hadoop:认识hadoop、安装hadoop、伪分布hdfs
hadoop
- 1. hadoop简介
- 2.hadoop安装
- 3. 单节点hadoop配置,做一个伪分布式hdfs
- 4. 完全分布式的hdfs
- 4.1 节点的热添加(不关闭dfs基础上添加节点)
- 4.2 mapreduce(作用运行程序)
1. hadoop简介
hadoop的核心是:
HDFS: Hadoop Distributed File System 分布式文件系统
YARN: Yet Another Resource Negotiator 资源管理调度系统
Mapreduce:分布式运算框架

hadoop框架包含四个模块:

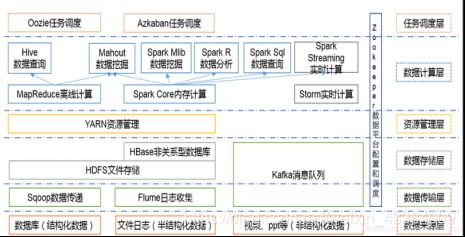
大数据生态体系:
2.hadoop安装
官方文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
清华下载源:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
jdk安装包:jdk-8u251-linux-x64.tar.gz
下载地址:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html#license-lightbox
jdk-8u251-linux-x64.tar.gz
准备一台虚拟机:server4
创建一个普通用户:useradd zjy
tar zxf hadoop-3.2.1.tar.gz
tar zxf jdk-8u251-linux-x64.tar.gz
ln -s hadoop-3.2.1 hadoop
ln -s jdk1.8.0_251 java
[zjy@server4 ~]$ ls
hadoop jdk1.8.0_251
hadoop-3.2.1 hadoop-3.2.1.tar.gz
jdk-8u251-linux-x64.tar.gz java
java包和handoop的位置
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop/etc/hadoop
[zjy@server4 hadoop]$ vim hadoop-env.sh
54 export JAVA_HOME=/home/zjy/java
58 export HADOOP_HOME=/home/zjy/hadoop
运行hadoop的二进制文件
[zjy@server4 bin]$ pwd
/home/zjy/hadoop/bin
[zjy@server4 bin]$ ./hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
buildpaths attempt to add class files from
build tree
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
使用官方的例子做测试:
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop
[zjy@server4 hadoop]$ mkdir input
[zjy@server4 hadoop]$ cp etc/hadoop/*.xml input
[zjy@server4 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[zjy@server4 hadoop]$ cat output/*
1 dfsadmin
[zjy@server4 hadoop]$ du -sh output
12K output
3. 单节点hadoop配置,做一个伪分布式hdfs
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop/etc/hadoop
[zjy@server4 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.60.4:9000</value> # 让172.25.60.4作为分布式的master
</property>
</configuration>
[zjy@server4 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> # 单节点
</property>
</configuratiot>
hadoop是通过ssh的方式连接,所以做免密
[zjy@server4 hadoop]$ ssh-keygen
[zjy@server4 hadoop]$ ssh-copy-id 172.25.60.4
[zjy@server4 hadoop]$ ssh-copy-id localhost
[zjy@server4 hadoop]$ ssh localhost
ctrl+d
对分布式系统做格式化
[zjy@server4 hadoop]$ bin/hdfs namenode -format
2020-06-04 11:18:58,648 INFO namenode.FSImageFormatProtobuf: Saving image file /tmp/hadoop-zjy/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2020-06-04 11:18:58,745 INFO namenode.FSImageFormatProtobuf: Image file /tmp/hadoop-zjy/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds .
2020-06-04 11:18:58,946 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-06-04 11:18:58,950 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-06-04 11:18:58,950 INFO namenode.NameNode: SHUTDOWN_MSG:
2020-06-04 10:30:10,973 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server4/172.25.60.4
************************************************************/
启动dfs(在分布式系统中主节点是namenodes,从节点是datanodes)
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop
[zjy@server4 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server4]
server4: Warning: Permanently added 'server4' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [server4]
将java的jps二进制执行文件添加到环境变量中
[zjy@server4 bin]$ pwd
/home/zjy/java/bin
[zjy@server4 ~]$ vim .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:/home/zjy/java/bin
[zjy@server4 ~]$ source .bash_profile
将hadoop的hadoop二进制执行文件添加到环境变量中
[zjy@server4 bin]$ pwd
/home/zjy/hadoop/bin
[zjy@server4 ~]$ vim .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:/home/zjy/java/bin:/home/zjy/hadoop/bin
[zjy@server4 ~]$ source .bash_profile
开启namenode和datenode
[zjy@server4 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server4]
Starting datanodes
Starting secondary namenodes [server4]
[zjy@server4 hadoop]$ jps
16983 SecondaryNameNode
16648 NameNode
16765 DataNode
17103 Jps
开启一个9876的端口,可以访问

[zjy@server4 hadoop]$ hdfs dfsadmin -report
Configured Capacity: 18238930944 (16.99 GB)
Present Capacity: 15164399616 (14.12 GB)
DFS Remaining: 15164395520 (14.12 GB)
DFS Used: 4096 (4 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
创建目录
[zjy@server4 hadoop]$ hdfs dfs -mkdir /user
[zjy@server4 hadoop]$ hdfs dfs -mkdir /user/zjy # 创建用户与你当前的系统用户保持一致
[zjy@server4 hadoop]$ id
uid=1000(zjy) gid=1000(zjy) groups=1000(zjy)
[zjy@server4 hadoop]$ hdfs dfs -ls # 默认查看当前系统用户名相同的目录,即/user/zjy目录

上传文件
[zjy@server4 hadoop]$ hdfs dfs -put input
2020-06-04 11:43:11,099 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:11,929 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:12,436 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:12,564 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:12,664 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:12,764 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:13,282 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:14,273 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 11:43:14,779 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false

[zjy@server4 hadoop]$ hdfs dfs # 命令操作
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
调用hadoop的api接口访问hdfs,所以从分布式文件系统中去input操作并且将output存到分布式文件系统
[zjy@server4 hadoop]$ rm -fr input/
[zjy@server4 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'

从dfs(分布式文件系统)中将output放到本地
[zjy@server4 hadoop]$ hdfs dfs -get output
2020-06-04 12:00:24,175 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[zjy@server4 hadoop]$ ls
bin include libexec logs output sbin
etc lib LICENSE.txt NOTICE.txt README.txt share
从dfs(分布式文件系统)中删除output
[zjy@server4 hadoop]$ hdfs dfs -rm -r output
Deleted output
做wordcount(词频统计)
[zjy@server4 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
从dfs(分布式文件系统)中查看output的内容
[zjy@server4 hadoop]$ hdfs dfs -cat output/*
2020-06-04 12:06:42,473 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
"*" 21
"AS 9
"License"); 9
"alice,bob 21
"clumping" 1
(ASF) 1
(root 1
(the 9
4. 完全分布式的hdfs
准备两台虚拟机
server5 server6
[zjy@server4 hadoop]$ sbin/stop-dfs.sh # 停掉dfs
Stopping namenodes on [server4]
Stopping datanodes
Stopping secondary namenodes [server4]
安装nfs,使用nfs共享文件
[root@server4 ~]# yum install nfs-utils
[root@server5 ~]# yum install nfs-utils
[root@server6 ~]# yum install nfs-utils
使用zjy用户
[root@server4 zjy]# id zjy
uid=1000(zjy) gid=1000(zjy) groups=1000(zjy)
[root@server5 ~]# useradd zjy
[root@server5 ~]# id zjy
uid=1000(zjy) gid=1000(zjy) groups=1000(zjy)
[root@server6 ~]# useradd zjy
[root@server6 ~]# id zjy
uid=1000(zjy) gid=1000(zjy) groups=1000(zjy)
将/home/zjy目录以读写的方式,同步给uid为1000和gid为1000的用户
[root@server4 zjy]# vim /etc/exports
/home/zjy *(rw,anonuid=1000,anongid=1000)
[root@server4 zjy]# systemctl start nfs
[root@server4 zjy]# showmount -e
Export list for server4:
/home/zjy *
[root@server4 zjy]# systemctl start rpcbind
[root@server5 ~]# systemctl start rpcbind
[root@server5 ~]# showmount -e 172.25.60.4
Export list for 172.25.60.4:
/home/zjy *
[root@server6 ~]# systemctl start rpcbind
[root@server6 ~]# showmount -e 172.25.60.4
Export list for 172.25.60.4:
/home/zjy *
[root@server5 ~]# mount 172.25.60.4:/home/zjy /home/zjy/
[root@server6 ~]# mount 172.25.60.4:/home/zjy /home/zjy/
[root@server5 ~]# su - zjy
[root@server6 ~]# su - zjy
补充:rpc和nfs的原理
RPC(远程调用服务)。因为NFS支持的功能特别多,而不同的功能都会使用不同的程序来启动,每启动一个功能端口就会用一些端口来传输数据,因此,NFS的功能所对应的端口才无法固定,而是随机取用一些未被使用的小于1024的端口来进行传输。(常规服务端口:0~655535,1024一下,系统服务常用)
所以,客户端要准确的获得NFS服务器所使用的端口,就需要RPC服务。 NFS RPC最主要的功能就是记录每个NFS功能所对应的端口号,并且在NFS客户端请求时将该端口和功能对应的信息传递给请求数据的NFS客户端,让客户端可以链接到正确的端口上去,从而实现数据传输。(本人觉得RPC像是中介)
RPC怎样知道NFS的每个端口呢?
原因是,当NFS服务启动时会随机取用数个端口,并主动向RPC服务注册取用的相关端口信息,这样,RPC服务就可以知道每个端口所对应的NFS功能了,然后RPC服务使用固定的端口号111来监听NFS客户端提交的请求,并将正确的NFS端口答应给NFS客户端,这样一来,就可以让NFS客户端与服务端进行数据传输了。
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop/etc/hadoop
[zjy@server4 hadoop]$ vim hdfs-site.xml # 将副本数改为2
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
修改works节点
[zjy@server4 hadoop]$ vim workers
172.25.60.5
172.25.60.6
重新初始化
[zjy@server4 hadoop]$rm -fr /tmp/*
[zjy@server4 hadoop]$hdfs namenode -format
[zjy@server4 hadoop]$sbin/start-dfs.sh
[zjy@server4 hadoop]$ jps
31219 NameNode
31572 Jps
31445 SecondaryNameNode
[zjy@server5 ~]$ jps
14407 Jps
14346 DataNode
jps是什么:jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的2113一个显示当前所有java进程5261pid的命令,简单实4102用,非常适合在1653linux/unix平台上简单察看当前java进程的一些简单情况。
截取200M的文件
[zjy@server4 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 0.157262 s, 1.3 GB/s
当文件大小打与128M会自动切分

在dfs(分布式系统)上创建目录,因为刚才从新格式化了
[zjy@server4 hadoop]$ hdfs dfs -mkdir /user/
[zjy@server4 hadoop]$ hdfs dfs -mkdir /user/zjy
上传截取的200M的文件
[zjy@server4 hadoop]$ hdfs dfs -put bigfile
2020-06-04 17:39:49,704 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-04 17:40:02,113 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
划分为两个block,因为文件超过了128M


4.1 节点的热添加(不关闭dfs基础上添加节点)
准备一台新的虚拟机server7
[root@server7 ~]# yum install nfs-utils
[root@server7 ~]# useradd zjy
[root@server7 ~]# systemctl start rpcbind
[root@server7 ~]# showmount -e 172.25.60.4
Export list for 172.25.60.4:
/home/zjy *
[root@server7 ~]# mount 172.25.60.4:/home/zjy/ /home/zjy/
做server7的免密
[zjy@server4 hadoop]$ ssh-copy-id 172.25.60.7
在workers中加入172.25.60.7
[zjy@server4 hadoop]$ vim etc/hadoop/workers
172.25.60.5
172.25.60.6
172.25.60.7
将7加入datanode
[zjy@server7 ~]$ hdfs --daemon start datanode
[zjy@server7 ~]$ jps
4161 Jps
4146 DataNode

将节点修改为3个
[zjy@server4 hadoop]$ pwd
/home/zjy/hadoop
[zjy@server4 hadoop]$ vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
hadoop的工作原理:
客户端写数据:
1.客户端向namenode写文件
2.客户端需要告诉nanenode文件切分的个数和block的副本数
3.namenode向客户端发送datanode列表(根据客户端的距离发送datanode列表,第一个副本在距离最近机架的datadns上,第二个副本在不同机架的datanode上,第三个副本与第二个副本在同一机架的不同datanode上,同一个机架上不超过2,hadoop具有机架感应技术),
4.客户端将数据发送到datanode上,datanode接受数据
5.并存盘,
6.接着datanode将推送数据到其他datanode节点,
7.然后向namenode汇报数据接收完毕并保存,
8.最后客户端发送数据完毕要求关闭文件。
9.namenode上元数据存盘
客户端读数据:
1.客户端向namenode发送读请求
2.namenode向客户端发送block列表(namenode存储两张标,一张block表,一张datanode列表)
3.客户端去datanode上读数据
hadoop的故障检测机制:
1.节点故障检测
2.通信故障
3.数据块损坏
datanode每隔3秒向namenode发送心跳信息,namenode10分钟接收不到datanode的信息认为datanode宕机,客户端发送数据的同时会发送总和校验码,datanode存储数据的同时也存储了总和校验码,保证数据的完整性,datanode接收block完成会向客户端返回ack(确认),datanode会定期发送完整数据块(block)信息到namenode,namenode会根据datanode发送的block信息来更新block列表的信息
hdfs总结:
1.hdfs数据master与slave结构,一个集群只有一个namenode,可以有多个datanode
2.hdfs存储机制保存了多个副本,当次俄入1T文件时,我们需要3T的存储,3T的网络流量宽带;系统提供容错机制,副本丢失或宕机可自动恢复,保证系统高可用性。
3.hdfs默认会将文件分割成block。然后将block按键值对存储在hdfs上,并将键值对的映射存到内存中。如果小文件太多,会导致内存的负担很重。
4.hdfs采用的是一次写入多次读取的文件访问模型,一个文件经过创建、写入、和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且是高吞吐量的数据访问成为可能。
5.hdfs存储理念是以最少的前买最烂的机器并实现最安全、高难度的分布式文件系统(高容错性低成本),hdfs认为机器故障是中常态,所以在设计时充分考虑到单个机器故障,单个文件丢失等情况。
6.hdfs容错机制:
节点失败检测机制,datanode每隔3秒向namenode发送心跳信号,10分钟收不到,认为宕机
通信故障检测机制,只要发送了数据,接收方就会返回确认码
数据错误检测机制,在传输数据时,通十四会发送总和校验码
4.2 mapreduce(作用运行程序)
[zjy@server4 hadoop]$ vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
添加$HADOOP_MAPRED_HOME变量
[zjy@server4 hadoop]$ vim etc/hadoop/hadoop-env.sh
export HADOOP_HOME=/home/zjy/hadoop
export HADOOP_MAPRED_HOME=/home/zjy/hadoop
[zjy@server4 hadoop]$ vim etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
[zjy@server4 hadoop]$ jps
17955 SecondaryNameNode
18180 ResourceManager
18485 Jps
17726 NameNode
[zjy@server5 ~]$ jps
5322 Jps
5212 NodeManager
5102 DataNode
mapreduce工作原理:
1.客户端向resourcemanager(rm)申请应用
2.返回应用所需资源的提交路径
3.拷贝job资源到hdfs上
4.用户端向rm申请运行mapreduce app master
5.rm初始化应用为task,task进入fifo队列
6.nodemaster会从rm领取task任务
7.在nodemaster创建容器(不是docker,是java的抽象事件,封装cpu内存资源)来运行appmaster
8.从hdfs上下载资源到nodemaster上的容器中
9.appmaster向rm申请运行mapreduce任务,并注册自己
10.新的容器从rm上领域map任务
11.旧的容器向新容器发送程序启动脚本
12.申请运行reduce任务
13.job运行完毕,appmaster向rm注销自己(释放资源)
14.客户端可以从appmaster上获取任务进度
开启172.25.60.4:8088端口监控任务资源
