Linux常用指令
Linux常用指令
- 查看帮助命令 man
- 常用系统工作命令
- reboot命令
- poweroff命令
- echo命令
- date命令--显示及设置系统的时间或日期
- wget命令--从指定的URL下载文件
- ps命令--报告当前系统的进程状态
- top命令--实时动态地查看系统的整体运行情况
- pidof命令--查询某个指定服务进程的PID值
- kill命令--终止某个指定PID的服务进程
- killall命令--终止某个指定名称的服务所对应的全部进程
- 系统状态检测命令
- ifconfig命令--用于获取网卡配置与网络状态等信息
- uname命令--查看系统内核与系统版本等信息
- uptime命令--查看系统负载信息
- free命令--显示内存的使用情况
- who命令--显示当前所有登陆用户的信息
- last命令--查看所有系统的登录记录
- history命令--显示历史执行过的命令
- 工作目录切换命令
- pwd命令--显示当前工作目录
- cd命令--切换工作目录
- ls命令--显示目录中的文件信息
- 文本文件编辑命令
- cat命令
- more命令--显示文件内容,每次显示一屏
- head命令--查看纯文本文档的前N行
- tail命令--在屏幕上显示指定文件的末尾若干行
- tr命令--将字符进行替换、压缩和删除
- wc命令--统计文件的字节数、字数、行数
- stat命令--查看文件的具体存储信息和时间等信息
- cut命令--按“列”提取文本字符
- diff命令--比较多个文本文件的差异
- 文件目录管理命令
- touch命令--创建空白文件或设置文件的时间
- mkdir命令--创建目录
- cp命令--将源文件或目录复制到目标文件或目录中
- mv命令--用于剪切文件或将文件重命名
- rm命令--删除文件或目录
- dd命令--按照指定大小和个数的数据块来复制文件或转换文件
- file命令--查看文件的类型
- 打包、压缩与搜索命令
- tar命令--对文件进行打包压缩或解压
- grep命令--在文本中执行关键词搜索
- find命令--按照指定条件来查找文件
- 用户管理
- useradd命令--创建的新的系统用户
- groupadd命令--创建一个新的工作组
- usermod命令--修改用户的基本信息
- passwd命令--修改用户密码、过期时间、认证信息等
- userdel命令--删除给定的用户
- 文件权限与归属
- chmod命令--变更文件或目录的权限
- 管道符、重定向与环境变量
- 输入输出重定向
- 管道命令符
- 命令行的通配符
- 常用的转义字符
- 重要的环境变量
- Vim编辑器
- Shell脚本

计算机硬件是由运算器、控制器、存储器、输入/输出设备等共同组成的,而让各种硬件设备各司其职且又能协同运行的东西就是系统内核。
查看帮助命令 man
man命令中常用按键以及用途如下表:
| 按键 | 用途 |
|---|---|
| 空格键 | 向下翻一页 |
| PaGe down | 向下翻一页 |
| PaGe up | 向上翻一页 |
| home | 直接前往首页 |
| end | 直接前往尾页 |
| / | 从上至下搜索某个关键词,如“/linux” |
| ? | 从下至上搜索某个关键词,如“?linux” |
| n | 定位到下一个搜索到的关键词 |
| N | 定位到上一个搜索到的关键词 |
| q | 退出帮助文档 |
man命令帮助信息的结构及意义如下表
| 结构名称 | 代表意义 |
|---|---|
| NAME | 命令的名称 |
| SYNOPSIS | 参数的大致使用方法 |
| DESCRIPTION | 介绍说明 |
| EXAMPLES | 演示(附带简单说明) |
| OVERVIEW | 概述 |
| DEFAULTS | 默认的功能 |
| OPTIONS | 具体的可用选项(带介绍) |
| ENVIRONMENT | 环境变量 |
| FILES | 用到的文件 |
| SEE ALSO | 相关的资料 |
| HISTORY | 维护历史与联系方式 |
常用系统工作命令
reboot命令
reboot用于重启系统。
poweroff命令
poweroff用于关闭系统。
echo命令
echo用于在终端输出字符串或变量提取后的值。格式为echo 字符串或echo $变量名.
![]()
![]()
date命令–显示及设置系统的时间或日期
date用于显示及设置系统的时间或日期。date命令中常见的参数格式及作用如下表所示:
| 参数 | 作用 |
|---|---|
| %t | 跳格[Tab键] |
| %H | 小时(00~23) |
| %I | 小时(00~12) |
| %M | 分钟(00~59) |
| %S | 秒(00~59) |
| %j | 今年中的第几天 |
![]()
当我们需要以指定格式输出时间和日期,可以以+开头配合上表中的参数使用来控制输出格式:
![]()
也可以使用date来设置系统时间:

wget命令–从指定的URL下载文件
wget用来从指定的URL下载文件。wget命令的参数以及作用如下表所示:
| 参数 | 作用 |
|---|---|
| -V | 显示wget的版本后退出 |
| -b | 启动后转入后台下载模式 |
| -P | 下载到指定目录 |
| -t | 最大尝试次数(0 表示无限制) |
| -c | 断点续传 |
| -p | 下载页面内所有资源,包括图片、视频等 |
| -r | 递归下载 |
所谓的自动下载是指,wget可以在用户退出系统的之后在后台执行。这意味这你可以登录系统,启动一个wget下载任务,然后退出系统,wget将在后台执行直到任务完成,相对于其它大部分浏览器在下载大量数据时需要用户一直的参与,这省去了极大的麻烦。
wget [参数] [URL地址]
使用wget下载单个文件:
wget http://www.example.com/example.zip
下载并以不同的文件名保存:
wget -O myname.zip http://www.example.com/download.aspx?id=1080
wget限速下载:
wget --limit-rate=300k http://www.example.com/example.zip
使用wget断点续传:
wget -c http://www.example.com/example.zip
使用wget -c重新启动下载中断的文件,对于我们下载大文件时突然由于网络等原因中断非常有帮助,我们可以继续接着下载而不是重新下载一个文件。需要继续中断的下载时可以使用-c参数。
使用wget后台下载:
wget -b http://www.example.com/example.zip
Continuing in background, pid 1840.
Output will be written to `wget-log'.
可以使用以下命令来察看下载进度:
tail -f wget-log
下载多个文件:
cat > filelist.txt
url1
url2
url3
url4
wget -i filelist.txt
递归下载:
使用wget命令递归下载www.example.com网站内的所有页面数据以及文件,下载完后会自动保存到当前路径下一个名为www.example.com的目录中。
wget -r -p http://www.example.com
ps命令–报告当前系统的进程状态
ps命令报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。通常会将ps命令与管道符技术搭配使用,用来抓取与某个指定服务进程相对应的PID号码.ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
ps(选项)
| 参数 | 作用 |
|---|---|
| -a | 显示所有进程(包括其他用户的进程) |
| -u | 用户以及其他详细信息 |
| -x | 显示没有控制终端的进程 |
在Linux系统中,有5种常见的进程状态,分别为运行、中断、不可中断、僵死与停止,其各自含义如下所示。
R(运行):进程正在运行或在运行队列中等待。S(中断):进程处于休眠中,当某个条件形成后或者接收到信号时,则脱离该 状态。D(不可中断):进程不响应系统异步信号,即便用kill命令也不能将其中断。Z(僵死):进程已经终止,但进程描述符依然存在, 直到父进程调用wait4()系统函数后将进程释放。T(停止):进程收到停止信号后停止运行。
ps -l目前属于您自己这次登入的 PID 与相关信息列示出来:

在预设的情况下, ps仅会列出与目前所在的 bash shell 有关的 PID 而已,所以, 当我使用 ps -l 的时候,只有三个 PID。ps aux列出目前所有的正在内存当中的程序:
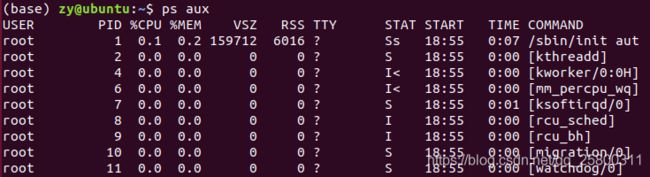
其中USER表示进程的所有者,PID表示进程的ID号,%CPU表示运算器占用率,%MEM表示内存占用率,VSZ表示虚拟内存使用量(单位:KB),RSS表示占用的固定内存量(单位:KB),TTY表示所在终端,STAT表示进程状态,START表示被启动的时间,TIME表示实际使用CPU的时间,COMMAND表示命令名称与参数。
ps axo pid,comm,pcpu # 查看进程的PID、名称以及CPU 占用率
ps aux | sort -rnk 4 # 按内存资源的使用量对进程进行排序
ps aux | sort -nk 3 # 按 CPU 资源的使用量对进程进行排序
ps -A # 显示所有进程信息
ps -u root # 显示指定用户信息
ps -efL # 查看线程数
ps -e -o "%C : %p :%z : %a"|sort -k5 -nr # 查看进程并按内存使用大小排列
ps -ef # 显示所有进程信息,连同命令行
ps -ef | grep ssh # ps 与grep 常用组合用法,查找特定进程
ps -C nginx # 通过名字或命令搜索进程
ps aux --sort=-pcpu,+pmem # CPU或者内存进行排序,-降序,+升序
ps -f --forest -C nginx # 用树的风格显示进程的层次关系
ps -o pid,uname,comm -C nginx # 显示一个父进程的子进程
ps -e -o pid,uname=USERNAME,pcpu=CPU_USAGE,pmem,comm # 重定义标签
ps -e -o pid,comm,etime # 显示进程运行的时间
ps -aux | grep named # 查看named进程详细信息
ps -o command -p 91730 | sed -n 2p # 通过进程id获取服务名称
top命令–实时动态地查看系统的整体运行情况
top命令 可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。
-b:以批处理模式操作;
-c:显示完整的治命令;
-d:屏幕刷新间隔时间;
-I:忽略失效过程;
-s:保密模式;
-S:累积模式;
-i<时间>:设置间隔时间;
-u<用户名>:指定用户名;
-p<进程号>:指定进程;
-n<次数>:循环显示的次数。
在top命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了-s选项, 其中一些命令可能会被屏蔽。
h:显示帮助画面,给出一些简短的命令总结说明;
k:终止一个进程;
i:忽略闲置和僵死进程,这是一个开关式命令;
q:退出程序;
r:重新安排一个进程的优先级别;
S:切换到累计模式;
s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
f或者F:从当前显示中添加或者删除项目;
o或者O:改变显示项目的顺序;
l:切换显示平均负载和启动时间信息;
m:切换显示内存信息;
t:切换显示进程和CPU状态信息;
c:切换显示命令名称和完整命令行;
M:根据驻留内存大小进行排序;
P:根据CPU使用百分比大小进行排序;
T:根据时间/累计时间进行排序;
w:将当前设置写入~/.toprc文件中。
一个实例分析:
top - 09:44:56 up 16 days, 21:23, 1 user, load average: 9.59, 4.75, 1.92
Tasks: 145 total, 2 running, 143 sleeping, 0 stopped, 0 zombie
Cpu(s): 99.8%us, 0.1%sy, 0.0%ni, 0.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 4147888k total, 2493092k used, 1654796k free, 158188k buffers
Swap: 5144568k total, 56k used, 5144512k free, 2013180k cached
解释如下:
- top - 09:44:56[当前系统时间],
- 16 days[系统已经运行了16天],
- 1 user[个用户当前登录],
- load average: 9.59, 4.75, 1.92[系统负载,即任务队列的平均长度]
- Tasks: 145 total[总进程数],
- 2 running[正在运行的进程数],
- 143 sleeping[睡眠的进程数],
- 0 stopped[停止的进程数],
- 0 zombie[冻结进程数],
- Cpu(s): 99.8%us[用户空间占用CPU百分比],
- 0.1%sy[内核空间占用CPU百分比],
- 0.0%ni[用户进程空间内改变过优先级的进程占用CPU百分比],
- 0.2%id[空闲CPU百分比], 0.0%wa[等待输入输出的CPU时间百分比],
- 0.0%hi[],
- 0.0%st[],
- Mem: 4147888k total[物理内存总量],
- 2493092k used[使用的物理内存总量],
- 1654796k free[空闲内存总量],
- 158188k buffers[用作内核缓存的内存量]
- Swap: 5144568k total[交换区总量],
- 56k used[使用的交换区总量],
- 5144512k free[空闲交换区总量],
- 2013180k cached[缓冲的交换区总量],
pidof命令–查询某个指定服务进程的PID值
每个进程的进程号码值(PID)是唯一的,因此可以通过PID来区分不同的进程。pidof命令 用于查找指定名称的进程的进程号id号。
pidof(选项)(参数)
选项:
-s:仅返回一个进程号;
-c:仅显示具有相同“root”目录的进程;
-x:显示由脚本开启的进程;
-o:指定不显示的进程ID。
查询本机上sshd服务的PID:
![]()
kill命令–终止某个指定PID的服务进程
kill命令用于终止某个指定PID的服务进程,可与pidof配合使用。
pidof(选项)(进程PID)

killall命令–终止某个指定名称的服务所对应的全部进程
复杂软件的服务程序会有多个进程协同为用户提供服务,如果逐个去结束这些进程会比较麻烦,此时可以使用killall命令来批量结束某个服务程序带有的全部进程。
pidof(选项)(服务名称)

系统状态检测命令
ifconfig命令–用于获取网卡配置与网络状态等信息
ifconfig命令 被用于配置和显示Linux内核中网络接口的网络参数。用ifconfig命令配置的网卡信息,在网卡重启后机器重启后,配置就不存在。要想将上述的配置信息永远的存的电脑里,修改网卡的配置文件。
使用ifconfig命令来查看本机当前的网卡配置与网络状态等信息时,其实主要查看的就是网卡名称、inet参数后面的IP地址、ether参数后面的网卡物理地址(又称为MAC地址),以及RX、TX的接收数据包与发送数据包的个数及累计流量。
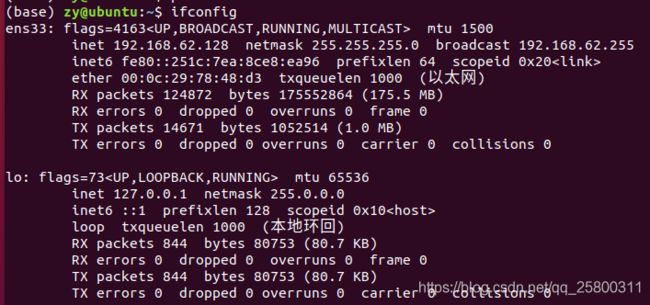
ens33表示第一块网卡。
lo是表示主机的回坏地址,这个一般是用来测试一个网络程序,但又不想让局域网或外网的用户能够查看,只能在此台主机上运行和查看所用的网络接口。比如把 httpd服务器指定到回坏地址,在浏览器输入127.0.0.1就能看到你所架WEB网站了。但只是您能看得到,局域网的其它主机或用户无从知道。
uname命令–查看系统内核与系统版本等信息
uname [OPTION]...
- 当没有选项时,默认启用 -s 选项。
- 如果给出多个选项或 -a 选项时,输出信息按以下字段排序:内核名称 主机名称 内核release 内核版本 机器名称 处理器 硬件平台 操作系统。
-a, --all 按顺序打印全部信息,如果 -p 和 -i 的信息是未知,那么省略。
-s, --kernel-name 打印内核名称。
-n, --nodename 打印网络节点主机名称。
-r, --kernel-release 打印内核release。
-v, --kernel-version 打印内核版本。
-m, --machine 打印机器名称。
-p, --processor 打印处理器名称。
-i, --hardware-platform 打印硬件平台名称。
-o, --operating-system 打印操作系统名称。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
一般会固定搭配上-a参数来完整地查看当前系统的内核名称、主机名、内核发行版本、节点名、系统时间、硬件名称、硬件平台、处理器类型以及操作系统名称等信息。
![]()
uptime命令–查看系统负载信息
uptime命令 能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
![]()
什么是系统平均负载呢? 系统平均负载是指在特定时间间隔内运行队列中的平均进程数。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的。如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
free命令–显示内存的使用情况
free命令 可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
-b # 以Byte为单位显示内存使用情况;
-k # 以KB为单位显示内存使用情况;
-m # 以MB为单位显示内存使用情况;
-g # 以GB为单位显示内存使用情况。
-o # 不显示缓冲区调节列;
-s<间隔秒数> # 持续观察内存使用状况;
-t # 显示内存总和列;
-V # 显示版本信息。
free -m
total used free shared buffers cached
Mem: 2016 1973 42 0 163 1497
-/+ buffers/cache: 312 1703
Swap: 4094 0 4094
total:内存总数;
used:已经使用的内存数;
free:空闲的内存数;
shared:当前已经废弃不用;
buffers Buffer:缓存内存数;
cached Page:缓存内存数。
关系:total = used + free
who命令–显示当前所有登陆用户的信息
who [OPTION]... [file] [am i]
- 当没有给出非选项参数时,按以下字段顺序为每个当前用户打印信息:登录用户名称,终端信息,登录时间,远程主机或·X display。
- 当用户执行
who am i时,只显示运行该命令的用户的信息。
![]()
last命令–查看所有系统的登录记录
last命令 用于显示用户最近登录信息。单独执行last命令,它会读取/var/log/wtmp的文件,并把该文件记录的登入系统的用户名单全部显示出来。
last(选项)(参数)
-a:把从何处登入系统的主机名称或ip地址,显示在最后一行;
-d:将IP地址转换成主机名称;
-f <记录文件>:指定记录文件。
-n <显示列数>或-<显示列数>:设置列出名单的显示列数;
-R:不显示登入系统的主机名称或IP地址;
-x:显示系统关机,重新开机,以及执行等级的改变等信息。
last
root pts/0 :0 Mon Aug 24 17:52 still logged in
root :0 :0 Mon Aug 24 17:52 still logged in
(unknown :0 :0 Mon Aug 24 17:50 - 17:52 (00:02)
reboot system boot 3.10.0-123.el7.x Tue Aug 25 01:49 - 18:17 (-7:-32)
root pts/0 :0 Mon Aug 24 15:40 - 08:54 (7+17:14)
root pts/0 :0 Fri Jul 10 10:49 - 15:37 (45+04:47)
………………省略部分登录信息………………
history命令–显示历史执行过的命令
使用history命令显示最近使用的10条历史命令:
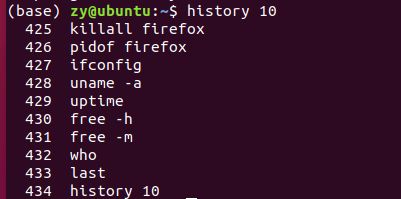
清空历史记录:
history -c
执行第 n 条历史命令:
!n

执行最后一条 xxx 开头的命令:
!xxx
历史命令会被保存到用户家目录中的.bash_history文件中。Linux系统中以点(.)开头的文件均代表隐藏文件,这些文件大多数为系统服务文件,可以用cat命令查看其文件内容。
cat ~/.bash_history
工作目录切换命令
pwd命令–显示当前工作目录
![]()
cd命令–切换工作目录
cd / # 进入根目录
cd ~ # 进入用户主目录;
cd .. # 返回上级目录(若当前目录为“/“,则执行完后还在“/";".."为上级目录的意思);
cd ../.. # 返回上两级目录;
cd !$ # 把上个命令的参数作为cd参数使用。
ls命令–显示目录中的文件信息
ls # 仅列出当前目录可见文件
ls -l # 列出当前目录可见文件详细信息
ls -hl # 列出详细信息并以可读大小显示文件大小
ls -al # 列出所有文件(包括隐藏)的详细信息
文本文件编辑命令
cat命令
# 合并显示多个文件
cat ./1.log ./2.log ./3.log
# 显示文件中的非打印字符、tab、换行符
cat -A test.log
# 压缩文件的空行
cat -s test.log
# 显示文件并在所有行开头附加行号
cat -n test.log
# 显示文件并在所有非空行开头附加行号
cat -b test.log
# 将标准输入的内容和文件内容一并显示
echo '######' |cat - test.log
more命令–显示文件内容,每次显示一屏
more命令用于查看纯文本文件(内容较多的),more命令 是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)。
该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比:--More--(XX%)可以用下列不同的方法对提示做出回答:
- 按
Space键:显示文本的下一屏内容。 - 按
Enter键:只显示文本的下一行内容。 - 按斜线符
|:接着输入一个模式,可以在文本中寻找下一个相匹配的模式。 - 按
H键:显示帮助屏,该屏上有相关的帮助信息。 - 按
B键:显示上一屏内容。 - 按
Q键:退出more命令。
选项:
-<数字>:指定每屏显示的行数;
-d:显示“[press space to continue,'q' to quit.]”和“[Press 'h' for instructions]”;
-c:不进行滚屏操作。每次刷新这个屏幕;
-s:将多个空行压缩成一行显示;
-u:禁止下划线;
+<数字>:从指定数字的行开始显示。
显示文件file的内容,但在显示之前先清屏,并且在屏幕的最下方显示完成的百分比:
more -dc file
显示文件file的内容,每10行显示一次,而且在显示之前先清屏:
more -c -10 file
head命令–查看纯文本文档的前N行
head [OPTION]... [FILE]...
- 在未指定行数时默认显示前10行。
- 处理多个文件时会在各个文件之前附加含有文件名的行。
- 当没有文件或文件为
-时,读取标准输入。
查看文件的前5行:

tail命令–在屏幕上显示指定文件的末尾若干行
tail命令默认在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
注意:如果表示字节或行数的N值之前有一个”+”号,则从文件开头的第N项开始显示,而不是显示文件的最后N项。N值后面可以有后缀:b表示512,k表示1024,m表示1 048576(1M)。
显示文件的最后3行:

tail file #(显示文件file的最后10行)
tail -n +20 file #(显示文件file的内容,从第20行至文件末尾)
tail -c 10 file #(显示文件file的最后10个字符)
tail -25 mail.log # 显示 mail.log 最后的 25 行
tail -f mail.log # 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F mail.log # 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
tail命令最强悍的功能是可以持续刷新一个文件的内容,当想要实时查看最新日志文件时,这特别有用,此时的命令格式为“tail -f 文件名”:
# tail -f /var/log/messages
May 4 07:56:38 localhost gnome-session: Window manager warning: Log level 16:
STACK_OP_ADD: window 0x1e00001 already in stack
May 4 07:56:38 localhost gnome-session: Window manager warning: Log level 16:
STACK_OP_ADD: window 0x1e00001 already in stack
May 4 07:56:38 localhost vmusr[12982]: [ warning] [Gtk] gtk_disable_setlocale()
must be called before gtk_init()
May 4 07:56:50 localhost systemd-logind: Removed session c1.
Aug 1 01:05:31 localhost systemd: Time has been changed
Aug 1 01:05:31 localhost systemd: Started LSB: Bring up/down networking.
Aug 1 01:08:56 localhost dbus-daemon: dbus[1124]: [system] Activating service
name='com.redhat.SubscriptionManager' (using servicehelper)
Aug 1 01:08:56 localhost dbus[1124]: [system] Activating service name='com.
redhat.SubscriptionManager' (using servicehelper)
Aug 1 01:08:57 localhost dbus-daemon: dbus[1124]: [system] Successfully activated
service 'com.redhat.SubscriptionManager'
Aug 1 01:08:57 localhost dbus[1124]: [system] Successfully activated service '
com.redhat.SubscriptionManager'
tr命令–将字符进行替换、压缩和删除
tr(选项)(参数)
选项:
-c或——complerment:取代所有不属于第一字符集的字符;
-d或——delete:删除所有属于第一字符集的字符;
-s或--squeeze-repeats:把连续重复的字符以单独一个字符表示;
-t或--truncate-set1:先删除第一字符集较第二字符集多出的字符。
参数:
- 字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”;
- 字符集2:指定要转换成的目标字符集。
tr可以使用的字符类:
[:alnum:]:字母和数字
[:alpha:]:字母
[:cntrl:]:控制(非打印)字符
[:digit:]:数字
[:graph:]:图形字符
[:lower:]:小写字母
[:print:]:可打印字符
[:punct:]:标点符号
[:space:]:空白字符
[:upper:]:大写字母
[:xdigit:]:十六进制字符
使用方式:
tr '[:lower:]' '[:upper:]'
实例:
将输入字符由大写转换为小写:
![]()
![]()
使用tr删除指定字符:
![]()
将制表符转换为空格:
cat example.txt| tr '\t' ' '
字符集补集,从输入文本中将不在补集中的所有字符删除:
![]()
此例中,补集中包含了数字0~9、空格和换行符\n,所以没有被删除,其他字符全部被删除了。
用tr压缩字符,可以压缩输入中重复的字符:
![]()
wc命令–统计文件的字节数、字数、行数
wc的参数以及作用如下表:
| 参数 | 作用 |
|---|---|
| -l | 只显示行数 |
| -w | 只显示单词数 |
| -c | 只显示字节数 |
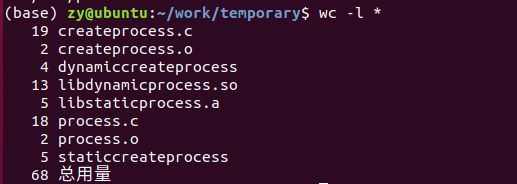
wc -l * # 统计当前目录下的所有文件行数及总计行数。
wc -l *.js # 统计当前目录下的所有 .js 后缀的文件行数及总计行数。
find . * | xargs wc -l # 当前目录以及子目录的所有文件行数及总计行数。
stat命令–查看文件的具体存储信息和时间等信息
stat命令 用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。
-L:支持符号连接;
-f:显示文件系统状态而非文件状态;
-t:以简洁方式输出信息;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
[root@localhost ~]# ls -l myfile
-rw-r--r-- 1 root root 0 2010-10-09 myfile
[root@localhost ~]# stat myfile
file: “myfile”
Size: 0 Blocks: 8 IO Block: 4096 一般空文件
Device: fd00h/64768d Inode: 194805815 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2010-12-12 12:22:35.000000000 +0800
Modify: 2010-10-09 20:44:21.000000000 +0800
Change: 2010-10-09 20:44:21.000000000 +0800
[root@localhost ~]# stat -f myfile
File: "myfile"
id: 0 Namelen: 255 type: ext2/ext3
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 241555461 free: 232910771 Available: 220442547
Inodes: Total: 249364480 Free: 249139691
[root@localhost ~]# stat -t myfile
myfile 0 8 81a4 0 0 fd00 194805815 1 0 0 1292127755 1286628261 1286628261 4096
cut命令–按“列”提取文本字符
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter= 字段分隔符:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
[root@localhost text]# cut -f 1 test.txt
No
01
02
03
[root@localhost text]# cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
[root@localhost text]# cut -f2 --complement test.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
[root@localhost text]# cat test2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@localhost text]# cut -f2 -d";" test2.txt
Name
tom
jack
alex
指定字段的字符或者字节范围
cut 命令可以将一串字符作为列来显示,字符字段的记法:
-
N-:从第 N 个字节、字符、字段到结尾; -
N-M:从第 N 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、字段; -
-M:从第 1 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、字段。
上面是记法,结合下面选项将摸个范围的字节、字符指定为字段: -
-b表示字节; -
-c表示字符; -
-f表示定义字段。
[root@localhost text]# cat test.txt
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
[root@localhost text]# cut -c1-3 test.txt
abc
abc
abc
abc
abc
[root@localhost text]# cut -c-2 test.txt
ab
ab
ab
ab
ab
[root@localhost text]# cut -c5- test.txt
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
diff命令–比较多个文本文件的差异
在使用diff命令时,不仅可以使用--brief参数来确认两个文件是否不同,还可以使用-c参数来详细比较出多个文件的差异之处,这绝对是判断文件是否被篡改的有力神器。
# diff --brief diff_A.txt diff_B.txt
Files diff_A.txt and diff_B.txt differ
文件目录管理命令
touch命令–创建空白文件或设置文件的时间
touch命令 有两个功能:一是用于把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来;二是用来创建新的空文件。
touch命令的参数及其作用如下表:
| 参数 | 作用 |
|---|---|
| -a | 仅修改“读取时间”(atime) |
| -m | 仅修改“修改时间”(mtime) |
| -d | 同时修改atime与mtime |
touch -d "2020-05-20 15:44" example
mkdir命令–创建目录
除了能创建单个空白目录外,mkdir命令还可以结合-p参数来递归创建出具有嵌套叠层关系的文件目录。
在目录/usr/zy下建立子目录test,并且只有文件主有读、写和执行权限,其他人无权访问:
mkdir -m 700 /usr/zy/test
mkdir -p a/b/c/d/e
cp命令–将源文件或目录复制到目标文件或目录中
在Linux系统中,复制操作具体分为3种情况:
- 如果目标文件是目录,则会把源文件复制到该目录中;
- 如果目标文件也是普通文件,则会询问是否要覆盖它;
- 如果目标文件不存在,则执行正常的复制操作。
| 参数 | 作用 |
|---|---|
| -p | 保留原始文件的属性 |
| -d | 若对象为“链接文件”,则保留该“链接文件”的属性 |
| -r | 递归持续复制(用于目录) |
| -i | 若目标文件存在则询问是否覆盖 |
| -a | 相当于-pdr(p、d、r为上述参数) |
将目录/usr/a下的所有文件及其子目录复制到目录/usr/b中
cp -r /usr/a/usr/b
cp a.log b.log
mv命令–用于剪切文件或将文件重命名
mv命令 用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。source表示源文件或目录,target表示目标文件或目录。如果将一个文件移到一个已经存在的目标文件中,则目标文件的内容将被覆盖。
mv a.log b.log
rm命令–删除文件或目录
rm 命令 可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉。对于链接文件,只是删除整个链接文件,而原有文件保持不变。
交互式删除当前目录下的文件test和example:
rm -i test example
Remove test ?n(不删除文件test)
Remove example ?y(删除文件example)
删除当前目录下除隐含文件外的所有文件和子目录:
# rm -r *
rm -r [目录名称] -r 表示递归地删除目录下的所有文件和目录。-f表示强制删除
rm -rf testdir
rm -r testdir
dd命令–按照指定大小和个数的数据块来复制文件或转换文件
dd命令的参数及其作用如下表:
| 参数 | 作用 |
|---|---|
| if | 输入的文件名称 |
| of | 输出的文件名称 |
| bs | 设置每个“块”的大小 |
| count | 设置要复制“块”的个数 |
bs与count都是用来指定容量的大小,只要能满足需求,可随意组合搭配方式。
Linux系统中有一个名为/dev/zero的设备文件,这个文件不会占用系统存储空间,但却可以提供无穷无尽的数据,因此可以使用它作为dd命令的输入文件,来生成一个指定大小的文件:
# dd if=/dev/zero of=560_file count=1 bs=560M
1+0 records in
1+0 records out
587202560 bytes (587 MB) copied, 27.1755 s, 21.6 MB/s
在Linux系统中可以直接使用dd命令来压制出光盘镜像文件,将它变成一个可立即使用的iso镜像:
# dd if=/dev/cdrom of=example.iso
7311360+0 records in
7311360+0 records out
3743416320 bytes (3.7 GB) copied, 370.758 s, 10.1 MB/s
file命令–查看文件的类型
[root@localhost ~]# file install.log
install.log: UTF-8 Unicode text
[root@localhost ~]# file -b install.log <== 不显示文件名称
UTF-8 Unicode text
[root@localhost ~]# file -i install.log <== 显示MIME类别。
install.log: text/plain; charset=utf-8
[root@localhost ~]# file -b -i install.log
text/plain; charset=utf-8
打包、压缩与搜索命令
tar命令–对文件进行打包压缩或解压
tar命令的参数及其作用:
| 参数 | 作用 |
|---|---|
| -c | 压缩文件 |
| -x | 解压文件 |
| -t | 查看压缩包内有哪些文件 |
| -z | 用Gzip压缩或解压 |
| -j | 用bzip2压缩或解压 |
| -v | 显示压缩或解压的过程 |
| -f | 目标文件名 |
| -p | 保留原始的权限与属性 |
| -P | 使用绝对路径来压缩 |
| -C | 指定解压到的目录 |
-f参数特别重要,它必须放到参数的最后一位,代表要压缩或解压的软件包名称
压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查 询:tar -jtv -f filename.tar.bz2
解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
grep命令–在文本中执行关键词搜索
grep命令的参数及其作用:
| 参数 | 作用 |
|---|---|
| -b | 将可执行文件(binary)当作文本文件(text)来搜索 |
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择—仅列出没有“关键词”的行 |
规则表达式
^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ # 锚定行的结束 如:'grep$' 匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。
[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) # 标记匹配字符,如'\(love\)',love被标记为1。
\< # 锚定单词的开始,如:'\
\> # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} # 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} # 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} # 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W # \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b # 单词锁定符,如: '\bgrep\b'只匹配grep。
grep "match_pattern" file_name
输出除匹配match_pattern之外的所有行 -v 选项:
grep -v "match_pattern" file_name
标记匹配颜色 --color=auto 选项:
grep "match_pattern" file_name --color=auto
使用正则表达式 -P 选项:
grep -P "(\d{3}\-){2}\d{4}" file_name
find命令–按照指定条件来查找文件
find命令可以使用不同的文件特性作为寻找条件(如文件名、大小、修改时间、权限等信息),一旦匹配成功则默认将信息显示到屏幕上。
find [查找路径] 寻找条件 操作
find命令中的参数以及作用:
| 参数 | 作用 |
|---|---|
| -name | 匹配名称 |
| -perm | 匹配权限(mode为完全匹配,-mode为包含即可) |
| -user | 匹配所有者 |
| -group | 匹配所有组 |
| -mtime -n +n | 匹配修改内容的时间(-n指n天以内,+n指n天以前) |
| -atime -n +n | 匹配访问文件的时间(-n指n天以内,+n指n天以前) |
| -ctime -n +n | 匹配修改文件权限的时间(-n指n天以内,+n指n天以前) |
| -nouser | 匹配无所有者的文件 |
| -nogroup | 匹配无所有组的文件 |
| -newer f1 !f2 | 匹配比文件f1新但比f2旧的文件 |
| –type b/d/c/p/l/f | 匹配文件类型(后面的字母参数依次表示块设备、目录、字符设备、管道、链接文件、文本文件) |
| -size | 匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50KB的文件) |
| -prune | 忽略某个目录 |
| -exec …… {}; | 后面可跟用于进一步处理搜索结果的命令(下文会有演示) |
这里需要重点关注一下-exec参数重要的作用。这个参数用于把find命令搜索到的结果交由紧随其后的命令作进一步处理,它十分类似于第3章将要讲解的管道符技术,并且由于find命令对参数的特殊要求,因此虽然exec是长格式形式,但依然只需要一个减号(-)。
示例
获取到/etc目录中所有以host开头的文件列表:
find /etc -name "host*" -print
在整个系统中搜索权限中包括SUID权限的所有文件:
find / -perm -4000 -print
在整个文件系统中找出所有归属于name用户的文件并复制到/root/findresults目录:
find / -user name -exec cp -a {} /root/findresults/ ;
用户管理
useradd命令–创建的新的系统用户
useradd命令 用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
| 参数 | 作用 |
|---|---|
| -d | 指定用户的家目录(默认为/home/username) |
| -e | 账户的到期时间,格式为YYYY-MM-DD. |
| -u | 指定该用户的默认UID |
| -g | 指定一个初始的用户基本组(必须已存在) |
| -G | 指定一个或多个扩展用户组 |
| -N | 不创建与用户同名的基本用户组 |
| -s | 指定该用户的默认Shell解释器 |
useradd –g sales jack –G company -u 544 zy //-g:加入主要组、-G:加入次要组
groupadd命令–创建一个新的工作组
groupadd命令 用于创建一个新的工作组,新工作组的信息将被添加到系统文件中。
-g:指定新建工作组的id;
-r:创建系统工作组,系统工作组的组ID小于500;
-K:覆盖配置文件“/ect/login.defs”;
-o:允许添加组ID号不唯一的工作组。
groupadd -g 344 gname
usermod命令–修改用户的基本信息
usermod命令 用于修改用户的基本信息。usermod命令不允许你改变正在线上的使用者帐号名称。当 usermod 命令用来改变user id,必须确认这名user没在电脑上执行任何程序。
| 参数 | 作用 |
|---|---|
| -c | 填写用户账户的备注信息 |
| -d -m | 参数-m与参数-d连用,可重新指定用户的家目录并自动把旧的数据转移过去 |
| -e | 账户的到期时间,格式为YYYY-MM-DD |
| -g | 变更所属用户组 |
| -G | 变更扩展用户组 |
| -L | 锁定用户禁止其登录系统 |
| -U | 解锁用户,允许其登录系统 |
| -s | 变更默认终端 |
| -u | 修改用户的UID |
实例
将 newuser2 添加到组 staff 中:
usermod -G staff newuser2
修改newuser的用户名为newuser1:
usermod -l newuser1 newuser
锁定账号newuser1:
usermod -L newuser1
解除对newuser1的锁定:
usermod -U newuser1
passwd命令–修改用户密码、过期时间、认证信息等
passwd命令 用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
| 参数 | 作用 |
|---|---|
| -l | 锁定用户,禁止其登录 |
| -u | 解除锁定,允许用户登录 |
| –stdin | 允许通过标准输入修改用户密码,如echo “NewPassWord” |
| -d | 使该用户可用空密码登录系统 |
| -e | 强制用户在下次登录时修改密码 |
| -S | 显示用户的密码是否被锁定,以及密码所采用的加密算法名称 |
# passwd linuxprobe
Changing password for user linuxprobe.
New password: 此处输入密码值
Retype new password: 再次输入进行确认
passwd: all authentication tokens updated successfully.
userdel命令–删除给定的用户
userdel命令 用于删除给定的用户,以及与用户相关的文件。若不加选项,则仅删除用户帐号,而不删除相关文件。
-f:强制删除用户,即使用户当前已登录;
-r:删除用户的同时,删除与用户相关的所有文件。
userdel linuxuser # 删除用户linuxuser,但不删除其家目录及文件;
userdel -r linuxuser # 删除用户linuxuser,其家目录及文件一并删除;
文件权限与归属
Linux系统中一切都是文件,但是每个文件的类型不尽相同,因此Linux系统使用了不同的字符来加以区分,常见的字符如下所示:
- -:普通文件。
- d:目录文件。
- l:链接文件。
- b:块设备文件。
- c:字符设备文件。
- p:管道文件。
每个文件都有所属的所有者和所有组,并且规定了文件的所有者、所有组以及其他人对文件所拥有的可读(r)、可写(w)、可执行(x)等权限。
对于一般文件来说,权限比较容易理解。对目录文件来说,“可读”表示能够读取目录内的文件列表;“可写”表示能够在目录内新增、删除、重命名文件;而“可执行”则表示能够进入该目录。
文件的读、写、执行权限可以简写为rwx,亦可分别用数字4、2、1来表示,文件所有者,所属组及其他用户权限之间无关联。文件权限的数字法表示基于字符表示(rwx)的权限计算而来,其目的是简化权限的表示。例如,若某个文件的权限为7则代表可读、可写、可执行(4+2+1);若权限为6则代表可读、可写(4+2)。现在有这样一个文件,其所有者拥有可读、可写、可执行的权限,其文件所属组拥有可读、可写的权限;而且其他人只有可读的权限。那么,这个文件的权限就是rwxrw-r--,数字法表示即为764。

上图包含了文件的类型、访问权限、所有者(属主)、所属组(属组)、占用的磁盘大小、修改时间和文件名称等信息。所有者权限为可读、可写(rw-),所属组权限为可读(r--),除此以外的其他人也只有可读权限(r--),文件的磁盘占用大小是34298字节,最近一次的修改时间为4月2日的凌晨23分,文件的名称为install.log。
chmod命令–变更文件或目录的权限
chmod [OPTION]... MODE[,MODE]... FILE... #通过符号组合的方式更改目标文件或目录的权限。
chmod [OPTION]... OCTAL-MODE FILE... #通过八进制数的方式更改目标文件或目录的权限。
chmod [OPTION]... --reference=RFILE FILE... #通过参考文件的权限来更改目标文件或目录的权限。
选项:
-c, --changes:当文件的权限更改时输出操作信息。
--no-preserve-root:不将'/'特殊化处理,默认选项。
--preserve-root:不能在根目录下递归操作。
-f, --silent, --quiet:抑制多数错误消息的输出。
-v, --verbose:无论文件是否更改了权限,一律输出操作信息。
--reference=RFILE:使用参考文件或参考目录RFILE的权限来设置目标文件或目录的权限。
-R, --recursive:对目录以及目录下的文件递归执行更改权限操作。
--help:显示帮助信息并退出。
--version:显示版本信息并退出。
参数
-
mode:八进制数或符号组合。 -
file:指定要更改权限的一到多个文件。
符号含义
u符号代表当前用户。g符号代表和当前用户在同一个组的用户,以下简称组用户。o符号代表其他用户。a符号代表所有用户。r符号代表读权限以及八进制数4。w符号代表写权限以及八进制数2。x符号代表执行权限以及八进制数1。X符号代表如果目标文件是可执行文件或目录,可给其设置可执行权限。s符号代表设置权限suid和sgid,使用权限组合u+s设定文件的用户的ID位,g+s设置组用户ID位。t符号代表只有目录或文件的所有者才可以删除目录下的文件。+符号代表添加目标用户相应的权限。-符号代表删除目标用户相应的权限。=符号代表添加目标用户相应的权限,删除未提到的权限。
# 添加组用户的写权限。
chmod g+w ./test.log
# 删除其他用户的所有权限。
chmod o= ./test.log
# 使得所有用户都没有写权限。
chmod a-w ./test.log
# 当前用户具有所有权限,组用户有读写权限,其他用户只有读权限。
chmod u=rwx, g=rw, o=r ./test.log
# 等价的八进制数表示:
chmod 754 ./test.log
# 将目录以及目录下的文件都设置为所有用户拥有读写权限。
# 注意,使用'-R'选项一定要保留当前用户的执行和读取权限,否则会报错!
chmod -R a=rw ./testdir/
# 根据其他文件的权限设置文件权限。
chmod --reference=./1.log ./test.log
注意:
-
符号连接的权限无法变更,如果用户对符号连接修改权限,其改变会作用在被连接的原始文件。
-
使用
-R选项一定要保留当前用户的执行和读取权限,否则会报错!
管道符、重定向与环境变量
输入输出重定向
输入重定向是指把文件导入到命令中,而输出重定向则是指把原本要输出到屏幕的数据信息写入到指定文件中。
输出重定向分为了标准输出重定向和错误输出重定向两种不同的技术,以及清空写入与追加写入两种模式。
- 标准输入重定向(STDIN,文件描述符为0):默认从键盘输入,也可从其他文件或命令中输入。
- 标准输出重定向(STDOUT,文件描述符为1):默认输出到屏幕。
- 错误输出重定向(STDERR,文件描述符为2):默认输出到屏幕。
输入重定向中用到的符号及其作用:
| 符号 | 作用 |
|---|---|
| 命令 < 文件 | 将文件作为命令的标准输入 |
| 命令 << 分界符 | 从标准输入中读入,直到遇见分界符才停止 |
| 命令 < 文件1 > 文件2 | 将文件1作为命令的标准输入并将标准输出到文件2 |
输出重定向中用到的符号及其作用:
| 符号 | 作用 |
|---|---|
| 命令 > 文件 | 将标准输出重定向到一个文件中(清空原有文件的数据) |
| 命令 2> 文件 | 将错误输出重定向到一个文件中(清空原有文件的数据) |
| 命令 >> 文件 | 将标准输出重定向到一个文件中(追加到原有内容的后面) |
| 命令 2>> 文件 | 将错误输出重定向到一个文件中(追加到原有内容的后面) |
| 命令 >> 文件 2>&1 或 命令 &>> 文件 | 将标准输出与错误输出共同写入到文件中(追加到原有内容的后面) |
对于重定向中的标准输出模式,可以省略文件描述符1不写,而错误输出模式的文件描述符2是必须要写的。
# man bash > readme.txt
# cat readme.txt
BASH(1) General Commands Manual BASH(1)
NAME
bash - GNU Bourne-Again SHell
SYNOPSIS
bash [options] [file]
COPYRIGHT
Bash is Copyright (C) 1989-2011 by the Free Software Foundation, Inc.
DESCRIPTION
Bash is an sh-compatible command language interpreter that executes
commands read from the standard input or from a file. Bash also incor‐
porates useful features from the Korn and C shells (ksh and csh).
Bash is intended to be a conformant implementation of the Shell and
Utilities portion of the IEEE POSIX specification (IEEE Standard
1003.1). Bash can be configured to be POSIX-conformant by default.
………………省略部分输出信息………………
首先通过覆盖写入模式向readme.txt文件写入一行数据,然后再通过追加写入模式向文件再写入一次数据,其命令如下:

将命令的报错信息写入到文件:
# ls -l xxxxxx
cannot access xxxxxx: No such file or directory
# ls -l xxxxxx > /root/stderr.txt
cannot access xxxxxx: No such file or directory
# ls -l xxxxxx 2> /root/stderr.txt
# cat /root/stderr.txt
ls: cannot access xxxxxx: No such file or directory
使用输入重定向把readme.txt文件导入给wc -l命令,统计一下文件中的内容行数。
# wc -l < readme.txt
2
管道命令符
命令A | 命令B
将前一个命令原本要输出到屏幕的标准正常数据当作是后一个命令的标准输入。
例如可以通过如下命令来统计被限制登陆的用户数:
grep "/sbin/nologin" /etc/passwd | wc -l
用翻页的形式查看/etc目录中的文件列表及属性信息:
ls -l /etc/ | more
管道命令符可以在一个命令组合中多次使用:
“命令A | 命令B | 命令C”
命令行的通配符
通配符就是通用的匹配信息的符号,比如星号(*)代表匹配零个或多个字符,问号(?)代表匹配单个字符,中括号内加上数字[0-9]代表匹配0~9之间的单个数字的字符,而中括号内加上字母[abc]则是代表匹配a、b、c三个字符中的任意一个字符。
查看所有在/dev目录中且以sda开头的文件信息:
ls -l /dev/sda*
只想查看文件名为sda开头,但是后面还紧跟其他某一个字符的文件的相关信息:
ls -l /dev/sda?
除了使用[0-9]来匹配0~9之间的单个数字,也可以用[135]这样的方式仅匹配这三个指定数字中的一个:
ls -l /dev/sda[0-9]
ls -l /dev/sda[135]
常用的转义字符
4个最常用的转义字符如下:
- 反斜杠(\):使反斜杠后面的一个变量变为单纯的字符串。
- 单引号(’’):转义其中所有的变量为单纯的字符串。
- 双引号(""):保留其中的变量属性,不进行转义处理。
- 反引号(``):把其中的命令执行后返回结果。
重要的环境变量
Linux系统中的环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的家目录、邮件存放位置等。
例如用户输入命令时,如果是内部命令,会被直接执行。而如果是外部命令,系统会在PATH中存储的多个路径中查找用户输入的命令文件。PATH是由多个路径值组成的变量,每个路径值之间用冒号间隔。
# echo $PATH
/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin
可以使用env命令来查看Linux系统中的所有环境变量。下表列出了一些重要的环境变量:
| 变量名称 | 作用 |
|---|---|
| HOME | 用户的主目录(即家目录) |
| SHELL | 用户在使用的Shell解释器名称 |
| HISTSIZE | 输出的历史命令记录条数 |
| HISTFILESIZE | 保存的历史命令记录条数 |
| 邮件保存路径 | |
| LANG | 系统语言、语系名称 |
| RANDOM | 生成一个随机数字 |
| PS1 | Bash解释器的提示符 |
| PATH | 定义解释器搜索用户执行命令的路径 |
| EDITOR | 用户默认的文本编辑器 |
由于Linux系统是一个多用户多任务操作系统,能够为每个用户提供独立的工作环境,因此一个相同的变量会因为用户身份的不同而具有不同的值。
Vim编辑器

- 命令模式:控制光标移动,可对文本进行复制、粘贴、删除和查找等工作。
- 输入模式:正常的文本录入。
- 末行模式:保存或退出文档,以及设置编辑环境。
可以分别使用a、i、o三个键从命令模式切换到输入模式。其中,a键与i键分别是在光标后面一位和光标当前位置切换到输入模式,而o键则是在光标的下面再创建一个空行,此时可敲击a键进入到编辑器的输入模式
命令模式中常用的命令如下表:
| 命令 | 作用 |
|---|---|
| dd | 删除(剪切)光标所在整行 |
| 5dd | 删除(剪切)从光标处开始的5行 |
| yy | 复制光标所在整行 |
| 5yy | 复制从光标处开始的5行 |
| n | 显示搜索命令定位到的下一个字符串 |
| N | 显示搜索命令定位到的上一个字符串 |
| u | 撤销上一步的操作 |
| p | 将之前删除(dd)或复制(yy)过的数据粘贴到光标后面 |
末行模式中可用的命令如下表所示:
| 命令 | 作用 |
|---|---|
:w |
保存 |
:q |
退出 |
:q! |
强制退出(放弃对文档的修改内容) |
:wq! |
强制保存退出 |
:set nu |
显示行号 |
:set nonu |
不显示行号 |
| :命令 | 执行该命令 |
| :整数 | 跳转到该行 |
:s/one/two |
将当前光标所在行的第一个one替换成two |
:s/one/two/g |
将当前光标所在行的所有one替换成two |
:%s/one/two/g |
将全文中的所有one替换成two |
| ?字符串 | 在文本中从下至上搜索该字符串 |
| /字符串 | 在文本中从上至下搜索该字符串 |
Shell脚本
Shell脚本命令的工作方式有两种:交互式和批处理。
- 交互式(Interactive):用户每输入一条命令就立即执行。
- 批处理(Batch):由用户事先编写好一个完整的Shell脚本,Shell会一次性执行脚本中诸多的命令。
查看SHELL变量可以发现当前系统默认使用Bash作为命令行终端解释器:
![]()
Shell脚本文件的名称可以任意,但为了避免被误以为是普通文件,建议将.sh后缀加上,以表示是一个脚本文件。
第一行的脚本声明(#!)用来告诉系统使用哪种Shell解释器来执行该脚本;第二行的注释信息(#)是对脚本功能和某些命令的介绍信息,使得自己或他人在日后看到这个脚本内容时,可以快速知道该脚本的作用或一些警告信息。例如下面是一个简单的脚本程序示例,该脚本完成查看当前工作路径并列出当前目录下所有的文件及属性信息的功能:
#!/bin/bash
#For Example
pwd
ls -al
要执行脚本文件,第一种方法是使用bash解释器命令直接运行Shell脚本,第二种方法是通过输入完整路径的方式来执行。
bash example.sh
./example.sh
Shell脚本可以接受用户输入的参数,Shell脚本语言已经内设了用于接受参数的变量。例如$0对应的是当前Shell脚本程序的名称,$#对应的是总共有几个参数,$*对应的是所有位置的参数值,$?对应的是显示上一次命令的执行返回值,而$1、$2、$3……则分别对应着第N个位置的参数值。



Shell脚本中的条件测试语法可以判断表达式是否成立,若条件成立则返回数字0,否则便返回其他随机数值。条件测试语法如下所示:
![]()
按照测试对象来划分,条件测试语句可以分为4种:
- 文件测试语句;
- 逻辑测试语句;
- 整数值比较语句;
- 字符串比较语句。
文件测试所用的参数如下表:
| 运算符 | 作用 |
|---|---|
| -d | 测试文件是否为目录类型 |
| -e | 测试文件是否存在 |
| -f | 判断是否为一般文件 |
| -r | 测试当前用户是否有权限读取 |
| -w | 测试当前用户是否有权限写入 |
| -x | 测试当前用户是否有权限执行 |


在Shell终端中逻辑“与”的运算符号是&&,它表示当前面的命令执行成功后才会执行它后面的命令;逻辑“或”的运算符号为||,表示当前面的命令执行失败后才会执行它后面的命令;逻辑“非”的运算符号是一个叹号(!),它表示把条件测试中的判断结果取相反值。
![]()

![]()
整数比较运算符仅是对数字的操作,不能将数字与字符串、文件等内容一起操作,而且不能想当然地使用日常生活中的等号、大于号、小于号等来判断。因为等号与赋值命令符冲突,大于号和小于号分别与输出重定向命令符和输入重定向命令符冲突。因此一定要使用规范的整数比较运算符来进行操作,如下表所示:
| 运算符 | 作用 |
|---|---|
| -eq | 是否等于 |
| -ne | 是否不等于 |
| -gt | 是否大于 |
| -lt | 是否小于 |
| -le | 是否等于或小于 |
| -ge | 是否大于或等于 |


常见的字符串比较运算符如下表:
| 运算符 | 作用 |
|---|---|
| = | 比较字符串内容是否相同 |
| != | 比较字符串内容是否不同 |
| -z | 判断字符串内容是否为空 |

#!/bin/bash
DIR="/media/cdrom"
if [ ! -e $DIR ]
then
mkdir -p $DIR
fi

#!/bin/bash
ping -c 3 -i 0.2 -W 3 $1 &> /dev/null
if [ $? -eq 0 ]
then
echo "Host $1 is On-line."
else
echo "Host $1 is Off-line."
fi


#!/bin/bash
read -p "Enter your score(0-100):" GRADE
if [ $GRADE -ge 85 ] && [ $GRADE -le 100 ] ; then
echo "$GRADE is Excellent"
elif [ $GRADE -ge 70 ] && [ $GRADE -le 84 ] ; then
echo "$GRADE is Pass"
else
echo "$GRADE is Fail"
fi

#!/bin/bash
read -p "Enter The Users Password : " PASSWD
for UNAME in `cat users.txt`
do
id $UNAME &> /dev/null
if [ $? -eq 0 ]
then
echo "Already exists"
else
useradd $UNAME &> /dev/null
echo "$PASSWD" | passwd --stdin $UNAME &> /dev/null#passwd默认是要用终端作为标准输入,加上--stdin表示可以用任意文件做标准输入于是这里用管道作为标准输入
if [ $? -eq 0 ]
then
echo "$UNAME , Create success"
else
echo "$UNAME , Create failure"
fi
fi
done

#!/bin/bash
PRICE=$(expr $RANDOM % 1000) #expr命令是一个手工命令行计数器,用于在UNIX/LINUX下求表达式变量的值,一般用于整数值,也可用于字符串
TIMES=0
echo "商品实际价格为0-999之间,猜猜看是多少?"
while true
do
read -p "请输入您猜测的价格数目:" INT
let TIMES++
if [ $INT -eq $PRICE ]
then
echo "恭喜您答对了,实际价格是 $PRICE"
echo "您总共猜g $TIMES 次"
exit 0
elif [ $INT -gt $PRICE ]
then
echo "太高了!"
else
echo "太低了!"
fi
done
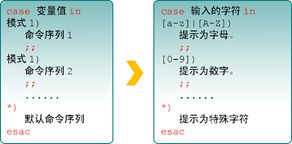
#!/bin/bash
read -p "请输入一个字符,并按Enter键确认:" KEY
case "$KEY" in
[a-z]|[A-Z])
echo "您输入的是 字母。"
;;
[0-9])
echo "您输入的是 数字。"
;;
*)
echo "您输入的是 空格、功能键或其他控制字符。"
esac