【集训队作业2018】三角形【线段树合并+思路详解】
题目链接
【题面】
Snuke 有一棵 nn 个点的有根树,每个点有权值 wiwi,初始每个结点上都没有石子。
Snuke 准备了一些石子,并把它们拿在手中。她可以进行以下两种操作任意多次:
- 从手中取 wiwi 个石子放在结点 ii 上,进行该操作要求结点 ii 的所有孩子 jj 上都有 wjwj 个石子。
- 将结点 ii 上的所有石子收回手中。
Takahashi 想知道对于每个 ii,为了在结点 ii 上放 wiwi 个石子,Snuke 至少需要准备多少石子。
输入格式
从标准输入读入数据。
第一行一个数字 TT 表示这个子任务的编号。
第二行一个正整数 nn 。(n≤2×105)(n≤2×105)
第三行 n−1n−1 个正整数,第 i−1i−1 个数 pipi 表示 ii 的父亲。(pi 第四行 nn 个正整数,第 ii 个数为 wiwi 。 输出到标准输出。 输出一行 nn 个正整数,第 ii 个数为结点 ii 的答案。 我写的比较烂吧,理解的不是很深了,基本是基于大佬代码的理解来写的。 这篇博客写的可以,没读懂一号 这篇文章写的也很好,但是更加大佬,我又不大懂,只能基于其来做理解 这道题,并没用去使用很多博主的用堆去维护状态的想法,直接上线段树上的合并来解这道题(说实话,自己单独是没有那个能力来完成这道题的,然后跟着博客以及已经过的代码去理解,再写出来的自己的code) 首先讲一下吧,关于这道题的为什么会去使用线段树合并的想法 然后,我们可以看到,每个点,都要先得到所有的子节点上都放上石头之后,再加上该节点的石子,就有可能是该节点的所需石子数,但是可能会偏小,因为你不能这么确定出每个子节点的最大需要是否会满足这个条件,所以,我们必须从子节点开始,从叶子节点往上去寻找最适合的答案,那么又该怎么解? 从叶子节点向上去,我们去求叶子节点所需要的石子数就是其自己的石子数,然后往上一层,就是所有旗下的叶子节点加上该点的权重(石子数),但是岂不是可以看成,叶子节点之上的每一层都存在一个最大的前缀和最小的后缀,是这样来的:对于这个节点,我们要考虑它的操作,就是要考虑到选取它的时候,我们要对于它的所有子节点都进行一个判断,因为对于目前节点,譬如这样(自己画的图,有点点丑): (举例来说)我们可以知道,要是要让权值是6的节点拿满是需要5+4+6的数目的石子数,但是到了6周之后,可以舍去这些石子了,所以此时的最大需求石子数是15,但是现在放下去的石子数是6,所以可以保存住这些数据(15, 6);接下来再看,权值为10的节点,我们要拿它,就是需要(15, 10)这样子的节点;再看9权值的这个节点,我们要单纯的只拿它,岂不是要(10, 9)。再往上,就是权值为3的最顶的那个节点,它所需要的情况又是怎样的呢?6+10+9+max(5+4, 3+2, 1, 0, 3) = 28(前面的几个(9, 5, 1, 0)去取大,然后跟3去取小的),其中这个最后的0特有深意,就是为了一定要变成升权的,(但是现在体现的不明显,我们往下推,就知道了),但是这样做的确是不好推,因为其中的5+4、3+2、1都是没有继承下来的,所以,该怎么办?不妨这样,我们先不要去加上该节点的权值,等到需要得到ans的时候再加上自己的权值,就是这么说原来的6、10、9号节点会变成(9, 6)、(5, 10)、(1, 9)这样子的类型,那么不就是可以知道前面的最大需求了吗。 其实,还需要一点的优化,但是基本已经成型了,我们可以知道这点,一共最多2e5个点,以及最大1e9的权值,所以最大最大的需求也不过2e14。——此为前提O(log2e14)是可行的。 那么,为了让每个节点都能从其子节点的状态开始往上推,我们应该处理一些什么,我们把每个节点看成一个处理前缀和后缀的过程,那么维护的是什么呢?我们可以去考虑维护一个前缀最大值和一个后缀最小值,这是为什么呢?为什么这么维护呢?前缀最大值维护的是答案,就是每个节点的最少需要的除去自己上面的所需的石子数,而后缀最小值呢,维护的又是什么呢? 现在这么考虑,维护一个前缀最大值(maxx)和一个后缀最小值(minn),其中为了使得到达每个点都能用最大前缀来表示它的答案,我们得做一些想法,譬如说,我们把两个子节点合并起来,来看到权值为6的这号节点就有两个子节点5号和4号,我们就会有对应的需要继承,譬如说,权值为5号节点的向上推的(maxx, minn)的值为(0, -5),之所以为什么是这个值呢,最大的前缀去除自己的权值为0,再看看其他的点,我们从小往上去访问,得到的是这样的: 我们从下往上,以权值为目的来解: (5)、(0, -5) (4)、(0, -4) (3)、(,0 -3) (2)、(0, -2) (1)、(0, -1) (6)、(9, -15) (10)、(5, -15) (9)、(1, -10) (3)、(25, -28) 这些都是向上递推时候,放进去的状态,而一开始我们应该怎么去假设状态呢? 不妨令其为(0, -w[u]),这样子就可以在最后的时候在加入+w[u]了。 那么答案就是:这个点时候的maxx + w[u]。 另外大佬一号: 考虑每个操作,如果把操作按先后顺序放到序列上的话,操作一就是把wiwi的石子放到某个节点,那么就是在序列末端加入wiwi,然后根据贪心肯定要把它所有儿子的石子拿走,也就是要减去∑wson∑wson 那么每个点的答案就是序列的最大前缀 因为父亲节点的操作一要在儿子之后进行,很麻烦,那么可以每次在自己这里把wiwi减掉,到父亲的时候再加回去 记(x,y)(x,y)为一个二元组,xx表示当前位置的最大前缀和,yy表示最小后缀和,然后定义一个运算(ax,by)=(x+max(0,a+y),b+min(0,a+y)(ax,by)=(x+max(0,a+y),b+min(0,a+y),大概能看出是个什么东西,注意这个运算不满足交换律 然后考虑一下这些二元组在序列中的顺序,如果x+y<0x+y<0,那么肯定得放前面,因为可以让之后的前缀和减小。 那么当x+y<0x+y<0时,按xx排序,这样能使前缀和不断减小。如果x+y>0x+y>0,按yy排序就好了 维护二元组的话,用线段树合并,如果当前二元组的x+y<0x+y<0且有比它最大前缀大的二元组,那么就已经是最优的了否则将在它前面的二元组与它合并,合并完后加进线段树里就好了。注意合并完之后节点没了要记得清空。 大佬二号: 先理解操作的意义。我们把所有的操作以先后顺序放在一个序列上,然后开始想两个操作对于这个序列的修改。 操作一是把wiwi的石子放在某个节点,在序列上的表现则是在当前序列的末端加入wiwi。 而当我们做完操作一,肯定是贪心地将这个节点的儿子们的石子全拿回来。在序列上的表现就是减去∑w[son]∑w[son]。 而我们要求的就是序列上的最大前缀。 但这个东西并不好搞。为什么呢?因为对于一个操作一而言,必须在它的儿子们操作一之后执行。这个限制看起来不好消除,但其实也很办。 我们知道两个操作是连续的。所以可以把+wi−∑w[son]+wi−∑w[son]改成+∑w[son]−wi+∑w[son]−wi。 定义一个二元组(x,y)(x,y),xx表示为当前位置在序列的最大前缀,&y&表示为当前位置在序列的最小后缀。 考虑如何定义这个二元组的运算符。假设有二元组A(x,y)A(x,y)。把两个二元组合并为C(xX,yY)C(xX,yY),其中xX=x+max(0,X+y)xX=x+max(0,X+y),yY=y+min(0,X+y)yY=y+min(0,X+y)。这个东西可以感性理解一下,感觉也不用解释。 然后我们考虑一下这些二元组应当以什么样的顺序放在序列里。很明显的一个结论,若A(x,y)A(x,y)中,x+y<0x+y<0,则应当放在前面。然后就可以分两类考虑了。 对于x+y<0x+y<0的情况。显然的应该以xx从小到大排序。这样最大前缀一定越小。同理,另一种情况就是按yy排序就好了。 那接下来只用考虑如何维护这些二元组就行了。网上有篇题解的做法是先将序列构造出来,再用线段树合并。其实没必要这样,直接线段树合并就好了。 考虑每次如何合并二元组。如果当前二元组x+y<0x+y<0而且有比它的最大前缀还大最大前缀,那么当前一定是最优的,所以放在前面就好了。否则每次将在它前面的二元组与它合并就好了。合并完后再添加进线段树即可。 这里稍微注意一下合并,合并完后,那个被合并的二元组就没了(因为已经是最优的了),那么就要在线段树上把当前的节点删掉,不然下次合并二元组的时候就会再次调用这个已经被用过的二元组了。 每次的答案就是最大前缀。 他们都好强啊……QAQ……%%% 输出格式
(本来压根儿想不到这块的,就是因为其他博主都这么写,所以想到了),我们可以看到,一共有两种操作,一个是放Wi个石子到该点,另一个是去取Wi个石子下来放回手上,然后我们所要知道的就是每个节点所需要的最少的石头数,使得该节点能被放上石头。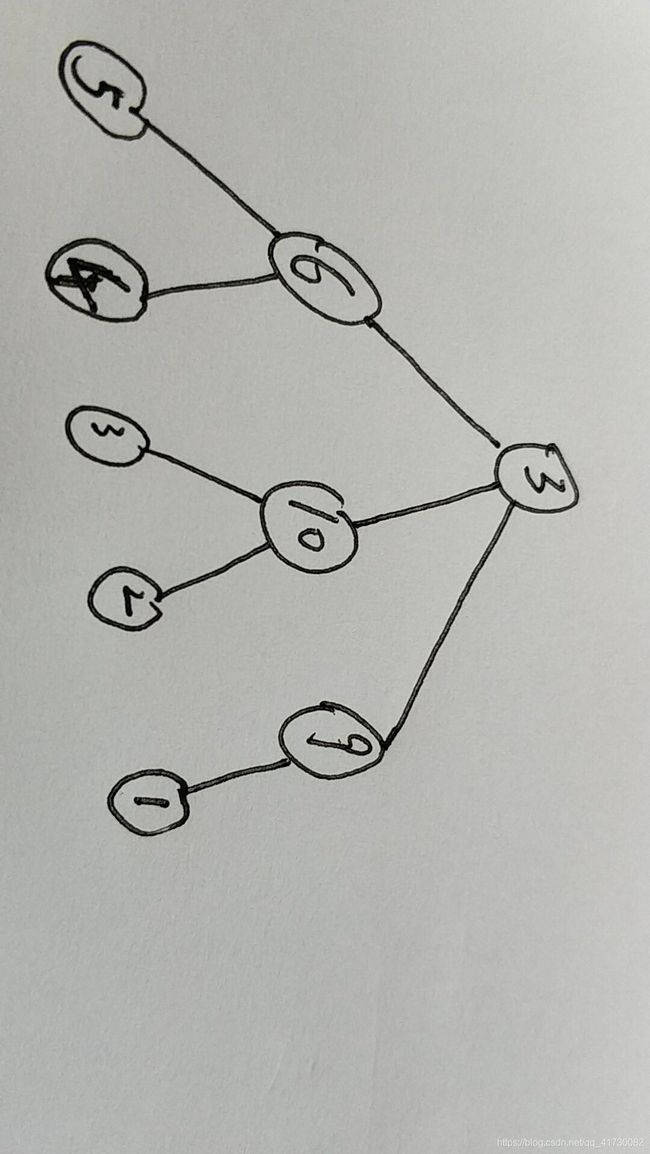
(好像这幅图还横过来了……将就看啦)
#include