pyppeteer爬取JavaScript渲染的动态网页 问题总结及代码实现
目录
- 前言 & 问题描述
- 两种解决方案
- 人工分析
- ”模拟“一个浏览器
- pyppeteer介绍
- 初次尝试
- 修改chromium下载源
前言 & 问题描述
今天在抓取网页数据的时候,遇到了一个非常普遍的问题,就是网页的数据是JavaScript渲染的,我们从html的源码中无法获得这些数据,这些数据是在执行JavaScript脚本之后,异步地渲染到页面上的。
比如我们想要爬取一个比赛网站的数据:http://live.win007.com/
我们通过浏览器F12(F12展示的是执行过JavaScript之后的html代码)可以很快的定位这些数据

但是我们无法使用常规的方法爬取到数据,比如我们使用requests来获取html源码,发现并不能获取数据:
import requests
# requests获取博客页面html文本
url = "http://live.win007.com/"
r = requests.get(url, headers=send_headers)
r.encoding = "utf-8"
html = r.text
print(html)
这和我们【查看网页源代码】是一样的,我们只能够浏览网页最初的模样,即如下图所示,当然是没有数据的,我们理所应当的在html源代码里面也发现不了数据。

短暂的执行JavaScript之后,才能正常显示数据,JavaScript改变了一些标签的innerHtml,导致页面数据变化

综上所述,我们需要找到一种解决方案,使得爬虫能够返回JavaScript执行后的html文本。
两种解决方案
人工分析
我们打开浏览器F12开发者模式,我们分析该页面的JavaScript脚本从那些URL请求数据,然后我们伪造一个这样的请求,就能够获取数据了,这个方法的优点是原生的request也可以做到,缺点是每个不同的网页,都要分析,很麻烦,而且请求返回的xml或者json数据,很难读,往往需要我们再次格式化才能看懂。
”模拟“一个浏览器
我们想到,通过浏览器F12,可以查看JavaScript执行之后渲染的html源码,那么只要模拟一个浏览器去执行页面的js,不就可以获取执行后的html及其数据了吗。这个方法的优点是复杂度低,缺点是速度慢,因为维护一个完整的浏览器,需要额外的cpu与系统资源的开销。
作为懒狗,我当然选择方法2,所以我们需要一种能够“模拟”完整的浏览器,来帮助我们执行JavaScript并且获得渲染后的页面及其数据。pyppeteer提供了良好的支持。
pyppeteer介绍
说到pyppeteer,就不得不提一下 puppeteer,他是谷歌chrome团队开发的工具,通过一些接口,控制名为chromium的【无头浏览器】,其实可以理解为没有界面的浏览器,puppeteer可以模拟实际的浏览器。
puppeteer主要用于对网页的测试。它可以模拟浏览器的种种行为,包括执行JavaScript,并且返回我们期望的结果,这是好的。
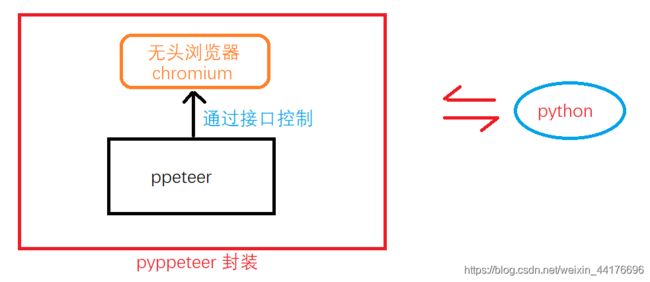
pyppeteer是对ppeteer的python封装,而ppeteer又基于chromium浏览器,下面的图片给出了其依赖关系
初次尝试
我们运行一个简单的python代码,就可以通过pyppeteer来爬取动态页面,可是上面也提到过,pyppeteer基于chromium,在首次运行pyppeteer的时候,程序会自动下载并且安装chromium。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://live.win007.com/')
print(await page.content())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
进度条一动不动:

GTND,你倒是动啊
你懂的。但凡和【从公共库下载文件】沾点边的代码,多少都事与愿违,因为伟大的长↑城↓防火墙,我们无法直接从pyppeteer的默认路径,下载chromium的安装包。故,我们需要手动修改pyppeteer的默认下载chromium浏览器的路径。
修改chromium下载源
首先我们查看pyppeteer默认需要的chromium版本,运行以下代码
print('chromium版本: ' + pyppeteer.__chromium_revision__)
输出
chromium版本: 588429
然后我们打开chromium的淘宝镜像:https://npm.taobao.org/mirrors/chromium-browser-snapshots

我们点击win_x64,搜索,选择我们需要的文件,如果是linux同理
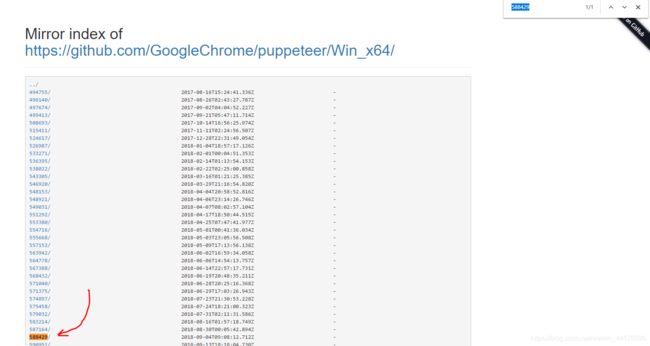
点进去,我们找到下载链接(怎么点的win64还是win32。。。)

点击链接,复制下载链接
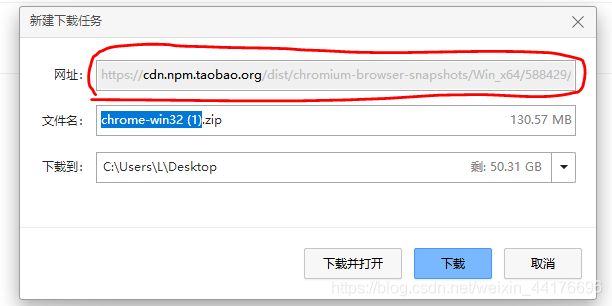
下载链接是:https://cdn.npm.taobao.org/dist/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip
我们在运行pyppeteer程序之前加上这样几句代码,pyppeteer的chromium_downloader对象拥有一个字典变量downloadURLs,它记录了各个系统的默认下载源,其中key是系统,value是下载源URL,在第一次运行时,我们修改默认的URL
import pyppeteer
pyppeteer.chromium_downloader.downloadURLs['win64'] = 'https://cdn.npm.taobao.org/dist/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip'
可以看到,这里我们将pyppeteer的默认chromium的下载路径改为镜像的路径,然后再执行爬虫代码,这样就可以自动下载chromium了,执行的完整代码如下:
import pyppeteer
pyppeteer.chromium_downloader.downloadURLs['win64'] = 'https://cdn.npm.taobao.org/dist/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip'
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://live.win007.com/')
print(await page.content())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
可以看到,在下了,而且很快。

下载完成之后,马上就能够爬取到网页的html了

我们在结果中,搜索一下JavaScript动态渲染的数据,比如我们搜索:乌兰巴托FC

可以看到确实有数据,我们打开浏览器的开发者模式看一看:
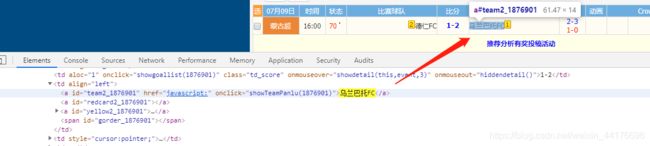
爬取到的数据和F12的一致,说明我们成功执行了JavaScript并且获得了渲染之后的页面及其数据。大成功!