redis三大缓存问题之缓存雪崩(搭建rediscluster高可用集群方案)
前面一篇文章介绍了redis的缓存穿透问题,接下来这篇文章着重介绍redis的缓存雪崩问题以及解决方案,最后通过代码进行测试。
(一)什么是redis缓存雪崩问题?
缓存雪崩是指,由于缓存层承载着大量请求可以有效的保护数据库存储层,但是如果缓存层同时出现大量缓存失效的情况,或者突然有个别机器节点挂掉了,导致大量的请求直接到达存储层,造成存储层也会挂掉的情况。
(二)redis缓存雪崩常用解决方案?
针对上面出现的缓存雪崩场景,通常有不限于以下一些解决方案,这些方案可以依实际场景互相搭配使用:
1)搭建高可用rediscluster集群保证服务高可用;
2)使用隔离组件为后端限流并降级;在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量;
3)数据预热设置均匀的缓存失效时间;通过缓存reload机制,预先去更新缓存,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
(三)搭建高可用rediscluster集群,rediscluster工作原理?
这一部分重点介绍何如使用linux搭建一个高可用的rediscluster集群。首先先介绍一下rediscluster的工作原理。
什么是rediscluster高可用集群:
redis cluster集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis cluster集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到1000节点。redis cluster集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
官方规定每个rediscluster集群至少要有3组小集群,每个小集群至少有一主一从节点,总的槽位数为16384个,槽位仅在主节点上,整个集群必须将16384个槽位全部分配。当一个key请求时,先对该key进行crc16算法计算出该key应该落在哪个片区上,然后将该key转到对应片区小集群中执行redis命令。

如何在linux系统上搭建如下高可用集群,并且支持故障切换和集群伸缩的功能,为了简化演示部署图如下所示:
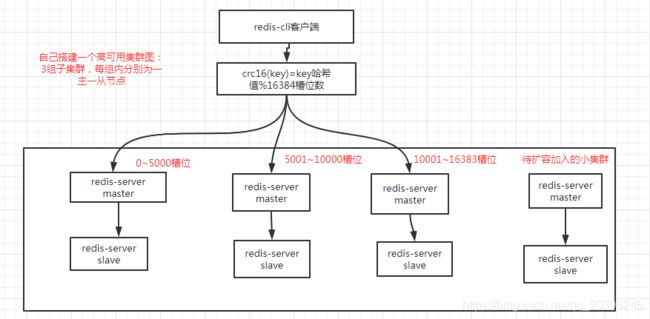
redis cluster集群需要至少要三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,由于节点数较多,这里采用在一台linux机器上创建6个redis实例,并将这6个redis实例配置成集群模式,所以这里搭建的是伪集群模式,但是和真正的使用6台机器进行分布式集群的配置方法几乎一样,集群搭建步骤如下:
第一步:在/usr/local下创建文件夹redis-cluster,然后在其下面分别创建6个文件夾如下,如果涉及权限不足可以使用sudo或su root切换为管理员账号操作。
(1)mkdir -p /usr/local/redis-cluster
(2)mkdir -p 8001
mkdir -p 8002
mkdir -p 8003
mkdir -p 8004
mkdir -p 8005
mkdir -p 8006
![]()
第二步:把redis的配置文件redis.conf分别拷贝到8001文件夹下,修改redis.conf对应配置如下内容:
cd 8001 /
sudo cp /opt/redis-5.0.8/redis.conf redis.conf![]()
sudo vi redis.conf(点击键盘i进入编辑模式,编辑完成后ESC键再通过shift+:wq!保存退出)
(1)daemonize yes
(2)port 8001(分别对每个机器的端口号进行设置)
(3)bind 127.0.0.1(如果只在本机则可以指定为127.0.0.1 如果需要外网访问则需要指定本机真实ip)
(4)dir /usr/local/redis-cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据)
(5)pidfile /var/run/redis_8001.pid(进程信息文件)
(6)cluster-enabled yes(启动集群模式)
(7)cluster-config-file nodes-8001.conf(这里800x和port对应上)
(8)cluster-node-timeout 5000
(9)appendonly yes
(10)requirepass 123456 (设置节点密码,每个节点密码最好设置为一样的便于主从切换,设置后所有命令带 -a xxxx)
第三步:把修改后的配置文件8001.conf,批量替换8001字眼并复制到8002,8003,8004,8005,8006目录下,
sudo sed 's/8001/8002/g' /usr/local/redis-cluster/8001/redis.conf > /usr/local/redis-cluster/8002/redis.conf
(如果在8001目录下,则 sed 's/8001/8002/g' redis.conf > ../8002/redis.conf)
语法: sed 's/目标值/替换成什么值/g' 目标文件 > 替换后生成到哪里,注意如果提示sed找不到文件或目录,则确认下上面sed命令的文件>前后是不是多出了多余的空格,>前后只有一个空格。
这样,在8001~8006目录下就都产生了各自的redis.conf实例配置文件。
第四步:由于 redis集群需要使用 ruby命令,所以我们需要安装 ruby(redis5.0之后可省略该步骤)
(1)yum install ruby
(2)yum install rubygems
(3)gem install redis --version 3.0.0(安装redis和 ruby的接囗)
![]()
第五步:分别启动6个redis实例,然后检查是否启动成功,可以看到有个cluster标识:
(1)/opt/redis-5.0.8/redis-server /usr/local/redis-cluster/800*/redis.conf(该命令如果报错就一个个启动)
(2)ps -ef | grep redis 查看是否启动成功
(3)如果有多余的redis实例进程,可通过kill 9 pid关闭进程

第六步:创建集群关联
上面已经将所有的节点都以cluster启动了,但是还不算一个互相联系的集群。接下来需要建立集群关联,设置槽位等配置。
可以使用原生命令,也可以使用rb命令。
原生命令创建集群关联的步骤:
1.配置开启cluster节点:
cluster-enabled yes(启动集群模式)
cluster-config-file nodes-8001.conf(这里800x最好和port对应上)
2.meet关联:
通过redis-cli访问某个节点,然后在这个节点上通过 cluster meet ip port 关联另外一个cluster节点
3.指派槽: 在redis-cli登录的节点上,执行添加槽位命令
cluster addslots slot(槽位下标)
(查看crc16算法算出key的槽位命令:cluster keyslot key)
4.分配主从:
cluster replicate node-id
但是redis5.0可以使用工具命令将上述所有的步骤,通过下面命令帮助获取强大的集群工具命令集:
redis-cli -h 127.0.0.1 -p 8001 --cluster help

1.创建集群:
create host1:port1 ... hostN:portN --cluster-replicas
将所有host:port进行meet,然后按照
例子(如果命令报错则全部手动输入,由于6个节点配置文件配置requirepass密码故所有命令都要带-a参数):
./redis-cli --cluster create 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005 127.0.0.1:8006 --cluster-replicas 1 -a 12345
上面命令按提示执行就会自动将6个节点信息进行meet,然后按照主从1:1的比例分配子集群,由于最少要3个子集群,因此这里6个节点设置为1,就会产生3个子集群,每个子集群内主从比例为1:1:

2.查看集群信息:
redis-cli -h 127.0.0.1 -p 8001 cluster nodes

3.查看分配的主机槽位信息:

第七步:验证集群:
(1)连接任意一个客户端即可:./redis-cli -c -h -p (-c表示集群模式,指定ip地址和端口号)如:
/usr/local/bin/redis-cli -c -h 127.0.0.1 -p 8001 -a 123456
(2)进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)
(3)进行数据操作验证:如 set k1 v1,看k1数据被存储到哪个节点上,可通过cluster keyslot key计算槽位验证数据是否存储到正确的节点上;

从节点信息表也可看出12706槽点位于8003节点上,因此这个分布式集群就搭建成功了。
(4)关闭集群则需要逐个进行关闭,使用命令:
/usr/local/bin/redis-cli -c -h 127.0.0.1 -p 800* -a 123456 shutdown

(四)代码测试?
(五)对现有rediscluster集群进行扩容或缩容演示?
扩容:采用上面步骤三的方式,新建两个redis用于扩容的实例,分别为8007和8008并启动,查看redis进程:
ps aux | grep redis
可以看到8007和8008也是集群模式,但是还没有加入到集群中:
/usr/local/redis-cluster/8001# redis-cli -h 127.0.0.1 -p 8001 -a 123456 cluster nodes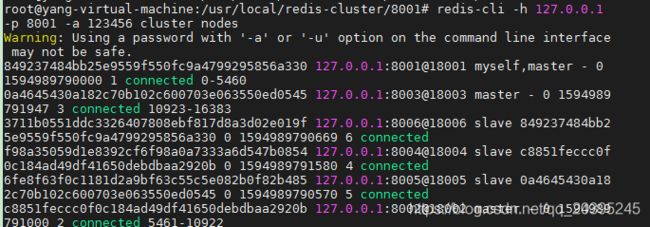
要加入到已有集群中,可以通过add-node命令(redis-cli -h 127.0.0.1 -p 8001 --cluster help帮助查看)
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id
eg:/usr/local/bin/redis-cli --cluster add-node 127.0.0.1:8007 127.0.0.1:8001 -a 123456 (默认是主机)

再添加一个从机8008,并关联到主机8007上:
/usr/local/bin/redis-cli --cluster add-node 127.0.0.1:8008 127.0.0.1:8001 --cluster-slave 0350de1aa29773cb0c38081c10f26e8d1e4aa17a -a 123456 (使用 --cluster-slave 参数表明是从机,后接主机ID)

再查看集群节点信息,就能看到新的子集群就添加到原有集群中了:

接下来,还要为这个新加入的子节点8007添加槽位:
还是通过--cluster help可以找到添加槽位的命令:
reshard host:port
--cluster-from
--cluster-to
--cluster-slots
--cluster-yes
--cluster-timeout
--cluster-pipeline
--cluster-replace
eg:从8001中 给8007分配300个槽位,这里使用提示方式分配。
/usr/local/bin/redis-cli --cluster reshard 127.0.0.1:8007
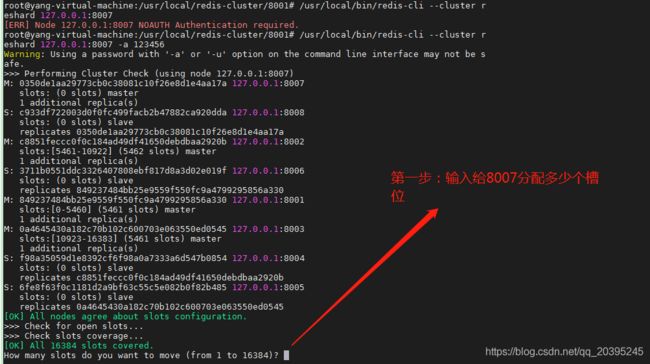

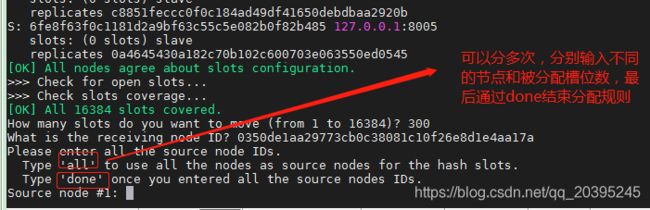
all:所有已有子节点平均分配,再给到新加入的子节点
#1,#2....:自定义分配规则,自定义哪个节点分配多少槽位,最后通过done结束规则
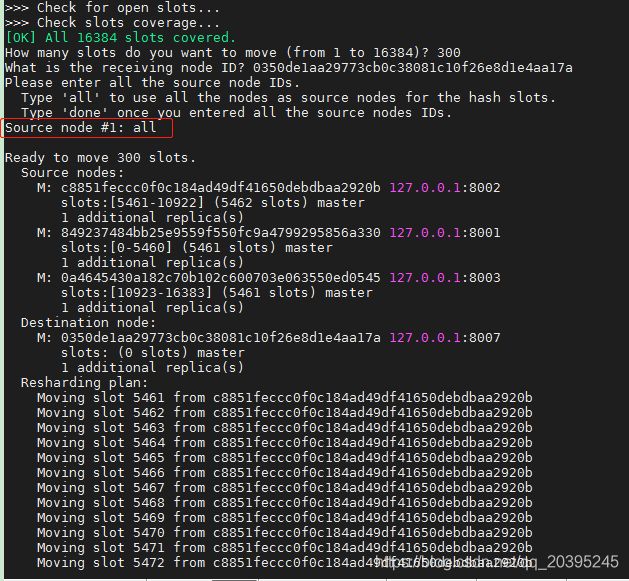

这样,8007就拥有了指定的300个槽位,扩容操作就完成了。注意,扩容后原槽位上的数据也会自动被迁移到新的主机集群下:

缩容:
缩容是将现有集群中某些子集群移出集群,在缩容之前首先要释放槽位。还是通过--cluster help查看帮助命令。
reshard host:port
--cluster-from
--cluster-to
--cluster-slots
--cluster-yes
--cluster-timeout
--cluster-pipeline
--cluster-replace
eg:将8007的300个槽位重新释放,迁移到8001子集群上,通过--cluster-from,--cluster-to和cluster-slots参数进行缩容
/usr/local/bin/redis-cli --cluster reshard 127.0.0.1:8007 --cluster-from 0350de1aa29773cb0c38081c10f26e8d1e4aa17a --cluster-to 849237484bb25e9559f550fc9a4799295856a330 --cluster-slots 300 -a 123456
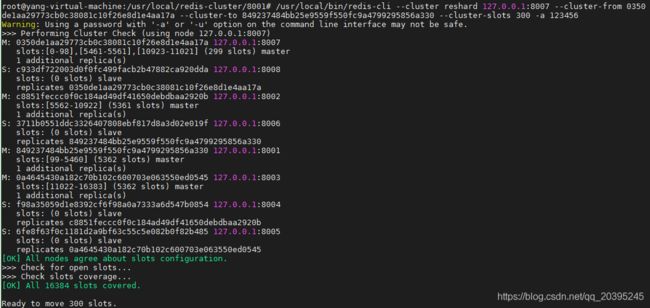
再次查看8007节点,则原本8007的槽位就全部转移到8001节点了:

最后,通过--cluster help帮助命令中的 del-node host:port node_id就可以将要移出的节点移出出去,注意先删除子节点,再删除主节点:
/usr/local/bin/redis-cli --cluster del-node 127.0.0.1:8001 c933df722003d0f0fc499facb2b47882ca920dda -a 123456 (先删除从节点)
/usr/local/bin/redis-cli --cluster del-node 127.0.0.1:8001 0350de1aa29773cb0c38081c10f26e8d1e4aa17a -a 123456 (最后删除主节点)

最后查看,8007和8008组成的子集群就被移除了:

总结:集群缩容时,在移出子集群之前一定要先释放子集群主机槽位,槽位转移后先删除从节点,再删除主节点。
(六)故障转移演示?
集群在运行时,突然有某些子集群挂了,但是程序还在持续写入数据,那么挂掉的主机会被自动下线,由从机自动替换,但是这个故障转移的期间写入数据还是会丢失。
测试代码如下:
import com.redis.test.redis.MyRedisCluster;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Set;
import java.util.UUID;
public class TestRedisCluster {
public static void main(String[] args) {
Logger logger= LoggerFactory.getLogger(TestRedisCluster.class);
Set nodesList=new HashSet<>();
nodesList.add(new HostAndPort("XXXX",8001));
nodesList.add(new HostAndPort("XXXX",8002));
nodesList.add(new HostAndPort("XXXX",8003));
nodesList.add(new HostAndPort("XXXX",8004));
nodesList.add(new HostAndPort("XXXX",8005));
nodesList.add(new HostAndPort("XXXX",8006));
// Jedis连接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大空闲连接数, 默认8个
jedisPoolConfig.setMaxIdle(200);
// 最大连接数, 默认8个
jedisPoolConfig.setMaxTotal(1000);
//最小空闲连接数, 默认0
jedisPoolConfig.setMinIdle(100);
// 获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, 默认-1
jedisPoolConfig.setMaxWaitMillis(3000); // 设置2秒
//对拿到的connection进行validateObject校验
jedisPoolConfig.setTestOnBorrow(false);
JedisCluster jedisCluster = new JedisCluster(nodesList,2000,2000,5,"123456",jedisPoolConfig);
while (true) {
try {
String s = UUID.randomUUID().toString();
jedisCluster.set("k" + s, "v" + s);
System.out.println(jedisCluster.get("k" + s));
Thread.sleep(1000);
}catch (Exception e) {
logger.error(e.getMessage());
}
}
}
}
每秒会往集群中写入一条记录,在写入数据过程中如果突然有一个主机挂了,那么这个主机所在子集群中的从机会自动上线成为新主机,挂了的主机自动下线,但是需要一定的时间开销,最后自动完成故障转移切换。
可通过kill 9 主机进程pid模拟关停一个redis主机,查看效果。
(七)总结?
1)rediscluster搭建集群:在redis5.0以上主要使用--cluster help帮助命令进行搭建;
2)集群扩容和缩容:扩容和缩容都涉及目标子集群槽位的转移,也会伴随对应槽位数据的转移,扩容和缩容要注意步骤;
3)故障转移:数据写入过程中如果有个别主机挂了,那么会自动进行故障转移,对应子集群的从机会上线成为主机继续提供服务,但是这个故障转移过程中数据将无法写入会造成数据丢失,机器性能越优越可以降低故障转移的时间,减少数据丢失。