人群计数:MCNN--Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
- 啃计数论文,第三篇。
论文目标:在任意的静态图像,任意的相机视角和人群密度下进行准确的人群计数
**论文三大贡献:
- ShanghaiTech数据集
- 提出多列全卷积网络来计数,性能提高
- 用 1x1 的卷积核来代替全连接,使得输入图片尺寸可以任意**
Related Work
-
基于检测:扫描一个视频序列中连续两帧来估计人群数量。该方法基于boosting appearance and motion features。对于密集人群不太实用。
-
基于视觉特征轨迹聚类:对于视频计数来说,用KLT跟踪器和聚类的方法,通过轨迹聚类得到的数目来估计人数。但这对于单张静止的图片无效。
-
基于特征回归:1)前景分割,2)再从中提取各种信息,比如人群区域,边缘检测,纹理特征,3)找一个回归函数—从特征直接映射到人数 :其中线性或者分段线性函数比较简单,性能还行,其他比较先进的方法如 岭回归、高斯过程回归及神经网络。
先来讲讲第一大贡献(我认为的第一):
**
ShanghaiTech数据集
**
现存的数据集不仅匮乏,还存在很多问题。比如:
- UCSD, WorldExpo ’ 10的拍摄角度很单一,即图像中的场景透视图没有变化,这样使得基于它们训练出来的模型泛化性能不好。
- UCSD, UCF CC 50的数据集规模不大。
- UCF cc50的场景多样性不足。
该数据集包括1198个图像,330,165个注释头。它包含两部分:A部分和B部分.A部分由482个图像组成,这些图像是从Internet中随机选择的,而B部分是从上海街道上的大都市区拍摄的。与B部分相比,A部分具有相当大的密度图像。
图片收集好了,但离成为数据集还差得远。首先是人工标注,对于一张图片,在图中有人头的地方进行标注。即如果在像素Xi 处有一个人头,我们就在这里放置一个脉冲函数。如果一张图片中有N个人头的话,那么这张图片就可以如下表示:

标注好了,然后让该函数与高斯核进行卷积操作,便得到了图片整体的密度图。但考虑到实际是3D场景以及存在透视失真情况,该密度图不能直接用。
解决方法:假设每个头部周围的人群分布比较均匀,那么头部与其最近的k个邻居之间的平均距离有关系,然而头部尺寸很难获得。我们发现实际场景中头部尺寸的大小通常是相邻两个人的中心之间的距离。所以,对于拥挤场景,我们根据该方法来自适应的确定每个人的参数。
最终密度图的生成公式:
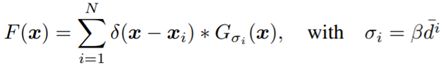
在每一个点用的高斯核Gσi (x)都考虑到它周围的人头σi = β di(平均),这样保证了密度图的精确性。(取周围m个人来计算di)
![]()
**
多列卷积网络
**
人群计数实现的方式:多列卷积神经网络模型。
那么,这个模型应该具备的能力:在不分割前景的情况下估计人群的数量,需要综合利用不同尺度的特征来准确估计不同图像的人群数量,且模型能自动学习有效特征。
论文思路:该文和多数工作一样,先求取一个实际图片到密度图的映射,然后通过对密度图进行高斯卷积求和,得到人群数量。
为什么要用多列卷积尼?
答:由于透视失真,图片常包含不同尺寸的头,只有一种卷积核貌似不够,所以提出多列不同卷积以适应多种尺寸。
点评:最后18年的CSRNet验证了每一列学习到的信息都差不多,推翻了该结论。但是16年时还比较倾向于较浅层的结构,用一列深层网络完全可以解决。
网络结构如图:
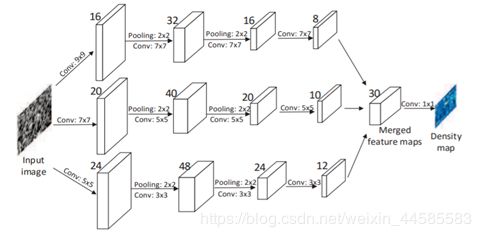
一共3列,每一列的结构大致相同,不同之处:卷积核的数量和尺寸
最后,网络用了一个的卷积层来把多通道的张量变成平面,取代了原来的全连接,使得输入图片的尺寸可以任意,使得该网络模型的应用范围更加广泛。
预测的密度图出来了,如何评判性能的好坏尼?采用的是欧几里得距离的变形 :

Fi 是真值,前面那个F(Xi , 0)是预测的值,1/2 是为了计算过程中求导方便,加快计算速度。
**
MCNN模型优化
**
做法 :先单独且完整的预训练了每列的网络,再合并微调。
在实际使用中,面对目标域样本较少时,我们采用固定前几层网络,微调后几层网络来实现。
这样做的原因:在原来数据集的学习上,模型已经较好的学习到了特征的提取模式,对于目标域和源域(开始训练的数据集)差距不大的情况下,这种模式是使用的。微调后面几层网络是因为这样模型的输出与目标域更为接近。
**
迁移学习
**
论文末尾,作者用MCNN验证了正确使用迁移学习的姿势。

“MCNN w/o transfer” means we train the MCNN using the training data in UCF CC 50 only, and data from the source domain are not used. “MCNN trained on Part A” means we do not use the training data in the target domain to fine-tune the MCNN trained in the source domain.
论文地址:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Zhang_Single-Image_Crowd_Counting_CVPR_2016_paper.pdf
github地址(官方):
https://github.com/svishwa/crowdcount-mcnn
(非官方):
https://github.com/wwq-online/MCNN_REPRODUCTION
如果你也对人群计数感兴趣的话,不妨关注走一波?(虽然我菜,但是我积极啊),后期会继续更新相关论文。