pytorch 多GPU训练总结(DataParallel的使用)
这里记录用pytorch 多GPU训练 踩过的许多坑 仅针对单服务器多gpu 数据并行 而不是 多机器分布式训练
一、官方思路包装模型
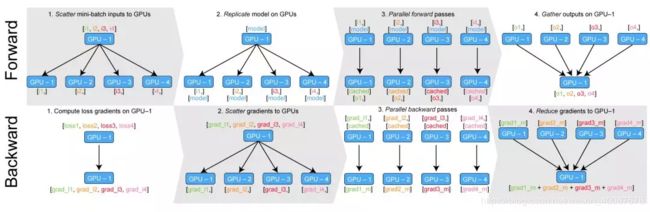
这是pytorch 官方的原理图 按照这个官方的原理图 修改应该参照
https://blog.csdn.net/qq_19598705/article/details/80396325
上文也用dataParallel 包装了optimizer, 对照官方原理图中第二行第二个,将梯度分发出去,将每个模型上的梯度更新(第二行第三个),然后再将更新完梯度的模型参数合并到主gpu(第二行最后一个步骤)
其实完全没必要,因为每次前向传播的时候都会分发模型,用不着反向传播时将梯度loss分发到各个GPU,单独计算梯度,再合并模型。可以就在主GPU 上根据总loss 更新模型的梯度,不用再同步其他GPU上的模型,因为前向传播的时候会分发模型。
所以 上述链接里 不用 dataParallel 包装 optimizer。
DataParallel并行计算只存在在前向传播
总结步骤:
import os
import torch
args.gpu_id="2,7" ; #指定gpu id
args.cuda = not args.no_cuda and torch.cuda.is_available() #作为是否使用cpu的判定
#配置环境 也可以在运行时临时指定 CUDA_VISIBLE_DEVICES='2,7' Python train.py
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_id #这里的赋值必须是字符串,list会报错
device_ids=range(torch.cuda.device_count()) #torch.cuda.device_count()=2
#device_ids=[0,1] 这里的0 就是上述指定 2,是主gpu, 1就是7,模型和数据由主gpu分发
if arg.cuda:
model=model.cuda() #这里将模型复制到gpu ,默认是cuda('0'),即转到第一个GPU 2
if len(device_id)>1:
model=torch.nn.DaraParallel(model);#前提是model已经.cuda() 了
#前向传播时数据也要cuda(),即复制到主gpu里
for batch_idx, (data, label) in pbar:
if args.cuda:
data,label= data.cuda(),label.cuda();
data_v = Variable(data)
target_var = Variable(label)
prediction= model(data_v,target_var,args)
#这里的prediction 预测结果是由两个gpu合并过的,并行计算只存在在前向传播里
#前向传播每个gpu计算量为 batch_size/len(device_ids),等前向传播完了将结果和到主gpu里
#prediction length=batch_size
criterion = nn.CrossEntropyLoss()
loss = criterion(prediction,target_var) #计算loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
之后调用model里的函数 继承的函数可以直接调用 例如 model.state_dict() ,model.load_state_dict(torch.load(model_path)......不受影响。但是自己写的函数 要加上.module才行 model.module.forward_getfeature(x)。自己写的函数 不可以并行运算 ,只能在主gpu中运算。DataParallel并行计算仅存在在前向传播。但可以换个思路 写进forward 里或者被forward调用,多返回几个参数不就得了 return feature,predict
二、解决多GPU 负载不均衡的问题
我的经历是主gpu 显存爆了,而其他gpu显存只用了1/5,负载不均衡到不能忍,无法再加大batch_size
参考:https://discuss.pytorch.org/t/dataparallel-imbalanced-memory-usage/22551/20(看了半天的英文才看懂。。。)
负载不均衡的原因是 loss = criterion(prediction,target_var) 计算loss 占用了大量的内存,如果我们让每个gpu单独计算loss,再返回即可解决这个问题 即 prediction,loss=model(data,target) (#如果后边不用prediction,连prediction也不用返回,只返回loss)。每个gpu返回一个loss,合到主gpu就是一个list,要loss.mean() 或loss.sum(),推荐mean.
这样以来,所有可以在其他gpu中单独计算的都可以写进forward 里,返回结果即可。但要注意 tensor类型的数组 合并len会增加,例如prediction lenth=batchsize,但是loss这种具体的数字,合并就是list了[loss1.loss2]
效果:主GPU 会稍微高一点。多个几百M, 但是基本实现了负载均衡
例子:
#model 里的forward 的函数
def forward(self,x,target_var,args):
feature512=self.forward_GetFeature(x)
if target_var is None:
return feature512;
classifyResult = self.classifier(feature512)
# 如果用DataParallel,forward返回feature 是返回多个GPU合并的结果
# 每个GPU 返回 batchsize/n 个样本,n为GPU数
#计算loss
center_loss = self.get_center_loss(feature512, target_var,args)
criterion = nn.CrossEntropyLoss()
cross_entropy_loss = criterion(classifyResult, target_var)
#CrossEntropyLoss 已经求了softmax 分类结果直接输进去即可
loss = args.center_loss_weight * center_loss + cross_entropy_loss
prec = accuracy(classifyResult.data, target_var, topk=(1,))
# 如果是返回的标量的话,那返回过去就是list,是n个GPU的结果
# 要loss.mean() 之后 在loss.backward()
return prec[0],loss