jetson-nano实战项目之人脸识别+stm32小车
搬砖是真的难受。。。。可是
我菜我快乐啊哈哈哈,博主前两天和老师说了说,能不能用我自己的nano做一个人脸识别(确认是主人)+手势识别(给小车提供命令),然后stm32+2640(避障+路线规划)+声源(唤醒小车)这个东西能不能做为自己的毕业设计,老师说没问题,于是乎博主就开始搞怪啊哈哈哈,还是想唠叨几句,博主在9月份有的这个想法,然后各种碰壁各种头大,毕竟没有人给自己指路,自己摸索来还是很难受的,但是不想让后来人踩坑,博主先说一下想做这些东西至少要准备的基础吧!
**
1.
**stm32+摄像头,正点原子的视频教程很不错,网上也有很多资料,路径规划可以自己摸索一下摄像头算法~,先从最简单的巡线来
2.
nano的话,因为是ubuntu系统,所以大家最好熟悉一下linux教程,博主全嫖b站来的,视频地址 推荐1.5倍速哈哈哈啊哈哈哈啊哈
简单的熟悉一下各种指令,别一下就懵逼了,当然博主不是要做运维,所以没学那么深,一些老师讲的简单的都用本子记下来了,然后都跟着试了试,这里也是强烈推荐大家一定要自己打!!!到后来的时候也有很多会忘掉的
3.
博主只有c和汇编的基础,所以感觉学c++有点来不及,于是乎学的python,而且现在深度学习好像都用的python?后面的吴老师的课程也都是py哦,很好用,也很容易上手,这里推荐小甲鱼的视频视频链接
这里也推荐1.25或1.5倍速emm ,最最最重要的是一定一定要自己打!!!要自己打!!!!要自己打!!!博主也是写在了本子上,但是有很多代码能看懂,但是自己写的话还是需要一段时间来练习。
4.
人脸识别,一提到这个肯定就和听起来超级高大上的AI有关系啦~(传说中的机器学习深度学习哈哈哈),这个如果学过PID算法的,数学好一点的或者学过统计的,应该还是很好理解的,不过有一些多维的东西有时候还真的很难想,
这里推荐吴恩达老师的教程!深入浅出,而且作业题也很锻炼人!这里就不给链接了,
网易云课堂,直接搜索,有一个机器学习的视频,还有一个微专业深度学习的视频,我是直接看的深度学习,讲的真的超级棒,因为是斯坦福公开课,课后作业正版可能要,这里给一下中文的课后作业链接吧,这个博主真的超级好,整理了一下,不过有些课后题好像是有点问题哦,要自己去发现
课后作业
5.
最最最重要的就来了,在学习的过程中,大家肯定就开始听说tensorflow,keras,pytorch等深度学习框架了,那么!什么叫深度学习框架呢!其实我理解起来就是c语言中的子函数,你有了这些,去调用就好了~,
并且我相信买了nano的人也一定知道nano自带tensorflow,还有cuda的,那么这些框架到底怎么用????好的,我又找了视频哈哈哈哈,博主比较笨,还是喜欢视频嘻嘻嘻,日月光华tensorflow实战
b站上它只放了一点,网易的完整版要199还是399来着,不过呢我希望大家看完这几节之后要能自己写一点点,然后!就一定一定要去看官方文档来学,毕竟官方的东西,而且keras的官方例子给的也很多,可以照葫芦画瓢,用完这个之后,你就会爱上这些框架的~
6.
好,大家如果真的前面5个有了基础,那么就可以来这一步了,首先,如果nano用的是板载摄像头,那么在cv调用的时候,一定要通过Gstreamer来传过来
具体参考这位老哥如何配置Gstreamer
好了,那么调用也能调用了,那么接下来该干什么呢,博主也懒得重复别人的话了,直接放链接 深度学习实战教程 注意了注意了!!!因为这个老哥是在自己的笔记本上跑的,所以和nano有不一样的地方,这应该才是本文的重点了,首先!!!,如果自己用的是板载摄像头,所有代码里面cv2.VideoCapture这个函数后面一定一定要用的是(“nvarguscamerasrc ! video/x-raw(memory:NVMM), width=360, height=360, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=360, height=360, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink”)一定是这句话哦~,其中width和height可以自己调,这个就是窗口大小问题了,
跟着他的教程,博主自己收集了1000张自拍和舍友(坑蒙拐骗)的照片,然后接着去训练,叮叮叮!敲警钟,训练的时候,一定要关掉图形界面
sudo systemctl set-default multi-user.target 然后reboot,(sudo systemctl set-default graphical.target 这是开启图形界面),要不然内存占用太多不行的,跟着那位大哥的教程来到了第五步的时候,要注意了,大家肯定很想看结果!但是很可惜nano在图形界面下还是跑不了呜呜呜(我要它何用!将来有钱一定买xvaier),好了那么跑不通的情况下,那个老哥的代码就不行了,因为他那里面有开窗还有标记,所以,附上我的代码,不过大家如果学的比较好相信你们也会直接把冻结的模型拿到自己笔记本上来用,我笔记本上没装keras啥的,所以就不示范了。
import serial as ser
import struct,time
import cv2
#import sys
from face_train_keras import Model
se = ser.Serial('/dev/ttyTHS1',115200,timeout=0.5)
model = Model()
model.load_model(file_path = './model/me.face.model.h5')
color = (0, 255, 0)
a ='y'
b ='n'
classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
cap = cv2.VideoCapture("nvarguscamerasrc ! video/x-raw(memory:NVMM), width=360, height=360, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=360, height=360, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink")
while cap.isOpened():
ok, frame = cap.read() # type(frame) 如果大家也是用串口来看的话,就把里面我注释掉的给释放就好了,如果没用串口,那么在屏幕上也能看到me或者notme的字样,
有人问怎么通信???!!!问到点子上了啊哈哈哈看博主前面的文章
jetsonnano与stm32通信
虽然训练的时候和测试的时候正确率都很高,但是,毕竟博主只是在实验室照的,所以背景单一,只有光线可能不同,还是很影响跑起来的效果的!
这里是我跑的照片
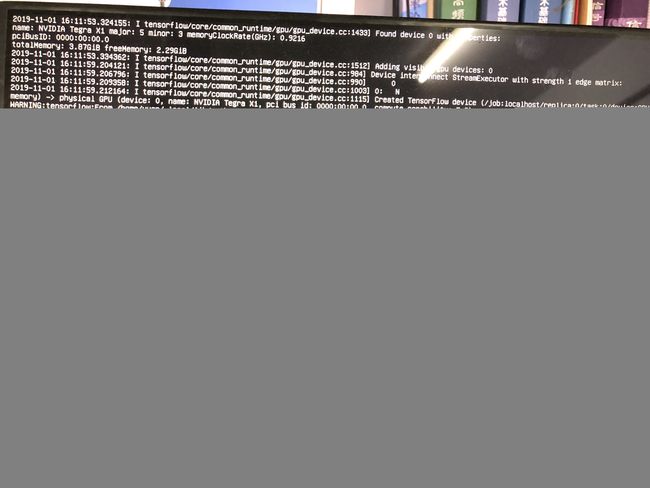
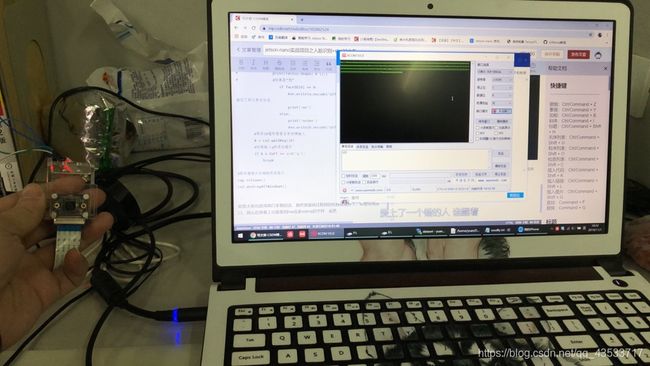
第二张图片可能不是很清楚,我打开的上位机,显示 y或者n的字样,y就是识别到了我,n就不是我,不过这也算可以吧!大家如果想要特别好的效果,就要选取差异大一些的背景、光线、表情等等来训练,等再学一学keras和原理之后,再去改善代码,而且他那个代码里面,你截取完自己的脸部照片之后,会发现都很小,可能五官都很少,想大一些的话可以去改那里面圈出来的范围,博主就不改了~
好了,自己的第一个实战项目算是完成了一半,等明天再来填上stm32的坑,