) 0
192.168.147.134:6379> HGETALL boy
1) "name"
2) "xiaoming"
3) "description"
4) "a boy"
5) "age"
6) "10"
常见应用场景:
存储、读取、修改用户属性
(3)Linked List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),值可以重复。一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。

List 说白了就是链表(redis 使用双端链表实现的 List),因此存在头部和尾部,lpush表示头部加入,lpop表示头部退出,rpush表示尾部加入,rpop表示尾部退出。不同的命令组合可以实现不同功能,如栈,队列等
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
#下面展示头部加入和退出的例子:
192.168.147.134:6379> lpush book redis #头部给键book加入redis值元素,此时结构为redis
(integer) 1
192.168.147.134:6379> lpush book mysql #头部给键book加入mysql值元素,此时结构为mysql--redis
(integer) 2
192.168.147.134:6379> lpush book java #头部给键book加入java值元素,此时结构为java--mysql--redis
(integer) 3
192.168.147.134:6379> lrange book 0 10 #头部遍历键book,得到结构为java--mysql--redis
1) "java"
2) "mysql"
3) "redis"
192.168.147.134:6379> lpop book #从头部开始退出一个元素,退出元素为java,剩余结构为mysql--redis
"java"
192.168.147.134:6379> rpop book #从尾部开始退出一个元素,退出元素为redis,剩余结构为mysql
"redis"
192.168.147.134:6379> lrange book 0 10 #查看退出后键book剩余值,为mysql
1) "mysql"
常见应用场景:
- 时间轴
- 消息队列
(4) Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
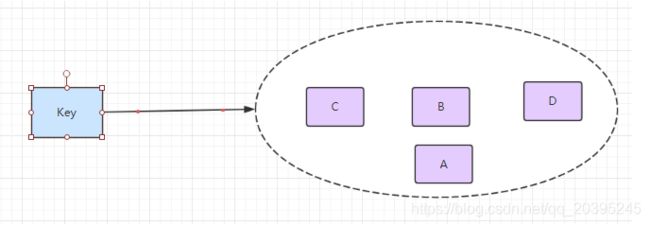
特点:
1. 不允许有重复的元素
2.集合中的元素是无序的,不能通过索引下标获取元素
3.支持集合间的操作,可以取多个集合取交集、并集、差集。
使用:命令都是以s开头的 sset 、srem、scard、smembers、sismember
#给键books集合添加元素:
192.168.147.134:6379> sadd books redis #向集合添加一个成员redis
(integer) 1
192.168.147.134:6379> sadd books java
(integer) 1
192.168.147.134:6379> sadd books php
(integer) 1
192.168.147.134:6379> smembers books #返回集合中的所有成员
1) "redis"
2) "php"
3) "java"
192.168.147.134:6379> scard books #获取集合的成员数
(integer) 3
#给键books-2集合添加元素:
192.168.147.134:6379> sadd books-2 java
(integer) 1
192.168.147.134:6379> sadd books-2 c++
(integer) 1
192.168.147.134:6379> smembers books-2
1) "c++"
2) "java"
#对books集合和books-2集合做交集、并集、差集:
192.168.147.134:6379> SUNION books books-2 #返回所有给定集合的并集
1) "c++"
2) "redis"
3) "php"
4) "java"
192.168.147.134:6379> SINTER books books-2 #返回所有给定集合的交集
1) "java"
192.168.147.134:6379> SDIFF books books-2 #返回所有给定集合的差集
1) "redis"
2) "php"
常见应用场景:
1.共同好友、二度好友
2.统计访问网站的所有独立 IP
3.给消息贴标签tag,当好友推荐时根据推荐的消息计算好友间推荐消息交集,当大于某个阈值时可以进行互相推荐
(5)ZSet(Sort Set)
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,score值可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
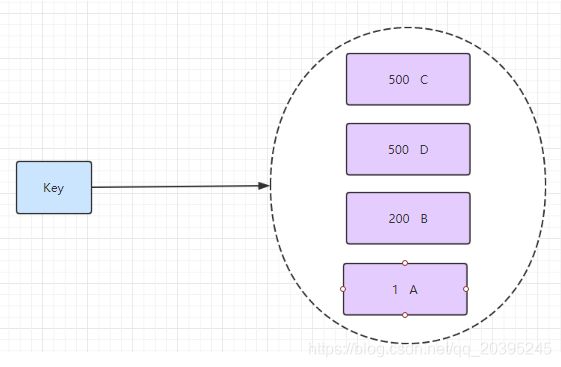
使用: 有序集合的命令都是 以 z 开头 zadd 、 zrange、 zscore
#添加有序的set集合bookz
192.168.147.134:6379> ZADD bookz 1 redis
(integer) 1
192.168.147.134:6379> ZADD bookz 2 java
(integer) 1
192.168.147.134:6379> ZRANGE bookz 0 10 WITHSCORES
1) "redis"
2) "1"
3) "java"
4) "2"
常见应用场景:
1.带有权重的元素,比如一个游戏的用户得分排行榜
2.比较复杂的数据结构,一般用到的场景不算太多
二.redis拓展基础数据结构:Pipeline、GEO、hyperLogLog、bitmaps(重要)
(1)Pipeline管道:
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
因此正常情况下,1 次时间 = 1 次网络时间 + 1次命令时间,这样如果执行N条命令就会非常消耗时间性能:

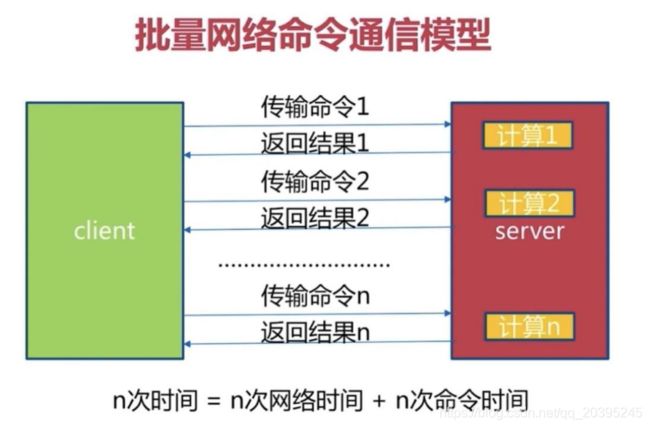
如果使用Pipeline,则可以将所有命令进行打包然后一次发出,1 次 pipeline(n条命令) = 1 次网络时间 + n 次命令时间
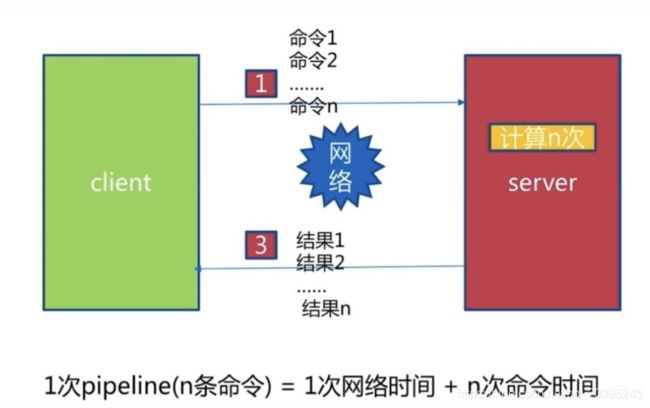
- 省略由于单线程导致的命令排队时间,一次命令的消耗时间=一次网络时间 + 命令执行时间
- 比起命令执行时间,网络时间很可能成为系统的瓶颈
- pipeline的作用是将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回。
- 通过pipeline,一次pipeline(n条命令)=一次网络时间 + n次命令时间
Pipeline可以结合jedis在java程序中使用,如前面学习redis持久化机制时导入500万条记录到持久化文件中的例子,就是使用了Pipeline,使用方法可看https://blog.csdn.net/qq_20395245/article/details/106971450
(2)GEO
GEO功能在Redis3.2版本提供,支持存储地理位置信息用来实现诸需要依赖于地理位置信息的功能.geo的数据类型为zset.
GEO目前使用并不多,有兴趣可自行查找资料了解。
(3)hyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
关于基数计算,有兴趣可自行查找资料了解。
(4)bitmaps
在redis中,有一个很重要的概念就是bitmaps位图。实际上redis中数据的存储是以二进制形式存储的,那么这些数据就可以对应最小的单元:位图。通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身,value对应0或1,我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省储存空间。
下面通过set k3 big写入一个键为k3值为big的数据:
192.168.147.134:6379> set k3 big
OK
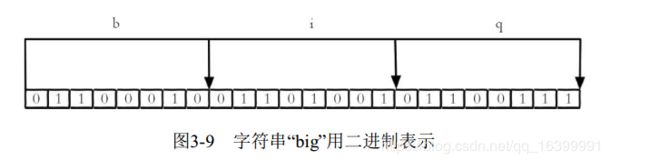
实际上,这个k3数据在redis是以二进制形式存储的,而“big”分别对应的ASCII码分别是98、 105、 103, 对应的二进制分别是01100010、 01101001和01100111,如下所示:
1.设置值
命令:setbit key offset valuesetbit命令接收两个参数,
第一个参数表示你要操作的是第几个bit位,第二个参数表示你要将这个位设为何值,可选值只有0,1两个。如果所操作的bit位超过了当前字串的长度,reids会自动增大字串长度。
2 获取值
命令:getbit key offsetgetbit只是返回特定bit位的值。如果试图获取的bit位在当前字串长度范围外,该命令返回0
3 获取Bitmaps指定范围值为1的个数
命令:bitcount key [start] [end]4 Bitmaps间的运算
- bitop:对两个不同字串进行位运算。可进行的运算有AND, OR, XOR以及NOT
5 计算Bitmaps中第一个值为targetBit的偏移量
- bitpos: 查找第一个值为0/1的比特位的位置
命令:bitpos key targetBit [start][end]
返回:第一个值为的偏移量
通过上面API我们可以通过setbit key offset value这个API对这个二进制数据进行修改,经过big存储数据的对比:
我们要想将big改为iig,只要将offset=4设为1,offset=6设为0,offset=7设为1即可:
192.168.147.134:6379> setbit k3 4 1
(integer) 0
192.168.147.134:6379> setbit k3 6 0
(integer) 1
192.168.147.134:6379> setbit k3 7 1
(integer) 0
192.168.147.134:6379> get k3
"iig"
常用场景:
1.点赞,取消点赞,计算点赞数。我们建立了一个消息bitmap,每一位标识一个数值型用户ID,当给这个消息点赞或取消时在对应位置上设置为1或0,通过bitcount统计点赞数;
2.统计网络在线用户数:为了统计今日登录的用户数,我们建立了一个bitmap,每一位标识一个数值型用户ID。当某个用户访问我们的网页或执行了某个操作,就在bitmap中把标识此用户的位置为1,通过bitcount统计在线用户总数。
3.布隆过滤器在缓存击穿中应用
三.redis其它常见应用场景
1. 订阅-发布系统
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在 Redis 中,你可以设定对某一个 key 值进行消息发布及消息订阅,当一个 key 值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
2.热点数据存储
3.redis事务可以一次执行多个命令,单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。redis事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
四.关于redis语法用法可参考redis教程网站:https://www.runoob.com/redis/redis-hashes.html
备注:本文部分图片来源其它网友文档,如有侵权请联系删除,谢谢。