触类旁通Elasticsearch:管理
目录
一、模板
二、动态映射
三、分配感知
四、监控
1. 检查集群健康状况
2. 慢日志、热线程和线程池
3. 内存
4. 操作系统缓存
5. 存储限流
五、备份与恢复
1. 快照API
2. 将数据备份到共享的文件系统
3. 从备份中恢复
《Elasticsearch In Action》学习笔记。
一、模板
(1)创建模板
当待创建的索引与之前的索引有相同的设置和映射时,非常适合使用索引模板。正如其名,索引模板将会用于和预定义名称模式相匹配的索引创建,以确保所有匹配索引的设置一致。例如:
curl -XPUT 172.16.1.127:9200/_template/logging_index_all?pretty -H "Content-Type: application/json" -d '
{
"template": "logstash-11-*",
"order": 1,
"setting": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"store": false
}
}
}
},
"alias": {
"november": {}
}
}'使用PUT命令后,告诉ES当一个索引的名称和logstash-11-*模式匹配时,运用这个模板。这个模板更进一步地设置了别名,这样可以聚合某个指定月份内的全部索引。必须手动为每个月的索引重新命名,但别名提供了一个便捷方法来按月合并日志事件的索引。
还可以选择在文件系统中配置模板,有时这使得模板更容易管理和维护。配置文件遵循以下基本规则:
- 模板配置必须是JSON格式。方便起见,让文件名以.json扩展名结尾:
.json。 - 模板定义应该位于ES配置所在的地方,位于一个模板目录下。该路径在集群配置文件(elasticsearch.yml)中被定义为path.conf,如
/config/templates/*。 - 模板定义应该放在有资格成为主节点的节点之上。
使用之前的模板定义,template.json文件应该看上去是这样的:
{
"template" : "logstash-11-*"
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 1
},
"mappings" : { … },
"aliases" : { "november" : {} }
}(2)模板合并
ES允许用户使用不同的设置来配置多个模板。这样就可以扩展之前的例子,配置一个模板按月处理日志事件,然后配置一个模板将全部日志事件存储到单个索引中。
curl -XPUT 172.16.1.127:9200/_template/logging_index_all?pretty -H "Content-Type: application/json" -d '
{
"template": "logstash-11-*",
"order": 1,
"setting": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"store": false
}
}
}
},
"alias": {
"november": {}
}
}'
curl -XPUT 172.16.1.127:9200/_template/logging_index?pretty -H "Content-Type: application/json" -d '
{
"template": "logstash-*",
"order": 0,
"setting": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"store": true
}
}
}
}
}'在这个例子中,最高优先级的模板负责11月的日志,第二个模板聚合了所有索引,而且还包含了日期映射的不同设置。这个配置中需要注意的是order属性。这个属性意味着最低的顺序编号首先生效,而更高的顺序编号会覆盖较低编号的设置。由于这一点,这两个模板设置将会合并,其结果就是所有11月的日志没有存储日期字段。
(3)检索索引模板
# 检索全部模板
curl -XGET 172.16.1.127:9200/_template?pretty
# 检索单个模板
curl -XGET 172.16.1.127:9200/_template/logging_index?pretty
# 检索多个模板
curl -XGET 172.16.1.127:9200/_template/logging_index_1,logging_index_2?pretty
# 检索模式匹配的模板
curl -XGET 172.16.1.127:9200/_template/logging_*?pretty(4)删除模板
curl -XDELETE 172.16.1.127:9200/_template/logging_index?pretty
curl -XDELETE 172.16.1.127:9200/_template/logging_index_all?pretty二、动态映射
(1)开启和关闭动态映射
默认地,ES利用了动态映射(dynamic mapping):也就是为文档的新字段确定数据类型的能力。初始索引一篇文档时,ES可以动态创建一个映射以及每个字段的数据类型。用户可以告知ES忽视新的字段或者对于未知字段抛出异常来改变这一行为。通常希望限制新字段的加入,以避免数据的污染并维持现有的数据模式定义。可以在elasticsearch.yml配置中将index.mapper.dynamic设置为false,来关闭新映射的动态创建。
curl -XPUT 172.16.1.127:9200/first_index?pretty -H "Content-Type: application/json" -d '
{
"mappings": {
"person": {
"dynamic": "strict", # 如果在索引时碰到一个未知字段,抛出一个异常
"properties": {
"email": {
"type": "text"
},
"created_date": {
"type": "date"
}
}
}
}
}'
curl -XPUT 172.16.1.127:9200/second_index?pretty -H "Content-Type: application/json" -d '
{
"mappings": {
"person": {
"dynamic": "true", # 允许新字段的动态创建
"properties": {
"email": {
"type": "text"
},
"created_date": {
"type": "date"
}
}
}
}
}'第一个映射限制了在person映射中创建新的字段。如果试图使用未映射的字段来插入文档,ES将返回异常。
curl -XPOST 172.16.1.127:9200/first_index/person?pretty -H "Content-Type: application/json" -d '
{
"email": "foo@bar.com",
"created_date": "2014-09-01",
"first_name": "Bob"
}'返回以下错误:
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [first_name] within [person] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [first_name] within [person] is not allowed"
},
"status" : 400
}同样的索引语句,在第二个映射上可以正常执行。
(2)动态映射和模板一起使用
在处理包含UUID的数据时,下面的例子解决了一个简单的问题。有一些包含连字符的唯一字符数字串,如“b20d5470-d7b4-11e3-9fa6-25476c6788ce”。用户不想ES分析这些字符串,否则构建索引分词时,默认的分析器会将UUID按照连字符进行切分。用户希望的是根据完整的UUID字符串来搜索,所以要让ES将整个字符串作为单一的分词来存储。在这种情况下,需要告诉ES不要分析任何以“_guid”结尾的string字段。
curl -XPUT 172.16.1.127:9200/myindex?pretty -H "Content-Type: application/json" -d '
{
"mappings": {
"my_type": {
"dynamic_templates": [{
"UUID": {
"match": "*_guid", # 匹配以_guid结尾的字段
"match_mapping_type": "string", # 匹配字段必须为字符串型
"mapping": { # 定义匹配之后,想应用的映射
"type": "text", # 设置为字符串类型
"index": "not_analyzed" # 索引的时候,不要分析这些字段
}
}
}]
}
}
}'动态模板是一个快捷的方法,将某些乏味的ES管理进行了自动化。
三、分配感知
(1)基于分片的分配
分配感知允许用户使用自定义的参数来配置分片的分配。这是在ES部署中很常见的一种最佳实践,因为它通过确保数据在网络拓扑中均匀分布,来减少单点故障的概率。由于部署在同一物理机架上的节点可能拥有相邻的优势,无须网络传输,所以用户也可以体验更快的读操作。
通过定义一组键,然后在合适的节点上设置这个键,就可以开启分配感知。例如,可以像下面这样编辑elasticsearch.yml。
cluster.routing.allocation.awareness.attributes: rack可以赋多个值给感知属性,如:
cluster.routing.allocation.awareness.attributes: rack, group, zone使用感知参数rack来对集群内的分片进行分组。用户可以为每个节点修改elasticsearch.yml,按照期待的网络配置来设置该值。ES允许用户在节点上设置元数据。在这种情况下,元数据的键将成为分配感知参数。
node.rack: 1图1展示了拥有默认分配设置的集群。
 图1 使用默认分配设置的集群
图1 使用默认分配设置的集群
这个集群的问题在于其主分片和副本分片都在同一个主机架上。有了分配感知的设置,就可以避免这样的风险,如图2所示。
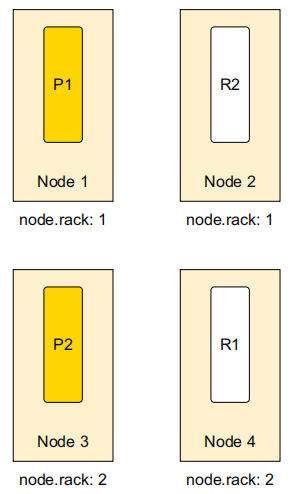 图2 使用分配感知的集群
图2 使用分配感知的集群
使用分配感知,主分片不会被移动,但是副本分片将被移动到拥有不同node.rack参数值的节点。分片的分配是一个很方便的特性,用来防止中心点失败导致的故障。常见的方法是按地点、机架,甚至是虚拟机来划分集群的拓扑。
(2)强制性的分配感知
当用户事先知道值的分组,而且希望限制每个分组的副本分片数量时,强制分配感知是很有用处的。如在AWS或其它跨地区云服务提供商上使用多地区分配。如果一个区域宕机或者无法访问,限制剩下某个区域内的副本分片数量。通过这样的措施,用户将降低从另一组转移过多副本分片至本分组的危险。
用户想在区域级别使用强制分配。首先指定了zone属性,然后为该分组添加多个维度:us-east和us-west。在elasticsearch.yml中,添加下列两行:
cluster.routing.allocation.awareness.attributes: zone
cluster.routing.allocation.force.zone.values: us-east, us-west假设在东部地区启动了一组节点,这些节点的配置都是node.zone: us-east。这里将使用默认的设置,每个索引5个主分片和1个副本分片。由于没有其它的地区值,只有索引的主分片被分配。
现在所做的限制是副本分片,使其只会均衡到没有相应zone值的节点上。如果使用node.zone: us-west启动了西部集群,那么从us-east地区来的副本分片会分配到西部集群。定义为node.zone: us-east的节点之上永远不会存在东部副本分片。理想情况下,用户会为node.zone: us-west的节点进行同样的操作,以确保副本分片永远不会存在于同一个地区。注意,如果失去了和西部地区us-west的联系,不会有东部副本分片在东部地区us-east上创建,反之亦然。
分配感知设置还可以通过集群设置API在运行时进行修改。修改可以是持久的(persistent),在ES重启后仍然生效,也可以是临时的(transient)。
curl -XPUT 172.16.1.127:9200/_cluster/settings?pretty -H "Content-Type: application/json" -d '
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "zone",
"cluster.routing.allocation.awareness.force.zone.values": "us-east,us-west"
}
}'集群分配使得集群在容错性上有所区别。要想动态禁用集群的分配感知功能,可以运行如下设置:
curl -XPUT 172.16.1.127:9200/_cluster/settings?pretty -H "Content-Type: application/json" -d '
{
"persistent": {
"cluster.routing.allocation.enable": "all",
"cluster.routing.allocation.awareness.attributes": ""
}
}'四、监控
ES通过它的API接口提供了丰富的信息:内存消耗、节点成员、分片分发以及I/O的性能。
1. 检查集群健康状况
集群的健康API接口提供了一个方便但略有粗糙的概览,包括集群、索引和分片的整体健康状况。这通常是发现和诊断集群中常见问题的第一步。
curl -XGET 172.16.1.127:9200/_cluster/health?pretty返回以下信息:
{
"cluster_name" : "ES_cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 13,
"active_shards" : 26,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}- relocating_shards:节点间移动的分片数量。大于0表示ES正在集群内移动数据的分片,来提升负载均衡和故障转移。这通常发生在添加新节点、重启失效的节点或者删除节点的时候,因此出现了这种临时现象。
- initializing_shards:新创建的分片数量。当用户刚刚创建了一个索引或者重启一个节点的时候,这个数值会大于0。
- unassigned_shards:集群中定义的,却未能发现的分片数量。这个值大于0的最常见原因是有尚未分配的副本分片。
从输出结果的status属性可以看到集群状态是绿色的。集群状态值的定义和含义如下:
- 绿色:主分片和副本分片都已经分发而且运作正常。
- 黄色:通常这是副本分片丢失的信号。这个时候,unassigned_shards的值很可能大于0,使得集群的分布式本质不够稳定。进一步的分片损坏将导致数据丢失,需要查看任何没有正确初始化或运作的节点。
- 红色:这是危险的状态,无法找到集群中的主分片,使得主分片的上的索引操作不能进行,而且导致了不一致的查询结果。同样,很可能一个或多个节点从集群中消失。
当集群状态不是绿色或者unassigned_shards大于0时,可以查看更细粒度的信息,如可以添加level参数,深入了解哪些索引受到了分片未分配的影响。
curl -XGET '172.16.1.127:9200/_cluster/health?level=indices&pretty'2. 慢日志、热线程和线程池
(1)慢日志
ES提供了两个项目日志来区分慢操作,它们很容易在集群配置文件中设置:慢查询日志和慢索引日志。默认情况下两者都是关闭的。日志输出是分片级别的。因此在相应的日志文件中,一个操作可能由若干行表示,每行表示一个分片上的情况。分片级别日志的好处在于,用户可以根据日志输出更好地定位有问题分片和节点,如下所示。注意这些设置可以通过'{index_name}/_settings'端点进行修改。
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 1s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 1s
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms如上所示,可以为搜索的两个阶段设置阈值:查询和获取。日志的级别(warn、info、debug和trace)允许用户细粒度地控制何种级别的内容要被记录下来。典型的慢日志输出看上去是这样的:
[2014-11-09 16:35:36,325][INFO ][index.search.slowlog.query] [ElasticIQ-Master] [streamglue][4] took[10.5ms], took_millis[10], types[], stats[],
search_type[QUERY_THEN_FETCH], total_shards[10],
source[{"query":{"filtered":{"query":{"query_string":{"query":"test"}}}},...]
Licensed to Thomas Snead 354 CHAPTER 11 Administering your cluster
[2014-11-09 16:35:36,339][INFO ][index.search.slowlog.fetch] [ElasticIQ-Master] [streamglue][3] took[9.1ms], took_millis[9], types[], stats[],
search_type[QUERY_THEN_FETCH], total_shards[10], ... 对于识别性能问题,一个重要部分是查询执行的时间:took[##ms]。此外,了解相关的分片和索引也是很有帮助的,这些都是通过[index][shard_number]符号来标识的,在这个例子中它是[streamglue][4]。
在发现索引操作过程中的瓶颈时,同样有价值的是慢索引日志。它的阈值是在集群配置文件中定义,或者是通过索引更新设置的API接口定义。
index.indexing.slowlog.threshold.index.warn: 10s
index.indexing.slowlog.threshold.index.info: 5s
index.indexing.slowlog.threshold.index.debug: 2s
index.indexing.slowlog.threshold.index.trace: 500ms任何达到阈值的索引操作将被写入日志文件,而且用户将看到索引操作的索引名、分配数[index][shard_number] ([bitbucket][2])和持续时间took[4.5ms]。
[2014-11-09 18:28:58,636][INFO ][index.indexing.slowlog.index] [ElasticIQ-Master] [bitbucket][2] took[4.5ms], took_millis[4], type[test],
id[w0QyH_m6Sa2P-juppUy3Tw], routing[], source[] ...(2)热线程API接口
如果遇到过集群CPU使用率高居不下,则将发现热线程(hot_threads)API对于识别被阻塞并导致问题的具体进程,是很有用处的。热线程API提供了集群中每个节点上的一系列阻塞线程。和其它接口不同,热线程并不返回JSON格式的内容,而是如下格式化文本。
curl -XGET '172.16.1.127:9200/_nodes/hot_threads'下面是输出的样例:
::: [ElasticIQ-Master][AtPvr5Y3ReW-ua7ZPtPfuQ][loki.local][inet[/
127.0.0.1:9300]]{master=true}
37.5% (187.6micros out of 500ms) cpu usage by thread
'elasticsearch[ElasticIQ-Master][search][T#191]
10/10 snapshots sharing following 3 elements
...结果的第一行包括了节点的身份,这是线程信息属于哪个CPU的第一个标识。
37.5% (187.6micros out of 500ms) cpu usage by thread
'elasticsearch[ElasticIQ-Master][search][T#191]这里可以看到37.5%的CPU处理花费在了搜索(search)线程上。可以调优导致CPU高峰的搜索查询。希望这里不要总是出现搜索。ES可能显示其它的值,如merge、index,来表明此线程进行的操作。由于cpu usage的标识,可知这是和CPU相关的。其它可能的输出标识有阻塞占比block usage,表示线程被阻塞了,以及等待占比wait usage表示线程在等待状态。
10/10 snapshots sharing following 3 elements在堆栈轨迹(stack trace)之前的最后一行表示ES在几毫秒中进行了10次快照,然后发现有如下同样堆栈轨迹的线程在这10次中都出现了。
每过几毫秒,ES就会收集每个线程的持续时间、状态(等待/阻塞)、等待持续时间以及阻塞持续时间等相关信息。过了指定的时间间隔(默认是500毫秒),ES会对同样的信息进行第二轮收集操作。在每次收集过程中,它会对每个堆栈轨迹拍摄快照。用户可以通过hot_threads API请求添加参数,来调整信息收集的过程:
curl -XGET '172.16.1.127:9200/_nodes/hot_threads?type=wait&interval=1000ms&threads=3'- type:cpu、wait和block之一。需要快照的线程状态类型。
- interval:第一次和第二次检查之间的等待时间。默认是500毫秒。
- threads:排名靠前的“热”线程的展示数量。
(3)线程池
集群中每个节点通过线程池来管理CPU和内存的使用。ES将试图使用线程池以获得更好的节点性能。在某些情况下,需要手动地配置并修改线程池管理的方式,来避免失败累积(雪崩效应)的场景。在负载很重的情况下,ES可能会孵化出上千个线程来处理请求,导致集群宕机。例如,对于一个主要使用bulk索引API的应用程序,需要为其分配较多的线程。否则,bulk index请求就会变得负载很重,而新进来的请求就会被忽略。
可以在集群配置中调节线程池的设置。线程池按照操作进行规划,并根据操作的类型配置默认值。
- bulk:默认的固定的值,基于可用于所有bulk批量操作的处理器数量。
- index:默认的固定的值,基于可用于索引和删除操作的处理器数量。
- search:默认的固定的值,3倍可用于计数和搜索操作的处理器数量。
可以在elasticsearch.yml文件中设置线程池队列的大小以及线程池的数量。集群设置API也允许用户在运行中的集群上更新这些设置。
# Bulk Thread Pool
threadpool.bulk.type: fixed
threadpool.bulk.size: 40
threadpool.bulk.queue_size: 200有两种线程池类型,fixed和cache。fixed的线程池类型保持固定数量线程来处理请求,并使用后援队列来处理等待执行的请求。在本例中,queue_size参数控制了线程的数量,默认是CPU核数的5倍。而cache线程池类型是没有限制的,这意味着只要有任何等待执行的请求,系统就会创建一个新的线程。
3. 内存
(1)堆大小
ES是运行于Java虚拟机(JVM)之上的Java应用程序,所以它受限于垃圾回收器(garbage collector)的内存管理。垃圾回收器的基本概念是非常简单的:当空闲内存不够用的时候触发垃圾回收,清理已经不再引用的对象,以此来释放内存供其它JVM应用程序使用。这些垃圾回收操作是很耗时间的,并会引起系统的停顿。将过多的数据加载到内存也会导致OutOfMemory的异常,引起失败和不可预测的结果,甚至是垃圾回收都无法解决的问题。
为了让ES更快,某些操作在内存中执行。例如,ES不仅加载和查询匹配的文档之字段数据,它还加载了索引中全部文档的值。通过快速访问内存中的数据,后续的查询会快得多。
JVM堆表示了分配给JVM上运行的应用程序之内存量。由于这个原因,理解如何调优其性能来避免垃圾回收停顿带来的副作用和OutOfMemory异常,是非常重要的。用户可以通过HAEP_SIZE环境变量来设置JVM堆的大小。当设置堆的大小时,记住以下两条法则:
- 最多50%可用系统内存:分配过多的系统内存给JVM就意味着分配给底层文件系统缓存的内存更少,而文件系统缓存确是Lucene需要经常使用的。
- 最大32GB内存:分配超过了32GB的内存之后,JVM的行为就会发生变化,不再使用压缩的普通对象指针(OOP)。这就意味着堆的大小少于32GB时,只需要使用大约一半的内存空间。
(2)过滤器和字段缓存
缓存允许用户有效地使用过滤器、切面(facet)和索引字段的排序。过滤器缓存将过滤器和查询操作的结果放在缓存中。这意味着使用过滤器的初始查询将其结果存储在过滤器缓存中。随后应用该过滤器的每次查询都会使用缓存中的数据,而不会去磁盘查找。在ES中存在两类过滤器缓存:索引级别的过滤器缓存和节点级别的过滤器缓存。
默认设置是节点级别的过滤器缓存。索引级别的过滤器缓存并不推荐,原因是用户无法预测索引将会存放在集群中的何处,因此无法预计内存的使用量。
节点级别的过滤器缓存采用的是LRU策略,即当缓存要满的时候,使用次数最少的缓存条目将被首先销毁,为新的条目腾出空间。如果要选择这种缓存,将index.cache.filter.type设置为node,或者不设置,因为它是默认值。可以使用indices.cache.filter.size属性来设置缓存大小。大小值是在节点的elasticsearch.yml配置中定义的,它既可以使用内存的百分比(20%),也可以使用静态的值(1024MB),百分比的属性是将节点上最大的堆内存作为总数来进行计算的。
字段数据缓存用于提升查询的执行时间。当运行查询的时候,ES将字段值加载到内存中并将它们保存在字段数据缓存中,用于之后的请求。由于在内存中构建这样的结构是成本很高的操作,不希望ES对于每次请求都执行这个动作,这样性能的提升才会明显。默认地,这是一个没有限制的缓存,也就是说它会持续增长,直到触动了字段数据的断路器。通过为字段数据缓存设置上限值,告诉ES一旦达到这个上限,就将数据从缓存结构中移除。
indices.fielddata.cache.size属性控制字段缓存大小,既可以设置为百分比(20%),也可以设置为静态的值(16GB)。这些值表示了用于缓存的节点堆内存空间之百分比或绝对值。
使用一些API接口可以获得字段数据缓存的当前状态。
- 按每个节点看:
curl -X GET "172.16.1.127:9200/_nodes/stats/indices/fielddata?fields=*&pretty" - 按每个索引看:
curl -X GET "172.16.1.127:9200/_stats/fielddata?fields=*&pretty" - 按每个节点每个索引看:
curl -X GET "172.16.1.127:9200/_nodes/stats/indices/fielddata?level=indices&fields=*&pretty"
设置fields=*将返回所有的字段名称和取值。这些操作将分析缓存的现有状态。需要特别注意返回信息中的evictions(移除数据)的次数。数据的移除是成本很高的操作,其发生表明字段数据的缓存规模可能设置的过小。
(3)断路器
字段数据缓存可能会不断增加最终导致OutOfMemory的异常。这是因为字段数据的规模是在数据加载之后才计算的。为了避免这种情况的发生,ES提供了断路器机制。
断路器是人为的限制,用来降低OutOfMemory异常出现的概率。它们通过反省某个查询所请求的数据字段,来确定这些数据加载到缓存后是否会使得整体的规模超出缓存的大小限制。在ES中有两个断路器,还有一个是父辈断路器,它在所有断路器可能使用的内存总量上又设置了一个限制。
- indices.breaker.total.limit:默认是堆内存的70%。不允许字段数据和请求断路器超越这个限制。
- indices.breaker.fielddata.limit:默认是堆内存的60%。不允许字段数据的缓存超越这个限制。
- indices.breaker.request.limit:默认是堆内存的40%。控制分配给聚合桶创建这种操作的堆大小。
断路器设置的原则是对其数值的设定要保守,因为断路器所控制的缓存需要和内存缓冲区、过滤器缓存和其它ES内存开销一起共用内存空间。
(4)避免切换
操作系统通过交换(swap)进程将内存的分页写入磁盘。当内存的容量不够操作系统使用的时候,这个过程就会发生。当操作系统需要已经被交换出去的分页时,这些分页将再被再次加载回内存以供使用。交换是成本很高的操作,应该尽量避免。
ES在内存中保留了很多运行时必需的数据和缓存,如图3所示,所以消耗资源的磁盘读写操作将严重地影响正在运行的集群。鉴于这个原因,关闭交换可能获得更好的性能。
 图3 ES将运行时的数据和缓存都存放在内存中,因此分页引起的读写操作可能是昂贵的
图3 ES将运行时的数据和缓存都存放在内存中,因此分页引起的读写操作可能是昂贵的
关闭ES交换最彻底的方法方法是,在elasticsearch.yml文件中将bootstrap.mlockall设置为true。可以检查警告日志或者是查询一个活动状态,验证设置是否生效。
curl -X GET "172.16.1.127:9200/_nodes/stats/os,process?pretty"如果警告日志中出现'Unknown mlockall error 0',或者是状态检查的结果中mlockall被设置成了false,那么关闭交换的设置还未生效。运行ES的用户没有足够的访问权限,是新设置没有生效的最常见原因。通常以root用户运行ulimit -l unlimited可以解决这个问题。为了这些新设置能生效,还需要重启ES。
4. 操作系统缓存
由于Lucene不可变的分段,ES和Lucene很大程度上使用了操作系统的文件缓存。Lucene利用底层的操作系统文件缓存来构建内存里的数据结构。最佳实践会将经常使用的索引存放在更快的机器上。为了实现这个目标,需要使用路由将具体的索引分配到更快的节点上。
首先,需要为全部节点分配一个特定的tag,每个节点的tag是唯一的,如node.tag.mynode1或node.tag.mynode2。使用节点的单独设置,可以只在拥有指定tag值的节点上创建索引。这样做的意义在于确保新的、繁忙的索引只会在拥有更多非堆内存的节点上创建,Lucene也可以充分利用这些内存。为了达到这个目的,使用下面的命令,这样新索引只会在tag值为mynode1和mynode2的节点上创建。
curl -X PUT "172.16.1.127:9200/myindex/_settings?pretty" -H "Content-Type: application/json" -d '
{
"index.routing.allocation.include.tag": "mynode1,mynode2"
}'5. 存储限流
尽管分段合并操作通常不会对于系统有很大的影响,当合并、索引和搜索操作同时发生时,I/O很低的系统仍然会受到负面影响。用户可以设置节点级别或索引级别的限流。节点级别的限流通过indices.store.throre.throttle.type属性设置,可能的值有node、merge和all。值merge告诉ES对整个节点上的合并操作进行I/O限流,包括节点上的每个分片。而值all将限流的限制实施在节点所有分片的所有操作之上。索引级别的限流配置方法类似,不过是使用index.store.throttle.type属性。此外,索引级别的设置也允许值为node,这样的话它也会将限流设置运用在整个节点上。
无论节点还是索引级别,ES都提供了相应的属性来设置I/O所能使用的每秒最大字节数。对于节点的限流,使用 indices.store.throttle.max_bytes_per_sec,索引级别的限流使用index.store.throttle.max_bytes_per_sec。这些值的单位是兆字节每秒。
五、备份与恢复
ES提供了一个功能全面、增量型的数据备份方案。快照和恢复API可以将每个索引数据、全部索引甚至是集群的设置备份到远端的资料库或是可插拔的后端系统,然后很容易地将这些内容恢复到现有的集群或新集群。
1. 快照API
首次使用快照API备份数据时,ES将复制集群的状态和数据。所有后续的快照将包含前一个版本之后的修改。快照的进程是非阻塞的,所以在运行的系统上执行快照应该不会对性能产生明显的影响。此外,由于每个后续快照都是基于之前快照的差量,随着时间的推移它将进行更小、更快的快照。快照存储在资料库中,资料库可以定义为文件系统或者是URL。
- 文件系统的资料库需要一个共享的文件系统,而且该共享文件系统必须安装在集群的每个节点上。
- URL的资料库是只读的,可以作为替代的快照存储方案。
2. 将数据备份到共享的文件系统
进行集群备份需要执行以下3个步骤:
- 定义一个资料库:告诉ES想如何构建资料库。
- 确认资料库的存在:需要验证资料库已经按照定义被创建成功。
- 执行备份:首个快照是通过一个简单的REST API命令来执行的。
下面演示将ES一个备份到hdfs上的例子,前提要在ES集群的所有节点上安装ES的hdfs插件,然后重启ES集群使该插件自动加载。
# 在集群所有节点上安装ES的hdfs插件
~/elasticsearch-6.4.3/bin/elasticsearch-plugin install repository-hdfs
# 重启ES集群
jps | grep Elasticsearch | awk '{print $1}' |xargs kill
~/elasticsearch-6.4.3/bin/elasticsearch -d开启快照的首个步骤,需要定义一个共享的文件系统资料库。下面的代码在hdfs上创建了一个名为my_repository的资料库。
curl -X PUT "172.16.1.127:9200/_snapshot/my_repository?pretty" -H "Content-Type: application/json" -d '
{
"type": "hdfs",
"settings": {
"uri": "hdfs://172.16.1.127:8020/",
"path": "/tmp/elasticsearch",
"conf.dfs.client.read.shortcircuit": "false"
}
}'一旦完成了集群资料库的定义,就可以使用一个简单的GET命令来确定其存在。
curl -X GET "172.16.1.127:9200/_snapshot/my_repository?pretty"不指定资料库名称时,ES将返回集群中所有已经注册的资料库。
curl -X GET "172.16.1.127:9200/_snapshot?pretty"验证快照节点:
curl -X POST "172.16.1.127:9200/_snapshot/my_repository/_verify?pretty"建立资料库后,下一步是创建初始的快照/备份。
curl -X PUT "172.16.1.127:9200/_snapshot/my_repository/first_snapshot?pretty&wait_for_completion"等待该命令执行完成,可以查看资料库所在的位置,看看快照命令都存储了哪些内容。
[hdfs@hdp2~]$hdfs dfs -ls /tmp/elasticsearch/
Found 5 items
-rw-r--r-- 1 elasticsearch hdfs 440 2019-02-22 14:10 /tmp/elasticsearch/index-0
-rw-r--r-- 1 elasticsearch hdfs 8 2019-02-22 14:10 /tmp/elasticsearch/index.latest
drwxr-xr-x - elasticsearch hdfs 0 2019-02-22 14:10 /tmp/elasticsearch/indices
-rw-r--r-- 1 elasticsearch hdfs 20854 2019-02-22 14:10 /tmp/elasticsearch/meta-u8nd4w7aRs6AeY0JR9HJ-A.dat
-rw-r--r-- 1 elasticsearch hdfs 293 2019-02-22 14:10 /tmp/elasticsearch/snap-u8nd4w7aRs6AeY0JR9HJ-A.dat
[hdfs@hdp2~]$这个快照包含了集群中的每个索引、分片、分段以及相关元数据的信息,存放的路径结构为:/<索引ID>/<分片ID>/<分段ID>。
因为快照是增量的,只存储两次快照之间的差量,所以第二次快照命令会创建更多的几个数据文件,但是不会从头开始创建整个快照。
curl -X PUT "172.16.1.127:9200/_snapshot/my_repository/second_snapshot?pretty&wait_for_completion"第二次执行后生成了4个新文件:
[hdfs@hdp2~]$hdfs dfs -ls /tmp/elasticsearch/
Found 9 items
-rw-r--r-- 1 elasticsearch hdfs 29 2019-02-22 14:25 /tmp/elasticsearch/incompatible-snapshots
-rw-r--r-- 1 elasticsearch hdfs 440 2019-02-22 14:10 /tmp/elasticsearch/index-0
-rw-r--r-- 1 elasticsearch hdfs 609 2019-02-22 14:25 /tmp/elasticsearch/index-1
-rw-r--r-- 1 elasticsearch hdfs 8 2019-02-22 14:25 /tmp/elasticsearch/index.latest
drwxr-xr-x - elasticsearch hdfs 0 2019-02-22 14:10 /tmp/elasticsearch/indices
-rw-r--r-- 1 elasticsearch hdfs 20854 2019-02-22 14:10 /tmp/elasticsearch/meta-u8nd4w7aRs6AeY0JR9HJ-A.dat
-rw-r--r-- 1 elasticsearch hdfs 20854 2019-02-22 14:25 /tmp/elasticsearch/meta-xBxBjLAxQlSJ_-qP36ptNA.dat
-rw-r--r-- 1 elasticsearch hdfs 293 2019-02-22 14:10 /tmp/elasticsearch/snap-u8nd4w7aRs6AeY0JR9HJ-A.dat
-rw-r--r-- 1 elasticsearch hdfs 294 2019-02-22 14:25 /tmp/elasticsearch/snap-xBxBjLAxQlSJ_-qP36ptNA.dat
[hdfs@hdp2~]$可以按照每个索引为单位进行快照,需要在PUT命令中设置索引参数。
curl -X PUT "172.16.1.127:9200/_snapshot/my_repository/third_snapshot?pretty&wait_for_completion" -H 'Content-Type: application/json' -d '
{
"indices": "get-together,bank"
}'向同样的端点发送一个GET请求,可以获得给定快照(或全部快照)状态的基本信息。
curl -X GET "172.16.1.127:9200/_snapshot/my_repository/first_snapshot?pretty"
curl -X GET "172.16.1.127:9200/_snapshot/my_repository/second_snapshot?pretty"
curl -X GET "172.16.1.127:9200/_snapshot/my_repository/third_snapshot?pretty"
curl -X GET "172.16.1.127:9200/_snapshot/my_repository/_all?pretty"由于快照是增量的,因此当删除不再需要的旧快照时,必须非常谨慎。建议使用快照API来删除旧的快照,因为API只会删除现在不用的数据分段。
curl -X DELETE "172.16.1.127:9200/_snapshot/my_repository/first_snapshot?pretty"3. 从备份中恢复
快照可以很容易地恢复到任何运行中的集群,甚至并非生产这个快照的集群。使用快照API的时候加入_restore命令,将恢复这个集群状态。
curl -X POST "172.16.1.127:9200/_snapshot/my_repository/second_snapshot/_restore?pretty"这个命令将恢复指定快照,second_snapshot中的集群数据和状态。通过这个操作,可以很容易地将集群恢复到用户所选的任何时间点。
和快照操作类似,恢复操作允许设置wait_for_completion旗标,它将阻塞用户的HTTP请求直到恢复操作完全结束。默认地,恢复HTTP请求是立即返回的,然后操作是在后台运行。
curl -X POST "172.16.1.127:9200/_snapshot/my_repository/second_snapshot/_restore?wait_for_completion=true&pretty"恢复操作还有额外的选项,允许用户将某个索引恢复到新命名的索引空间。当复制一个索引,或者验证某个恢复索引的内容时,这一点很有帮助。
curl -X POST "172.16.1.127:9200/_snapshot/my_repository/second_snapshot/_restore?wait_for_completion=true&pretty" -H "Content-Type: application/json" -d '
{
"indices": "get-together",
"rename_pattern": "get-together",
"rename_replacement": "get-together-bak"
}'这个命令只恢复名为get-together的索引,而忽略快照中任何其它的索引。由于索引的名称和用户定义的rename_pattern模式相匹配,快照数据将存放于一个名为get-together-bak的新索引中。
注意,当恢复现有索引时,运行中的索引实例必须是关闭的,恢复操作完成之后,它会打开这个关闭的索引。