决策树与信息增益
信息增益
================
一,特征选择中的信息增益:
================
信息增益是什么,我们先从它的用处来了解它:
信息增益是特征选择中的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
那么如何衡量一个特征为分类系统带来的信息多少呢:
对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,其实就是熵。
================
二,计算信息增益:利用熵
================
1. 信息论里的熵
因此先回忆一下信息论中有关信息量(就是“熵”)的定义。说有这么一个变量X,它可能的取值有n多种,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:

意思就是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大(因此我一直觉得我们的政策法规信息量非常大,因为它变化很多,基本朝令夕改,笑)。
2. 分类系统里的熵
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:
 错了,这块前面要加个负号
错了,这块前面要加个负号
有同学说不好理解呀,这样想就好了,文本分类系统的作用就是输出一个表示文本属于哪个类别的值,而这个值可能是C1,C2,……,Cn,因此这个值所携带的信息量就是上式中的这么多。
3. 信息增益和熵的关系
信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。系统含有特征t的时候信息量很好计算,就是刚才的式子,它表示的是包含所有特征时系统的信息量。
问题是当系统不包含t时,信息量如何计算?我们换个角度想问题,把系统要做的事情想象成这样:说教室里有很多座位,学生们每次上课进来的时 候可以随便坐,因而变化是很大的(无数种可能的座次情况);但是现在有一个座位,看黑板很清楚,听老师讲也很清楚,于是校长的小舅子的姐姐的女儿托关系 (真辗转啊),把这个座位定下来了,每次只能给她坐,别人不行,此时情况怎样?对于座次的可能情况来说,我们很容易看出以下两种情况是等价的:(1)教室 里没有这个座位;(2)教室里虽然有这个座位,但其他人不能坐(因为反正它也不能参与到变化中来,它是不变的)。
对应到我们的系统中,就是下面的等价:(1)系统不包含特征t;(2)系统虽然包含特征t,但是t已经固定了,不能变化。
我们计算分类系统不包含特征t的时候,就使用情况(2)来代替,就是计算当一个特征t不能变化时,系统的信息量是多少。这个信息量其实也有专门的名称,就叫做“条件熵”,条件嘛,自然就是指“t已经固定“这个条件。
但是问题接踵而至,例如一个特征X,它可能的取值有n多种(x1,x2,……,xn), 当计算条件熵而需要把它固定的时候,要把它固定在哪一个值上呢?答案是每一种可能都要固定一下,计算n个值,然后取均值才是条件熵。而取均值也不是简单的 加一加然后除以n,而是要用每个值出现的概率来算平均(简单理解,就是一个值出现的可能性比较大,固定在它上面时算出来的信息量占的比重就要多一些)。
因此有这样两个条件熵的表达式:
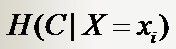
这是指特征X被固定为值xi时的条件熵,
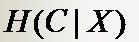
这是指特征X被固定时的条件熵,注意与上式在意义上的区别。从刚才计算均值的讨论可以看出来,第二个式子与第一个式子的关系就是:

具体到我们文本分类系统中的特征t,t有几个可能的值呢?注意t是指一个固定的特征,比如他就是指关键词“经济”或者“体育”,当我们说特征“经济”可能的取值时,实际上只有两个,“经济”要么出现,要么不出现。一般的,t的取值只有t(代表t出现)和 id="iframe_0.21284812778931866" src="https://www.cnblogs.com/show-blocking-image.aspx?url=http%3A%2F%2Fimage4.360doc.com%2FDownloadImg%2F2009%2F10%2F10%2F79028_7055867_6.gif&maxWidth=1285&origin=undefined&iframeId=iframe_0.21284812778931866" frameborder="0" scrolling="no" style="border: currentColor; border-image: none; width: 1285px;">(代表t不出现),注意系统包含t但t 不出现与系统根本不包含t可是两回事。
因此固定t时系统的条件熵就有了,为了区别t出现时的符号与特征t本身的符号,我们用T代表特征,而用t代表T出现,那么:

与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率,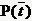 就是T不出现的概率。这个式子可以进一步展开,其中的
就是T不出现的概率。这个式子可以进一步展开,其中的
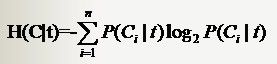
另一半就可以展开为:
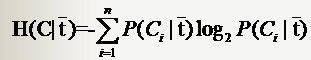
因此特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:
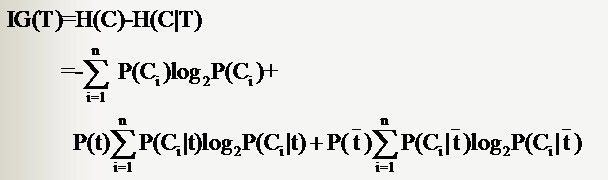
公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。
从以上讨论中可以看出,信息增益也是考虑了特征出现和不出现两种情况,与开方检验一样,是比较全面的,因而效果不错。但信息增益最大的问题 还在于它只能考察特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而 无法做“本地”的特征选择(每个类别有自己的特征集合,因为有的词,对这个类别很有区分度,对另一个类别则无足轻重)。
================
三,一个例子:
================
任务:
根据天气预测否去打网球
数据:

这个数据集来自Mitchell的机器学习,叫做是否去打网球play-tennis,以下数据仍然是从带逗号分割的文本文件,复制到纪事本,把后缀直接改为.csv就可以拿Excel打开: *play-tennis data,其中6个变量依次为:编号、天气{Sunny、Overcast、Rain}、温度{热、冷、适中}、湿度{高、正常}、风力{强、弱}以及最后是否去玩的决策{是、否}。一个建议是把这些数据导入Excel后,另复制一份去掉变量的数据到另外一个工作簿,即只保留14个观测值。这样可以方便地使用Excel的排序功能,随时查看每个变量的取值到底有多少。*/ NO. , Outlook , Temperature , Humidity , Wind , Play 1 , Sunny , Hot , High , Weak , No 2 , Sunny , Hot , High , Strong , No 3 , Overcast , Hot , High , Weak , Yes 4 , Rain , Mild , High , Weak , Yes 5 , Rain , Cool , Normal , Weak , Yes 6 , Rain , Cool , Normal , Strong , No 7 , Overcast , Cool , Normal , Strong , Yes 8 , Sunny , Mild , High , Weak , No 9 , Sunny , Cool , Normal , Weak , Yes 10 , Rain , Mild , Normal , Weak , Yes 11 , Sunny , Mild , Normal , Strong , Yes 12 , Overcast , Mild , High , Strong , Yes 13 , Overcast , Hot , Normal , Weak , Yes 14 , Rain , Mild , High , Strong , No
用决策树来预测:
决策树的形式类似于“如果天气怎么样,去玩;否则,怎么着怎么着”的树形分叉。那么问题是用哪个属性(即变量,如天气、温度、湿度和风力)最适合充当这颗树的根节点,在它上面没有其他节点,其他的属性都是它的后续节点。
那么借用上面所述的能够衡量一个属性区分以上数据样本的能力的“信息增益”(Information Gain)理论。
如果一个属性的信息增益量越大,这个属性作为一棵树的根节点就能使这棵树更简洁,比如说一棵树可以这么读成,如果风力弱,就去玩;风力强,再按天气、温度等分情况讨论,此时用风力作为这棵树的根节点就很有价值。如果说,风力弱,再又天气晴朗,就去玩;如果风力强,再又怎么怎么分情况讨论,这棵树相比就不够简洁了。
用熵来计算信息增益:
1 计算分类系统熵
类别是 是否出去玩。取值为yes的记录有9个,取值为no的有5个,即说这个样本里有9个正例,5 个负例,记为S(9+,5-),S是样本的意思(Sample)。那么P(c1) = 9/14, P(c2) = 5/14
这里熵记为Entropy(S),计算公式为:
Entropy(S)= -(9/14)*log2(9/14)-(5/14)*log2(5/14)用Matlab做数学运算
2 分别以Wind、Humidity、Outlook和Temperature作为根节点,计算其信息增益
我们来计算Wind的信息增益
当Wind固定为Weak时:记录有8条,其中正例6个,负例2个;
同样,取值为Strong的记录6个,正例负例个3个。我们可以计算相应的熵为:
Entropy(Weak)=-(6/8)*log(6/8)-(2/8)*log(2/8)=0.811
Entropy(Strong)=-(3/6)*log(3/6)-(3/6)*log(3/6)=1.0
现在就可以计算出相应的信息增益了:
所以,对于一个Wind属性固定的分类系统的信息量为 (8/14)*Entropy(Weak)+(6/14)*Entropy(Strong)
Gain(Wind)=Entropy(S)-(8/14)*Entropy(Weak)-(6/14)*Entropy(Strong)=0.940-(8/14)*0.811-(6/14)*1.0=0.048
这个公式的奥秘在于,8/14是属性Wind取值为Weak的个数占总记录的比例,同样6/14是其取值为Strong的记录个数与总记录数之比。
同理,如果以Humidity作为根节点:
Entropy(High)=0.985 ; Entropy(Normal)=0.592
Gain(Humidity)=0.940-(7/14)*Entropy(High)-(7/14)*Entropy(Normal)=0.151
以Outlook作为根节点:
Entropy(Sunny)=0.971 ; Entropy(Overcast)=0.0 ; Entropy(Rain)=0.971
Gain(Outlook)=0.940-(5/14)*Entropy(Sunny)-(4/14)*Entropy(Overcast)-(5/14)*Entropy(Rain)=0.247
以Temperature作为根节点:
Entropy(Cool)=0.811 ; Entropy(Hot)=1.0 ; Entropy(Mild)=0.918
Gain(Temperature)=0.940-(4/14)*Entropy(Cool)-(4/14)*Entropy(Hot)-(6/14)*Entropy(Mild)=0.029
这样我们就得到了以上四个属性相应的信息增益值:
Gain(Wind)=0.048 ;Gain(Humidity)=0.151 ; Gain(Outlook)=0.247 ;Gain(Temperature)=0.029
最后按照信息增益最大的原则选Outlook为根节点。子节点重复上面的步骤。这颗树可以是这样的,它读起来就跟你认为的那样: id="iframe_0.5465274915280287" src="https://www.cnblogs.com/show-blocking-image.aspx?url=http%3A%2F%2Ftkfiles.storage.msn.com%2Fx1p6tb9aEP1qM2QXdOxhhg17wvix6_wKGagLMmaie3gnmRHsRSFU294oSMGUtxQL-Bag2EkBOvhK-SMxR3nPf3GBiCjix4uuXll-DEFazP7LU0&maxWidth=1285&origin=undefined&iframeId=iframe_0.5465274915280287" frameborder="0" scrolling="no" style="border: currentColor; border-image: none; width: 1285px;">